2023. 9. 17. 20:38ㆍ자바
이번에는 `자바 쓰레드 풀`에 관해 글을 작성해보려고 합니다!
정확히 말하면 자바에서 쓰레드 풀이 어떤 식으로 구현되어있는지, 그리고 각각 쓰레드 풀 유형에 대해 알아볼 예정입니다.
쓰레드 풀이란?
쓰레드 풀이란 여러 쓰레드를 사전에 만들어 둔 Pool이라고 생각하면 됩니다.
일반적으로 개발에서의 Pool이라는 용어는 어떤 대상들을 생성한 뒤 놔두는 공간이라고 해석할 수 있는데요. 자바에서의 `스트링 풀`은 `문자열들을 생성한 뒤 놔두는 공간`, `쓰레드 풀`은 `쓰레드들을 생성한 뒤 놔두는 공간`으로 풀이해볼 수 있어요!
위와 같이 Pool을 만들어두는 이유는 비용 때문이라고 요약해볼 수 있어요.
한번 생성할 때의 비용이 비싸지만 자주 사용하는 경우엔
이를 매번 생성해서 사용하기보단 한번 생성한 것을 재활용할 수 있으면 재활용하는 것이 더 이득이기 때문에 이러한 것들을 Pool로 만들어서 관리해요.
그렇다면 여러 쓰레드를 반복적으로 많이 사용하는 경우에 쓰레드 풀을 만들어서 사용한다고 풀이해볼 수 있겠네요! 우리 주변에서는 이러한 서비스를 확인할 수 있습니다.
바로 웹 서버죠!
웹서버는 클라이언트의 요청 하나마다 쓰레드를 하나씩 할당해서 요청에 대한 응답을 처리하기 때문에 쓰레드 풀을 잘 활용하는 것이 중요합니다.
자바에서의 쓰레드 풀
자바에서 쓰레드 풀을 구현하기 위해 다양한 인터페이스를 정의하고 있는데요.

바로 코드로 확인해보겠습니다.
(1) Executor

가장 상위의 인터페이스로는 Executor가 존재합니다. 이는 Runnable 인터페이스를 구현한 어떤 객체를 전달받아서 이를 실행하는 역할을 합니다.
(2) ExecutorService

다음으로는 ExecutorService 입니다.
이는 Executor를 상속받고 있는 인터페이스입니다.
그래서 단순히 실행하는 것을 넘어서 쓰레드들을 관리하는 기능을 담당한다고 생각하시면 됩니다!
쓰레드들에게 작업을 등록하거나, 실행하는 책임을 가진다고 보시면 됩니다.
또한 위에서 보시는 것과 같이 작업을 멈추는 동작도 정의하고 있어요.
그리고 여기서 중요한 점은 쓰레드를 실행했을 때 실행 결과인 Future를 반환한다는 점이에요.
이 덕분에 비동기적으로 작업의 수행 여부를 추적할 수 있어요.


위와 같이 쓰레드에서 동작할 내용들을 전달하면 쓰레드에게 이 작업을 전달해서 쓰레드가 일합니다!

(일해라 쓰레드야~)
(3) ThreadPoolExecutor

오늘 중점적으로 살펴볼 친구입니다!
해당 클래스의 객체를 생성해서 사용하면 비로소 쓰레드 풀을 사용할 수 있어요.
일반적으로 쓰레드 풀을 세세하게 다루는 것은 다소 어렵기 때문에, Executors 클래스의 정적 팩토리 메소드로 이를 구현해서 사용합니다. 여기에서 사용하는 주 필드명들은 아래에서 설명하도록 하겠습니다.
Executors

(1) newFixedThreadPool

이름에서 바로 알 수 있듯이 쓰레드의 개수를 아예 고정하고 사용하는 쓰레드 풀이라고 생각하시면 됩니다.
ThreadPoolExecutor 내부 클래스를 보시면 동적으로 쓰레드의 개수를 증가시키거나 줄일 수 있습니다.


생성자 내부에서 확인해보면 corePoolSize, maximumPoolSize를 전달받고 있는 것을 확인할 수 있죠. 여기서 corePoolSize는 ThreadPool 내에서 유지할 최소 쓰레드의 개수라고 생각하시면 돼요. maximumPoolSize는 ThreadPool 내에서 생성할 수 있는 Thread의 최대 개수라고 생각하시면 됩니다.
cf) corePoolSize를 설정했더라도 계속 사용하지 않는 경우에는 쓰레드 낭비가 있을 수 있습니다. 이러한 경우에는 allowCoreThreadTimeOut을 true로 설정해서 corePoolSize보다 적게 thread를 유지할 수 있습니다.
기왕 용어가 나온 김에 몇 가지 더 설명해보도록 할게요.
KeepAliveTime은 쓰레드가 아무 동작도 하지 않을 때(Idle) 얼마 동안 풀에서 놔둘 것이냐를 의미한 것으로 보시면 됩니다. 0으로 설정하시면 쓰레드는 주어진 동작을 수행하고 바로 해제되겠죠.
물론 이때에도 allowCoreThreadTimeOut을 따로 true로 설정하지 않는 이상 쓰레드의 개수는 최소한 corePoolSize 만큼 유지한다는 사실에 유의해주세요.
Unit은 KeepAliveTime의 시간 단위라고 생각하시면 됩니다.
workQueue는 Runnable 인터페이스를 구현한 어떤 작업들을 쓰레드에 할당하기 전에 대기시켜놓는 큐라고 생각하시면 됩니다.

여러 작업이 있을 때 작업을 순차적으로 쓰레드에 할당을 해줍니다. 이때 대기시켜놓는 공간이라고 생각하시면 돼요.
이제 쓰레드 풀에서 사용하는 용어에 대해 배웠으니 다시 돌아와볼까요.
newFixedThreadPool은 nThreads를 전달받고 있죠. 그리고 그 만큼 corePoolSize와 maximumPoolSize를 설정하고 있습니다. keepAliveTime은 0이군요. 어차피 corePoolSize가 쓰레드 풀에서 생성될 수 있는 쓰레드 개수랑 같기에 항상 쓰레드 유지되기 때문입니다. 그리고 위에서 본 것처럼 LinkedBlockingQueue를 전달해서 workQueue를 대기시키고 있습니다. 그래서 maximumPoolSize 이상의 요청이 들어오면 해당 큐에 요청을 대기시킵니다.
요약해보자면 다음과 같습니다.
- corePoolSize == maximumPoolSize == 파라미터로 전달한 쓰레드 개수
- keepAliveTime = 0
corePoolSize가 쓰레드 풀 내의 최대 쓰레드 개수와 같기 때문에 쓰레드 풀에서 쓰레드가 해제되지 않고, 고정된 쓰레드 개수로 사용한다고 하여 newFixedThreadPool이라는 이름이 붙었다는 것을 유추해볼 수 있겠네요.
(2) newCachedThreadPool


corePoolSize는 0, maximunPoolSize는 최대 정수 값, keepAliveTime은 60초네요!
즉, 처음 쓰레드 풀을 생성했을 때에는 쓰레드를 가지고 있지 않고, 요청이 들어올 때마다 쓰레드를 하나씩 생성해가며 쓰레드 풀에 가져다 놓는다는 것을 알 수 있는데요. 60초 동안 일하지 않는 쓰레드들은 모두 해제하는 것을 알 수 있습니다.
위에 설명에도 나와있듯이 short-living 비동기 프로그램에서 해당 쓰레드 풀을 사용하는 것을 추천한다고 하더군요.
nexFixedThreadPool과는 다르게 SynchronousQueue를 workQueue로 사용하고 있는 것을 볼 수 있습니다. 이 때문에 큐 사이즈는 항상 0이라고 합니다. 간단하게 SynchronousQueue에 대해 설명하자면 이는 버퍼가 없는 큐입니다. 대신 쓰레드와 전달받은 아이템들을 매칭시켜주는 역할을 한다고 합니다.
자세한 내용은 공식문서를 한번 참고해보세요.
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/SynchronousQueue.html
(3) newSinglethreadExecutor
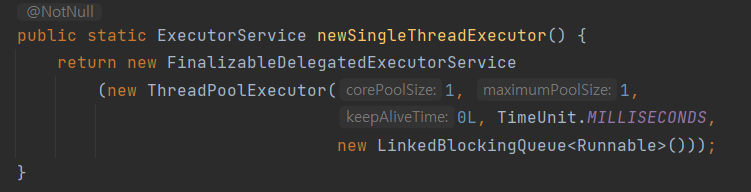

이것도 마찬가지로 이름에서 어떤 역할을 하는 지 바로 알 수 있겠네요! 쓰레드 풀 내에 쓰레드를 하나만 만드는 것이겠군요.
이 또한 요약해보자면 다음과 같습니다.
- corePoolSize == maximunPoolSize == 1
- keepAliveTIme == 0
newFixedThreadPool(1) 한 것과 정확히 똑같다는 점도 알 수 있습니다!
(4) ScheduledThreadPoolExecutor

newScheduledThreadpool은 ExecutorService가 아닌 ScheduledExecutorService를 리턴하는데요. 한번 확인해보도록 하겠습니다.
ScheduledExecutorService

ScheduledExecutorService는 ExecutorService를 상속하고 있는 인터페이스입니다. 마찬가지로 쓰레드풀을 관리할 수 있습니다. 여기에 한 가지 기능이 더 추가된 것이라고 생각하시면 되는데요. 바로 쓰레드 풀의 동작 시간을 설정할 수 있다는 점입니다.
scheduleAtFixedRate()

초기 딜레이 시간과 주기를 전달해줄 수 있습니다. 처음 쓰레드를 실행하고 initialDelay 만큼 지난 이후에 동작이 수행됩니다. period는 쓰레드를 실행하는 반복 주기를 의미합니다.


0.5초 뒤에 실행되고 2초 간격으로 해당 동작을 유지하는 것을 확인할 수 있습니다!
scheduleWithFixedDelay()

이 또한 마찬가지로 초기 실행 시간과 딜레이를 전달해주고 있어요.
scheduleAtFixedRate와의 차이점은 바로 딜레이의 기준에 있습니다.
scheduleAtFixedRate는 정해진 딜레이를 주기로 하는 반면, scheduleAtFixedRate는 메소드가 끝나는 시간부터 딜레이를 체크합니다.
정확한 비교를 위해 쓰레드를 잠깐 멈추고 비교해볼게요.


scheduleAtFixedRate()는 정확히 2초 간격으로 메소드가 실행되는 것을 확인할 수 있습니다.
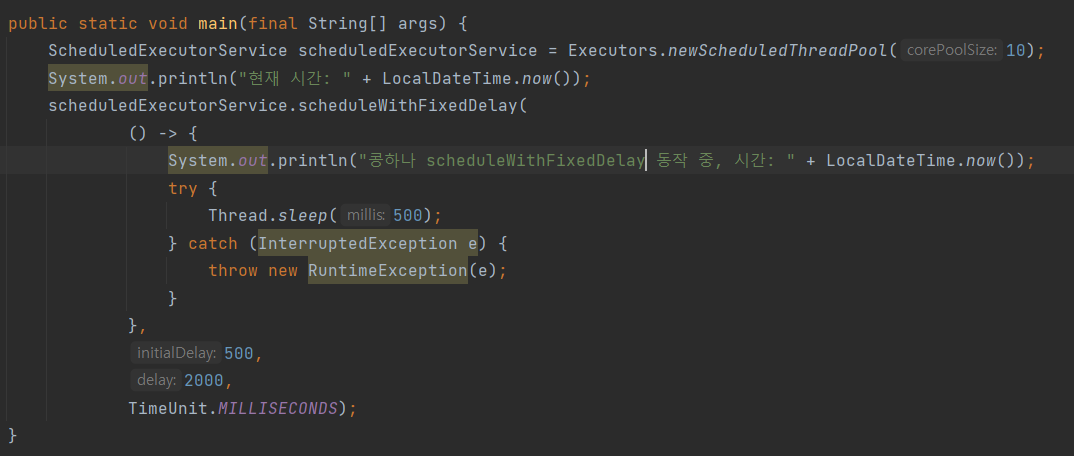

반면 scheduleAtFixedRate 메소드는 2.5초 정도 간격으로 실행되고 있는데요. 이는 중간에 쓰레드를 멈춰서 쓰레드의 동작이 끝난 이후로부터 딜레이를 체크하기 때문이에요.
이 정도까지 내용을 정리해볼 수 있을 것 같네요!
사실 이 외에도 ForkJoinPool이 따로 존재하기는 하지만 이는 재귀적으로 정의된 작업을 처리할 때 사용한다는 정도만 알고 있습니다. 함수를 재귀적으로 동작시키면서도 쓰레드는 생성하지 않을 때 ForkJoinPool을 만들어서 사용한다고 하더군요! 이 정도 개념만 이해하고 있다가 나중에 필요할 때 더 찾아보면 좋을 것 같습니다.
이 정도 정리하면 나머지는 응용해서 사용할 수 있을 것으로 보입니다.
공식문서나 baeldung 블로그를 보면서 정리를 해보았는데요.
잘못된 내용이나 궁금한 점이 있다면 편하게 답글 달아주세요!
감사합니다~~
'자바' 카테고리의 다른 글
| Java Thread, JDK 뒤져보기 (1) | 2023.11.14 |
|---|---|
| 아이템 51. 메서드 시그니처를 신중히 설계하라 (2) | 2023.03.22 |
| 단일 책임 원칙, 하나의 객체는 하나의 책임을 갖는다. (0) | 2023.03.14 |
| 아이템 68, 항상 표준 명명 규칙을 따라야한다. (0) | 2023.03.08 |
| 자바의 문자열 (0) | 2023.03.05 |