2022. 12. 7. 02:33ㆍ카테고리 없음
File System Implementation/File System Internals
파일 시스템의 내부 구조
개요
디스크 스페이스의 관리 및 성능을 좋게하는 매커니즘, 신뢰성(reliability)이 어떻게 되는가가 중요하다.

파일 시스템의 구현
(1) In-memory structure
운영체제가 부팅돼서 프로세스가 파일을 액세스하는 형태
운영체제가 수행되는 동안 어떻게 어플리케이션 프로세스에게 파일 시스템에 있는 것을 제공할 수 있는 가.

어플리케이션 프로세스가 open했을 경우, read를 했을 경우 어떻게 동작하는지 설명하는 자료이다. In memory structure는 프로세스 내에서는 프로세스가 파일을 오픈할 때마다 파일 디스크립터 엔트리가 하나씩 생겨난다.(이는 각 파일에 해당되어 관리된다.) 파일 디스크립터 엔트리는 커널에 시스템 와이드한 오픈 파일 테이블(시스템 전체적으로 관리된다.)에 저장된다. 각 프로세스는 시스템 와이드한 오픈 파일 테이블의 정보를 포인터로 가리키는 식으로 진행된다.
만약 한 프로세스에서 파일을 열어서 정보를 수정한다면 오픈 파일 테이블의 정보를 엑세스해야한다.

유닉스/리눅스 프로세스는 생성되면 무조건 파일을 세개 오픈한다 따라서 0 ~ 2번까지의 인덱스에는 이미 가리키는 포인터가 있게 된다. 따라서 프로세스의 file descriptor table의 0 ~ 2번째 인덱스에는 포인터를 표시하지 않았다.
0번 파일: 스탠다드 인풋, 1번 파일: 스탠다드 아웃풋, 2번 파일: 스탠다드 에러이다.
0번으로 입력을 받고, 1번으로 쓰면 레귤러 파일이 아니라 콘솔 모니터에 출력되게 된다.
이후 파일을 오픈하면 3번이 오픈되고 이는 파일 디스크립터라고 한다. 유닉스/리눅스는 파일이라는 개념으로 I/O를 사용하기 떄문에 그러하다.
오른쪽의 초록색은 메인 메모리에 존재하는 데이터 스트럭처이다.
디렉토리 캐시와 버퍼 캐시를 합해서 Buffer cache라고도 한다. 버퍼캐시는 캐시이기에 하드디스크에 존재하는 파일 시스템 내에 있는 파일 중 자주 쓰는 것을 메인메모리에 두고 사용한다. 버퍼 캐시 중 디렉토리 데이터를 캐시하는 것이 디렉토리 캐시, 파일을 캐시하는 것이 버퍼 캐시라고 표현한다. 이를 통해 성능을 개선한다.
Virtual File System
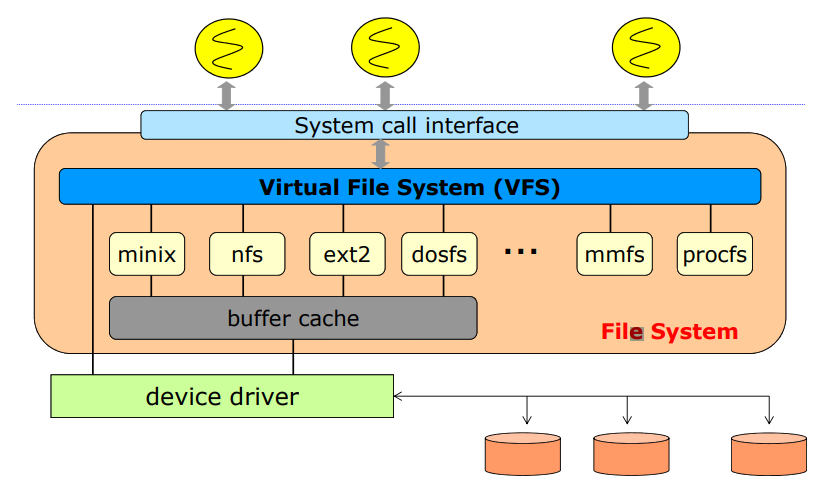
리눅스를 만들면서 나온 개념이다. 리눅스를 만들려고 보니까 파일 시스템이 너무 많았다. 도스/윈도우즈 등이 사용하는 파일 시스템도 있었다. 따라서 지원해야하는 파일 시스템이 너무 많았다. 하지만 파일시스템들 간에 공통된 부분도 많았기에 이를 virtual file system이라는 레이어로 만들어서 처리했고, 파일시스템별로 살짝 다른 부분을 추가해서 처리했다. 파일시스템이 추가될 때마다 쉽게 추가할 수 있도록 했다.
layerd file system

레이어를 두고 처리하는 것이다. 오른쪽에 있는 내용은 파일 시스템의 종류를 의미한다.
파일 시스템의 종류
CD ROM은 read에 대한 데이터를 저장한다. 이는 운영체제에 종속되어있다.
유닉스 운영체제에서는 UFS(유닉스 파일 시스템), FFS(패스트 파일 시스템)이라는 이름으로 파일시스템을 사용한다.
윈도우 운영체제에서는 FAT(16비트 인텔 cpu에서 동작), FAT32(usb에서 많이 사용, 신뢰도 문제가 있음), NTFS(windowsNT File System, 지금 사용)라는 이름으로 파일시스템을 사용한다.
리눅스 운영체제에서는 다른 파일 시스템과 호환이 되게 해야하기에 매우 많다. 리눅스 특유의 파일 시스템을 각각 ext2/3/4라고 한다. 분산 시스템에서도 ZFS, GoogleFS, Oracle ASM, FUSE 등 빅데이터와 관련된 파일 시스템을 사용한다.
임베디드 시스템에서는 파일 시스템의 용량을 신경쓰기 보단 파일 시스템이 무조건 있어야한다는 특징이 있다. 낸드 플래시에 기반한 이를 파일 시스템으로 사용하는 경우가 존재한다. 따라서 플래시 메모리에 존재하는 파일 시스템도 있다.
(2) On-disk structure

전원이 꺼져도 디스크에 존재하는 데이터가 어떻게 관리되는 것인가.
FCB는 파일 하나를 만들 때 그 파일에 대한 메타 데이터를 의미한다.
각각 운영체제마다 구조는 비슷하지만 이름을 다르게 표현해서 사용한다.
하드디스크 기반으로 설명이 나온다. 하지만 ssd와 큰 차이는 없다. ext4라는 파일 시스템이 설치되는 환경에 따라 윗 레이어에는 큰 차이가 없다.
디스크 드라이브의 첫 섹터에는 ESP와 같은 부트 로더와 파티션 테이블 존재한다.
첫 파티션에는 우측에 있는 블럭과 같은 구조로 이뤄져있다. 윈도우즈의 NTFS도 이와 유사하다.
파일 시스템 전체의 관리를 위한 영역
boot block: 부트가 가능한 active 파티션은 부트가 저장된 부트 블럭이 있다.
super block: 파일 시스템 메타 데이터가 저장된다. 여기에 파일 시스템에 존재하는 블럭 개수(이는 파일 시스템의 크기를 결정한다.) 등이 저장된다. 운영체제는 블럭단위로 파일을 관리한다.
bitmaps block: 프리 스페이스를 관리하기 위한 데이터 스트럭쳐이다. 사용하지 않는 공간에 write 하기위해 필요하다. 즉, 사용하는지 사용하지 않는지를 파악할 수 있도록 도와준다.
각 파일을 관리하기 위한 영역
i-nodes: 파일 컨트롤 블록이라고 부른다. 파일에 대한 메타데이터를 저장하는 FCB와 동일하다.
root dir: 포멧을 하면 루트 디렉토리라는 하나의 파일이 존재하게 된다. 따라서 첫번째 데이터는 루트 디렉토리가 된다. 이 밑에서 데이터가 저장된다. 윈도우즈에서는 format이라는 이름으로 파일 시스템을 만들 수 있다. 유닉스/리눅스에서는 mkfs라는 이름으로 파일 시스템을 만들 수 있다. 루트 디렉토리에 어떤 파일이 저장되어있는지는 디렉토리 데이터(아마 files & directories)에 저장되어있다. 포멧을 하면 뒤에 있는 루트 dir만 남고 뒤에는 데이터가 저장되지 않는다.
1테라 공간을 샀다고 해서 1테라를 모두 사용할 수 없는 이유는 boot block을 비롯한 다양한 블록이 먼저 자리를 차지고 있기 때문이다.
Disk block

super block에 파일 시스템에 대한 메타 데이터(ntfs냐, FAT이냐 등등)가 저장된다. 여기서 블럭 개수도 저장한다. 운영체제에서는 데이터를 관리할 때 디스크 블럭 넘버라는 숫자로 이를 관리한다. 그래서 디스크 블럭과 넘버 간의 매핑을 관리할 수 있게 된다. 파일 시스템에서 관리하는 단위는 디스크 블럭의 번호로 관리하게 된다. 디스크 블럭의 크기를 얼마로 할지 정하는 것이 중요하다. 페이지와 비슷하게 4kb를 많이 사용한다.
만약 4GB 하드디스크를 사용한다면 디스크 블럭의 개수는 1메가개가 된다. 디스크 블럭이라고 하는 단위로 파일 시스템을 관리한다.
free space management
(a) bit map 사용

이를 담당하는 것이 bit map block이다.
free space를 표현하는 방법으로는 bit map으로 관리하는 방법이 있다. 이는 디스크 블럭이 사용중이다 사용중이지 않다는 것을 판단하기 위해서 bit vector라고 표현하기도 한다. 하지만 일반적으로 bit vector가 아닌 bit map으로 표현한다.
디스크 블럭 당 한 비트만 있으면 되기에 2의 18 비트가 필요하게 되고, 이를 바이트로 표현하면 32k byte가 된다.
(b) Linked list 사용

링크드 리스트로 관리하는 방법이 존재한다. 하지만 하드 디스크에서 이를 사용해야하는데, 만약 디스크 블럭이 고장나면 뒤에는 다 읽을 수 없게 된다. 따라서 이는 잘 사용되지 않는다. 대신 bit map block을 사용한다.
ZFS와 같이 분산 처리 파일 시스템에서는 space map과 같은 방법을 사용하기도 한다.
A Typical File Control Block

파일이 생기면 그 파일에 대한 메타데이터를 저장한다. 이를 유닉스/리눅스에선 i-nodes, NTFS에선 master file table이라 한다.
Directory Implementation

디렉토리 데이터, 디렉토리 내에 어떤 파일이 있는지를 저장한다. 즉, 저장된 파일의 이름과 파일의 메타데이터인 FCB가 저장되어야한다.
(a) In the directory entry
우선 FCB를 모두 저장하는 방법이 있다.
(b) In the separate data structure
두번째로는 디렉토리 데이터에는 파일 이름과 그 파일의 i-node가 있는 위치만 저장하는 형태가 있다. 유닉스/리눅스가 이 방법을 사용한다.
(c) A hybrid approach
세번째로는 이것들의 중간 방법이 있다. 중요한 정보만 저장한다. 이는 윈도우즈가 채택하고 있는 방법이다. 해당 파일까지 가지 않아도 해당 파일 내에서 중요한 정보를 따로 저장한다. 이에 따라 디렉토리에서도 파일이 언제 수정됐는지 등에 대한 정보를 알 수 있게 된다.
Allocation Methods
파일에 대한 정보는 FCB에 저장된다. 언제 저장됐는지 등도 중요하지만 가장 중요한 것은 파일의 데이터가 어디에 저장되었는지를 아는 것이 제일 중요하다. 예를 들어 파일 사이즈가 40kb면 디스크 블록은 10개 필요하게 된다. 그러면 그 디스크 블럭 10개가 어디에 어떻게 저장되어있는지를 알고 있어야한다. 만약 파일 사이즈가 더욱 커지게 되면 관리해야하는 블럭 개수가 매우 늘어나게 된다. 따라서 이를 잘 표현하는 것이 주요한 이슈이다. 이를 배치하는 방법이 아래의 세가지 방법이 있다.
(1) Contiguous allocation
파일 사이즈에 맞게 블럭을 연속적으로 배치한다. 이는 디스크 블럭을 어떻게 배치하는지에 달려있다. 만약 1000개의 디스크 블럭을 배치해야한다면 이를 연속적으로 배치한다.

일단 In the directory entry의 형태로 데이터가 저장된 것으로 가정하고 있다.

이는 가장 쉬운 방법이다. 하지만 tr의 경우 파일의 크기가 커지면 연속적으로 비어있는 공간에 옮겨야한다는 단점이 있다. External fragmentation도 발생한다. 따라서 이를 잘 사용하지는 않는다. 또한 파일이 자주 생기거나 삭제가 되는 경우에는 이런 방식으로 사용하는 것이 안좋지만 CD와 같이 읽기 전용으로 만들어진 경우에는 이 방법을 사용하는 경우가 많다.
따라서 이를 불연속적으로 배치하여 위의 문제를 해결할 수 있게 할 수 있다. 이러한 방법이 Linked allocation이다.
(2) Linked allocation

하지만 이러한 경우에는 디스크 블럭을 모두 사용할 수 없고, 다음번 디스크 블럭의 번호를 저장해야한다.

이 방법의 장점은 파일이 자유자재로 커졌다가 줄어들 수 있다는 장점이 있다. 또한 FCB에 어디에 저장되어있는지 표기하기 쉽다는 장점이 있다.
하지만 중간에 데이터가 하나 날라간다면 뒷쪽에 있는 것을 사용할 수 없다는 큰 단점이 있다. 하드웨어의 경우에는 전원이 꺼진다면 파일이 손상될 수 있기에 신뢰도의 문제에서 큰 문제가 있다. 또한 포인터 유지에 따른 오버헤드가 있다는 두번째 단점이 있다. 그리고 일반적으로는 데이터는 앞에서부터 쭉 읽지만 그게 아니라 랜덤 액세스가 필요한 데이터가 있을 수 있다. 하지만 이는 랜덤액세스가 불가능하고, 중간 데이터를 찾는데 매우 많이 시간이 소요된다.
이를 보완하기 위한 방식으로 FAT가 등장했다.
(2-2) File-Allocation Table
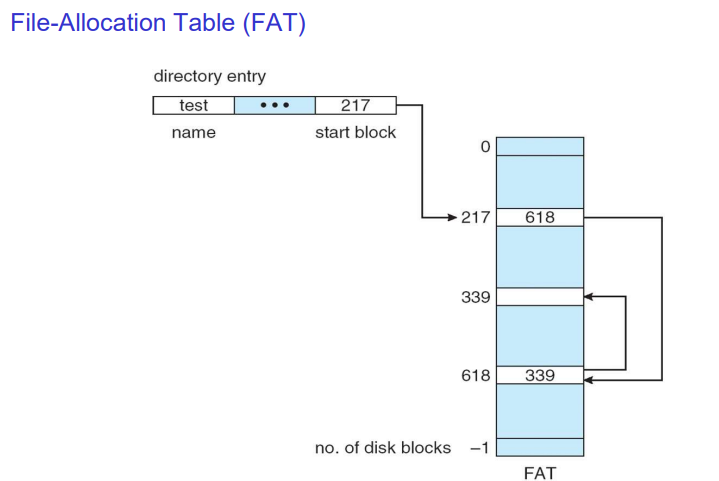
디스크 블럭에 다음 정보를 저장하는 것이 아니라 별도 테이블에서 다음 정보를 가리키도록 하는 방법이다. FAT 16은 디스크 블럭을 표현하기 위한 크기가 16비트인 것을 의미한다. 도스 시절에 이를 사용했다. 지금은 FAT 32로 윈도우즈에서 쓰다가 NTFS로 바꿔서 사용한다. 하지만 USB에서는 이러한 방식을 아직 많이 사용한다.
신뢰도를 위해 위의 데이터를 모아놨지만 아직도 신뢰도가 낮다. 이에 따라 2중, 3중으로 이를 처리하기에 신뢰도를 높이고자 한다. 하지만 신뢰도가 100% 보장되는 것은 아니다.
FAT을 사용하는 경우에는 크기가 크지 않아서 이를 메인메모리에 올릴 수 있다. 이에 따라 랜덤액세스를 하는데 Linked 방식보단 더 빠르다.
(3) Indexed allocation

이 파일이 어디에 있는지를 FCB에 모두 저장한다. 이를 별도의 디스크 블럭에 저장한다. 이를 순차적으로 저장하여 관리한다. i node는 index node를 줄인 것이고, 이를 인덱스의 형태로 저장한다.

이를 사용하면 FAT의 단점인 신뢰도가 더 좋아진다는 장점이 있다. 또한 랜덤 액세스 측면에서도 더 좋아진다.
그런데 블럭을 매우 많이 사용하게 되는 경우에는 이를 어떻게 저장해야하는 지에 대한 이슈가 생길 수 있다.
i node(파일 컨트롤 블록)
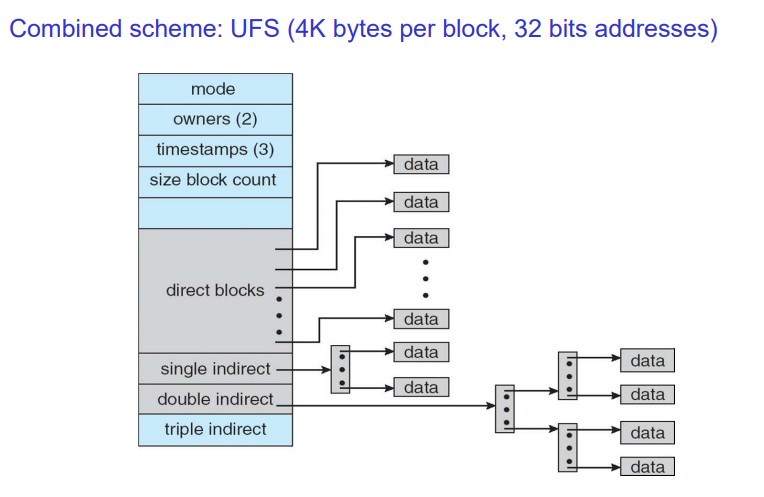
다이렉트 블럭을 최대 12개까지 직접 사용한다. 디스크 블럭이 4K니까 파일 사이즈가 48KB만큼은 커버가 가능하게 된다. 만약 이를 넘어가게되면 single indirect 블럭을 사용한다. 32비트 integer 값은 4바이트이고, 이에 따라 1K개(1024)를 표현할 수 있게 된다. 각 포인터는 block을 가리키기에 이를 계산해보면, 1K x 4K = 총 4MB까지 이를 표현할 수 있다. 만약 파일 사이즈가 이보다 더 크게 된다면 double indirect를 사용한다. 이 경우에는 4MB가 1K개 있는 것이기에 4GB, triple은 4TB를 표현할 수 있게 된다.
UFS structure

i-node 뒤에 있는 숫자는 디스크 블럭 번호를 의미한다. 즉 메모리 주소와 같이 생각하면 된다. 파란색은 i-node, 노란색은 디렉토리 데이터를 의미한다.
a.out은 디폴트 실행파일을 의미한다. 제일 처음에 root부터 쫒아간다. 즉, root의 i node를 본다. 이는 0번 디스크 블럭에 저장된다. 이후 이는 루트의 디스크 블럭을 읽는다. 디렉토리인 경우에는 파일 이름, 파일에 대한 i-node 디스크 번호를 가지게 된다. .은 current directory, ..은 parent directory를 저장한다.
500번에는 a.out이라는 디스크 블럭이 있다. 650은 single indirect block, 그 위에 있는 것은 direct block이다.
a.out을 실행시키기 위해 500번재 i node에 있는 것을 모두 순차적으로 실행해야한다. 그런데 이를 실행시키기 위해 아주 많은 디스크 블럭을 읽어야한다. 즉, 파일을 하나 새로 만들고 카피한다는 것은 사용되지 않은 디스크 블럭을 옮기는 작업을 해야한다.
만약 ls와 같은 명령어를 입력하는 경우에는 읽어야하는 디스크 블럭이 매우 많게 된다. 따라서 이를 최적화해야하는데 캐시를 사용해서 최적화를 한다. 기본적으로 디스크 블록은 하드 디스크에 있지만 처음 ls를 입력한 이후에 이를 메인 메모리에 가져다놓는다.
블럭 사이즈와 성능의 상관관계

y축은 성능, x축은 디스크 블럭 사이즈를 의미한다. 디스크 블럭의 사이즈가 커지면 성능이 높아진다. 디스크는 seek 시간이 매우 오래 소요되기에 한번 읽을 때 많이 읽는 것이 중요하기에 디스크 블럭의 사이즈가 커지면 성능이 높아진다.
하지만 디스크 이용률 입장에서 바라보면 디스크 블럭 사이즈가 매우 커지게 되면 좋지는 않다. 이를테면 'a' 하나만 입력한 메모장을 저장한다면 1/4K만큼의 디스크만 이용하게 되는 건데, 이를 무작정 키우면 이용률이 더욱 떨어지게 된다. 나머지는 더미 데이터가 들어가게 된다. 이에 따라 internal fragmentation이 발생하게 된다. 디스크 블럭 사이즈가 커지면 internal fragmentation이 더욱 커지게 된다. 이는 trade off 관계가 발생하게 된다.
SSD로 가게 되면 모두 전기적으로 있기 때문에 블록 사이즈가 커지더라도 성능이 좋아지진 않기에 disk space utilzation만 고려하면 된다. 따라서 더 최적으로 둘 수 있다.
Read Ahead

시퀀셜한 데이터인 경우에는 100번을 읽으면 101번을 읽을 가능성이 높기에 이를 미리 읽어둔다. 이는 HDD를 고려한 성능 최적화 방법이다.
Buffer Cache

HDD에서 자주 사용하는 것을 HDD에서 읽지 않고, 메인 메모리에서 읽는다. 버퍼 캐시를 4메가 바이트만 달더라도 성능이 매우 효과적이다. SSD는 이정도록 극적으로 좋아지진 않는다.

메모리 read, write을 할 때 실제 파일에서 데이터를 읽는다. 이때 page cache를 거치게 되는데 이 둘을 합쳐서 사용하는 것을 의미한다.
버퍼 캐시의 문제

read는 성능이 좋다. 하지만 write의 경우에는 asynchronous write하는 이슈가 발생하게 된다. write를 하다가 한번에 모아서 이를 사용하는 방법이다. 이는 write back을 하는 방식을 의미한다. 이는 unreliable하다는 단점이 있다.
이 문제를 해결하는 방법

비정상적인 것을 정상적인 것으로 복구하는 프로그램을 fsck라고 한다. 이를 체크해서 바로잡는다.
요즘에는 이를 사용하지 않아도 많이 좋아졌다. 그 이유는 Log structured file system 때문이다.

요즘에는 Journaling file system이라는 용어를 더 많이 사용한다.

버퍼 캐시의 write때문에 발생하는 문제를 해결할 수 있다. 모았다가 한번에 처리가능하긴 하지만 어떤 연산이 수행되었는지를 journal에 write한다. 이후 한번에 디스크에 write할 때 journal에 있는 것을 지운다. 정상적으로 종료가 된 경우에는 journal에 아무것도 없게 되지만 문제가 있다면 journal에만 데이터가 남게 된다. 이는 비정상적인 상황이기에 이를 정상적인 상황으로 복구한다. 이를 통해 복구하는 형태가 journaling file system이 되고 이를 실질적으로 많이 사용한다.
Remote File System

네트워크로 연결된 컴퓨터의 파일 시스템을 내가 사용하는 파일 시스템처럼 여긴다.
리눅스 유닉스에서는 NFS라고 한다. 여기서는 virtual file system이 존재한다. 이를 위해 공통적인 거를 VFS interface를 두고, 파일 시스템에 맞춰서 상속받아서 사용한다. NFS client가 실행되는데 RPC의 매커니즘에 의해 다른 컴퓨터의 코드를 실행한다.