2022. 4. 28. 16:22ㆍ강의 내용 정리/컴퓨터 네트워크
Network Layer
전달받은 패킷을 어디에 전달할지를 정하는 것이 네트워크 계층의 주요 역할이다.
1. Network layer 개념
0) 개요
host to host 커뮤니케이션
- 컴퓨터가 host가 되고, 많은 줄과 호스트가 존재할 때 본인이 원하는 호스트와 연결하는 3계층

- Alice는 어플리케이션 혹은 노트북 / Bob은 서버
- 라우터는 3계충까지 올라갈 수 있기에 1계층부터 3계층까지 쌓여있는 것을 확인할 수 있다.
- 라우터: 메세지를 받아서 제대로된 것으로 전달하는 네트워크 장비로 받은 메세지를 어디로 보낼지 결정한다.
- Alice -> R2 -> R5 -> R7 -> Bob의 과정을 통해 Alice에서 Bob에게 통신이가능하다.
ex) 우체부 비유
1) Packetizing
(1) Packetizing
4계층에서 내려온 메세지에 2계층에 전달하기 전에 필요한 정보를 추가하는 것임.
- 피어 커뮤니케이션이기에 수신단에서는 2계층에서 받은 메세지에서 3계층의 헤더를 이해하고 필요한 정보를 제거하고 4계층으로 올리는 decapsulating의 역할을 진행한다.
(2) Routing and Forwarding
- A에게 받은 메세지를 B에게 전달하기 위해 네트워크 길을 선택하는 것이 주요 과제임
- 기능에 따라 라우팅 방식과 포워딩 방식을 나눌 수 있다.
- 현재는 라우팅 방식의 인터넷이 유명하고 이전에는 포워딩 방식이 더 유명했다.
Forwarding process
주요 역할: 패킷을 받아서 패킷이 가야할 곳으로 내보내는 것
-> 어디로 보낼지에 대한 정보가 필요하고 규칙에 의해 어디로 보낼지 정한다.
- 네트워크 계층은 어디로 내보낼지에 대한 규칙과 그 규칙에 의해 어느 줄로 내보낼지에 대한 table이 존재한다. 즉, routing 방식에도 존재한다.
2. Datagram and Virtual Circuit
- 일반적으로 Datagram은 라우팅 방식을 많이 사용하고, Virtual은 forwarding 방식을 많이 사용한다.
- 연결 설정을 할지 말지에 대한 역할이 주 차이점이다.
- Virtual Circuit에서는 연결설정을 진행한다.
- Datagram은 IP 네트워크 소프트웨어, 인터넷이 이에 해당한다.
- Virtual Circuit은 전화기나 교환기가 이에 해당한다.
1) Datagram Approach
- IP 소프트웨어를 사용해 메세지를 전달하는 장치인 라우터로 연결된 '인터넷'이 보급되며 유명해짐
- 라우터는 알아서 다른 라우터로 보내기에 거시적관점에서 독립적으로 존재한다. -> 라우터만 잘 만들면 됨
- 'connectionless': 연결설정과 해제설정이 없다. ex) 알로하 등
- 이전에 받은 메세지는 고려하지 않고, 지금 받은 메세지를 메세지의 정보를 통해 이동시킨다.
- 뒷쪽 패킷의 정보에 영향을 미치지 않기에 이 또한 독립적으로 존재한다.
(1) A connectionless packet-switched network
- R은 라우터
- 패킷이 각각 독립적으로 동작하고 connection less인 것을 확인할 수 있다.
- 패킷을 받아서 전달하는 것을 패킷 스위칭이라 한다.
- 패킷 스위칭을 통해 네트워크를 연결한 것을 의미한다.
- 1, 2, 3, 4의 메세지를 전달했을 때 R1은 모두 받아서 이를 최종적으로 Receiver에게 전달해주지만 R2, R3, R4에 따로따로 보내지는 것을 확인할 수 있다. 즉, 비연결형으로 데이터 연결 및 해제 설정을 하지 않는 것을 확인할 수 있다. 또한 도착하는 거는 보낸 순서와 다른 것또한 확인할 수 있다.
- 중앙집권화되지 않았기에 모든 장치는 각각 대등적이며 독립적으로 동작하여 한 장치가 파괴되어도 다른 장치를 경우해서 네트워크할 수 있다.
- 국방부에서 지원했고 생존성을 중요하게 고려한 네트워크를 구현한 것이고 결국 중간의 어느 한 라우터가 부숴지더라도 목적지까지 안정적으로 도착한다.
- 즉 인터넷은 서바이벌을 위해 만든 것이었지만 점점 민간 목적으로 변했다.
(2) Forwarding process in a router
- 패킷 내에 있는 destination address인 입력과 어느 라우터로 보낼지에 대한 출력하는 인터페이스로 내보내는 테이블 형태로 존재한다.
- output interface는 매번 다를 수 있다.
2) Virtual Circuit approach
- Circuit은 통상 1계층을 의미하지만 해당 방식은 물리적인 연결이 아닌 로지컬한 줄을 연결한 방식이기에 다르다.
- Connection oriented(Virtual Circuit)
- 패킷이 전달되기 전에 연결 설정을 한 뒤, 패킷이 전달된 이후에는 연결을 해제한다.
- 연결을 할 때 어떤 장치를 통과할지 미리 조정하기에 그 이후에 보내는 메세지는 연결 설정에 의거해 만들어진 동일한 줄을 따라서 보내짐
- 라벨을 붙이기 시작해 라벨이 어떤식으로 만들어지고 붙여지는지에 대한 과정도 필요하다.
(1) virtual circuit packet-switched network
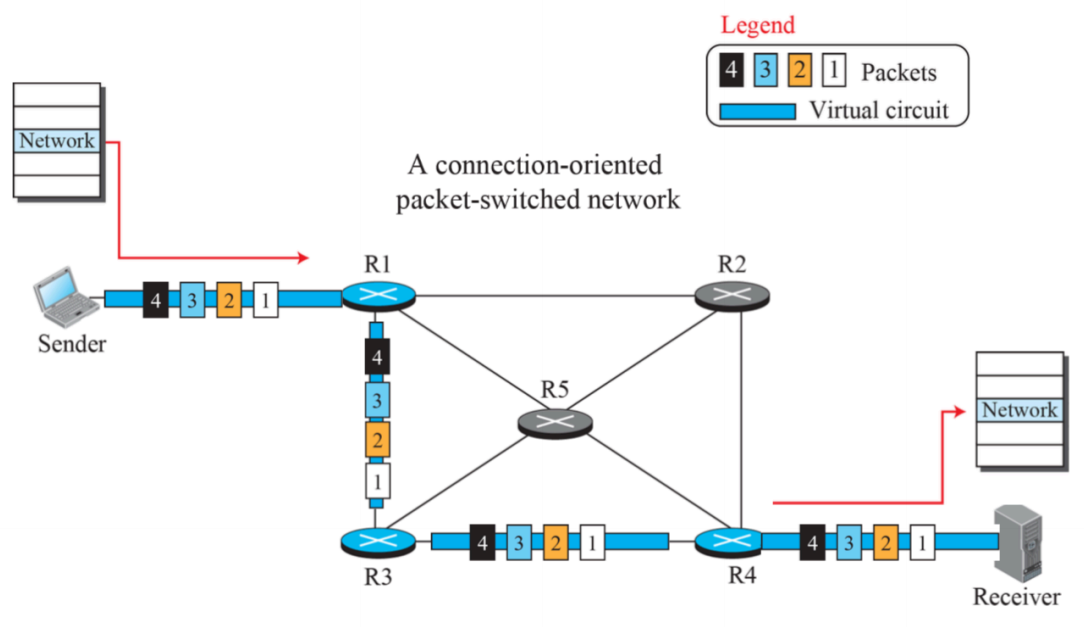
- 패킷 스위치는 단순히 패킷을 내보내는 행위를 의미하기에 virtual circuit에서도 동일하게 등장한다.
- sender와 receiver 사이에 파란색 파이프로 연결되어있고, 패킷은 순서대로 보내지는 것을 확인할 수 있다.
- 이는 연결 지향 방식이다.
(2) forwarding process in a VC switch
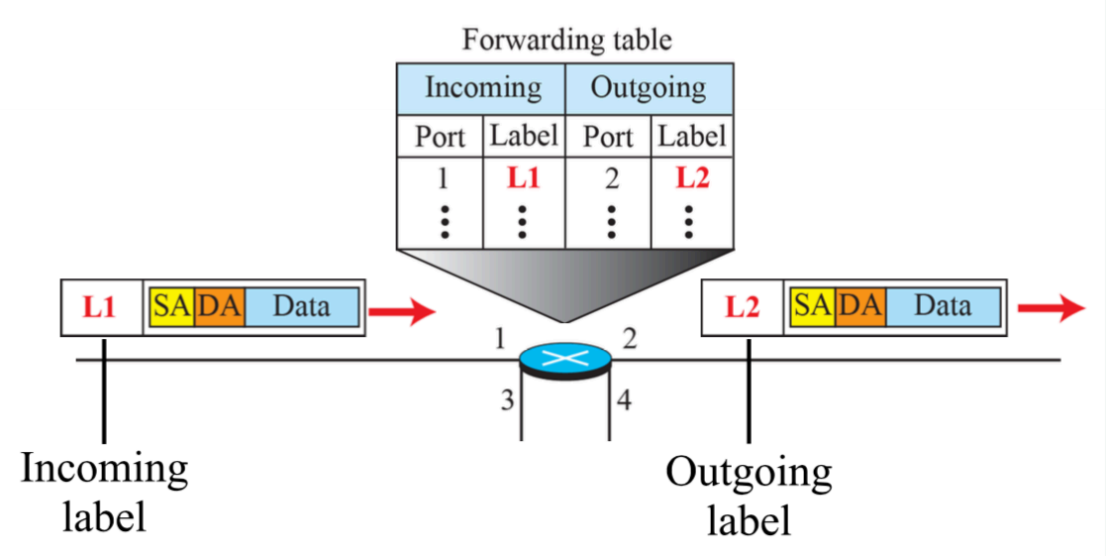
- 테이블 내에는 incomming 포트와 outgoing 포트가 존재한다.
- 포트는 인터페이스라고 부르기도 하는데 이는 라벨이 붙여져있다.
- 해당 장치에 1, 2, 3, 4 줄이 꽂혀있을 때 줄을 꽂는 구멍, 인터페이스를 포트라고 한다.
L1: incoming label로 해당 줄에서만 의미가 있다. 네트워크 layer에서 준 것이다.
- 1번 줄을 통해서 label field가 L1인 패킷이 보내진 것이다.
- outgoing할 때는 2번 포트로 해당 메세지를 보내고 라벨을 L1에서 L2로 바꾼다.
- incoming을 보고 바로 계산되어서 나오기에 간단한 것을 확인할 수 있다. 라우터는 어디로 보낼지에 대해 계산하는 과정이 복잡하다.
(3) Sending request packet in a virtual-circuit network
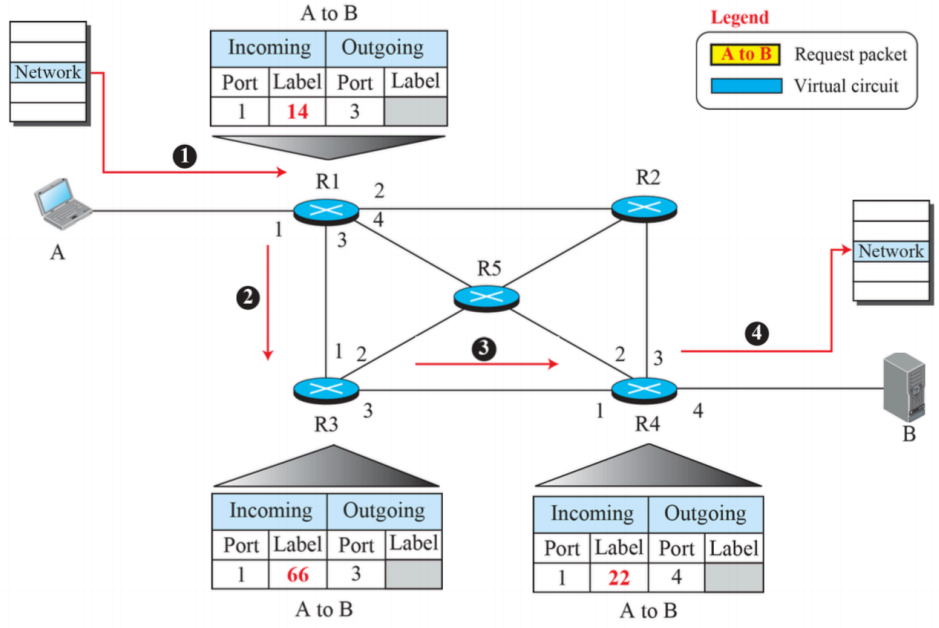
- virtual circuit 방식에서 커낵션을 설정하는 방법
- b와 통신을 바라는 A는 본인의 네트워크 레이어에서 virtual circuit의 연결 지향을 시작 -> 정보를 패킷으로 최초로 전달 -> 연결설정을 요청하는 메세지가 1번을 타고 전달됨
처음 라벨은 네트워크 패킷에 존재하지 않음 -> R2에서 라벨이 비워져있으면 본인이 라벨을 채움. -> B를 설정하기위해 어디 router로 갈지 고민하고 R3로 감. 이때 어느 router로 갈지 고민하는 것은 처음에 연결설정을 해줄 때만 해당한다. R1은 R3에게 다시 연결 요청 메세지를 전달한다.
R1이한 것처럼 R3는 R3에서 보낼 라벨은 없기에 어디로 보낼지에 대한 위의 과정을 반복한다.
A와 B에게 연결설정이 이루어지면서 incoming label은 받은 쪽에서 채워지고, outgoing label도 받는 쪽이 채워야한다.
(4) Sending acknowledgments in a virtual-circuit network
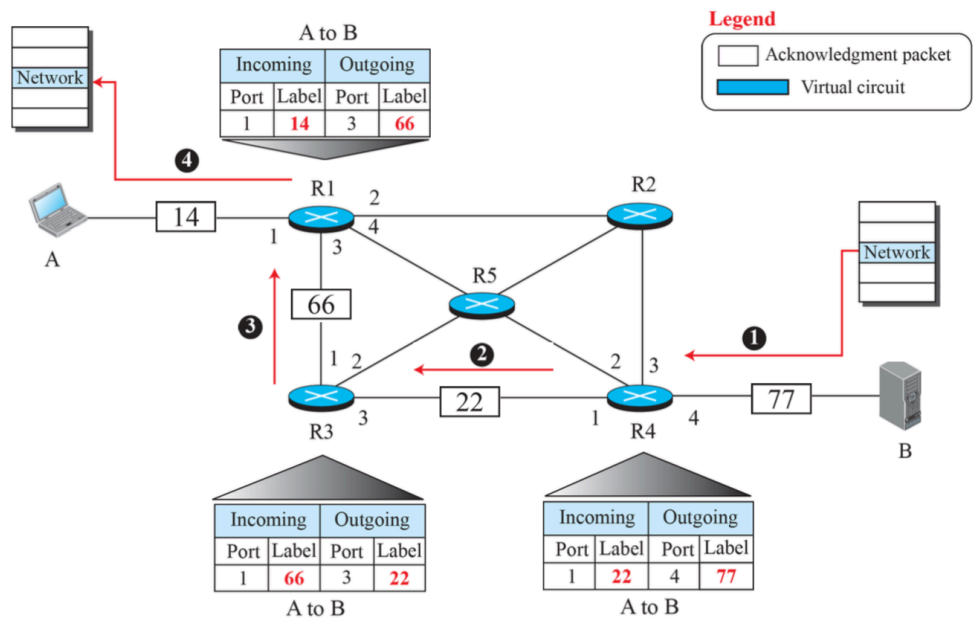
- B가 R4의 outgoing 라벨을 채운다. -> R4에서 B에 대한 라벨을 붙임
- R4가 R3의 outgoing 라벨을, R3가 R1의 outgoing 라벨을, A가 R1에게 보낼때 쓸 라벨인 14를 R1이 설정한다.
- 위와 같은 방식으로 virtual circuit을 만들 수 있다.
- virtual circuit 스위치라고 부름
- 경로결정을 위한 동작을 함
(5) Flow of one packet in an established virtual circuit
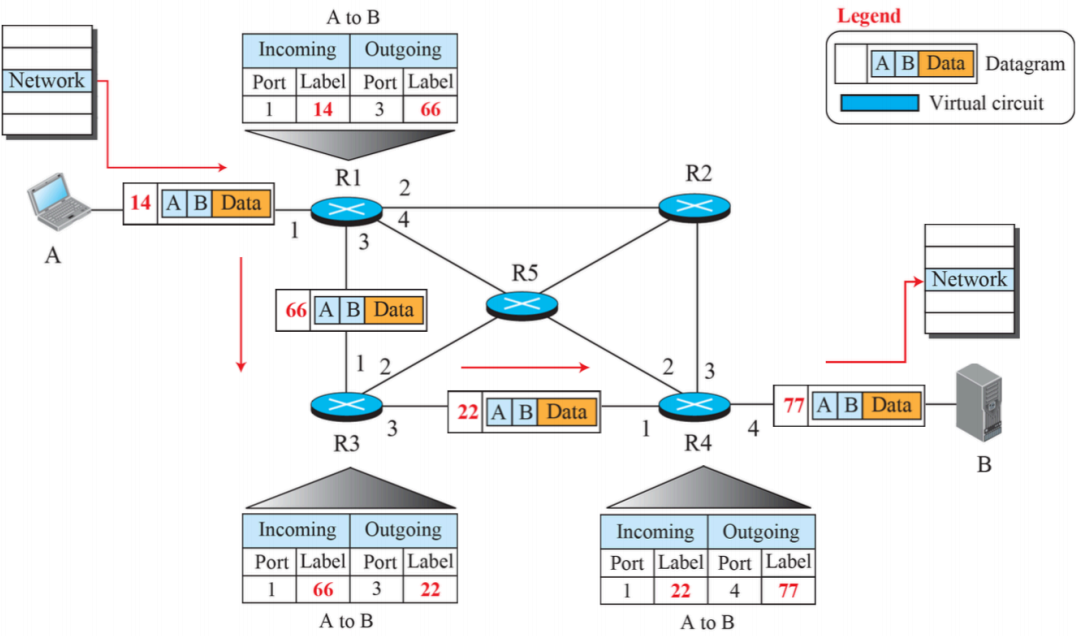
- 연결 설정 과정 이후 A가 B에게 데이터를 보낼 때 라벨과 시작, 끝, data를 보낸다.
- 연결과정의 복잡한 과정을 거친 뒤에는 간단하게 테이블에 따라 보내면 되기에 전달하는 속도는 빠름
3. Network Performance
정량적으로 네트워크를 비교할 때 사용하는 지표
0) 개요
- osi 7계층 전체에 적용할 수 있는 단어와 의미가 있다.
- 다른 계층에 비해 3계층은 많은 장치와 기술이 반영되었기에 성능에 대한 부분이 중요함
- delay(지연) / Throughtput(처리율) / packet loss(손실율)을 중점으로 설명하고자 함
- Congestion control의 입장에서도 설명 가능하다/
ex) Congestion이 발생하면 상대방 측에서 패킷이 손실되기에 throughput에 영향을 줌 / 재전송도 하기에 delay도 늘어남
1) Delay
한 스테이션에서 다른 스테이션에 도착했을 때 걸리는 시간
(1) 종류
i) Transmission delay: 표준 규격에 의해 정해진 전송 속도에 대한 지연
ii) propagation delay: 자연이 만들어낸 지연
iii) processing delay: 줄을 연결하는 네트워크 장치에서 처리하는데 발생하는 지연
iiii) queuing delay: 여러 개의 데이터가 하나의 줄을 통해 송신해 버퍼에 의해 발생하는 지연
- 최근에는 요구하는 딜레이 시간이 줄어들고 있음
ex) 자율주행자동차의 브레이크
2) throughtput
입력이 발생했을 때 이를 얼마나 처리할 수 있는가에 대한 지표
- 흔한 throughput에 대한 예시는 data rate임
- 두가지 해석 방식
- Rate: 얼마의 속도를 지원할 수 있는지
-
(1) Rate
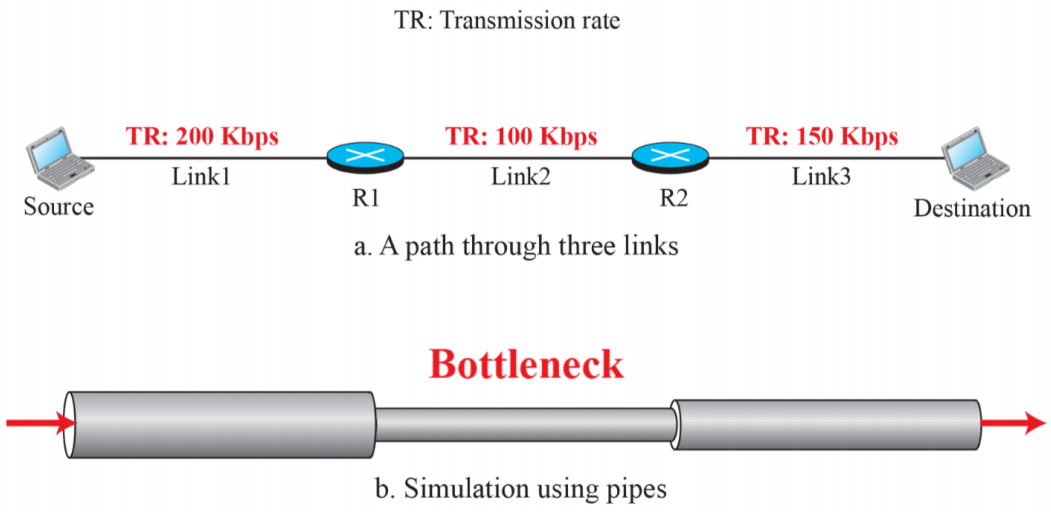
- Source와 Destination에서의 최대 전송속도 100Kbps가 peek data rate가 된다.
- throughtput을 올리기 위해서는 병목을 제거하는 것이 중요하다.
- 어떤 줄에 의해 연결되어있는지에 의해 속도를 정할 수 있다.

하지만 어느 줄을 연결했는지 아는 것은 어렵기에 전송 속도를 확인하기 어렵기에 위처럼 구름 그림을 그리는 경우가 많다. 이에 따라 최소 throughtput를 요구헤서 네트워크 성능을 유지할 수 있어야한다.

- 네트워크는 한줄로 연결할 때 많은 장치가 들어가 있는 것을 확인할 수 있음
- 수많은 컴퓨터가 얼마나 연결되어있고, 어떤 패턴으로 사용하는지 등을 파악해 어떤 줄을 연결할지 정해야함
throughtput의 두번째 의미는 밀어넣었을 때 네트워크를 통과해서 얼마만큼 남았는지를 체크하는 것. 이에 따라 이는 1보다 작은 분수의 값을 가진다.
3) Packet Loss
송신한 메세지 중 얼마나 없어지는지에 대한 지표
ex) 현재 라우터가 100개까지 패킷을 받을 수 있지만 110개의 패킷이 수신될 때 버퍼 오버플로우가 발생
- 2계층에서와 같이 이를 congestion이라고 표현하고 이를 컨트롤할 수 있어야한다.
- 혼잡도에 따라 얼마나 버틸 수 있을지 계산할 수 있어야한다.
(1) Congestion Control
스위치나 라우터가 과다한 데이터를 받거나 특정 링크로 데이터가 몰렸을 때 조절하는 것
- IP 소프트웨어에서는 부족하기에 위에서 이를 조절해야함 따라서 transport layer가 이를 해줌
- 2계층에서도 에러검출은 하지만 3계층에서 IP 소프트웨어를 사용하고 서비스의 신뢰성를 보장해야한다면 4계층에서 에러 검출은 필수불가결하게 필요하다. 따라서 2계층과 비슷하지만 4계층은 4계층 이하의 에러 검출 및 복구를 하는 것에 초점을 맞춤
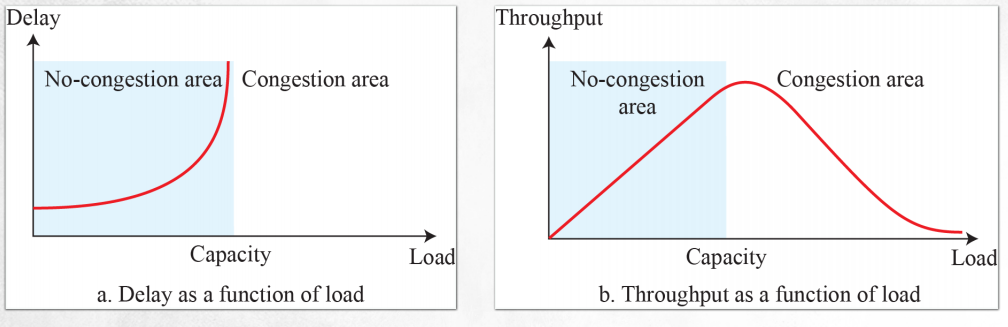
- x축은 로드로 네트워크의 부하가 증가하는 것을 의미한다.
- 왼쪽에 있는 그림은 버퍼가 무한한 것을 의미한다. 이를 확인해보면 delay가 한없이 높아지는 것을 확인할 수 있다. 하지만 버퍼는 유한하기에 오른쪽 그래프와 같이 동작하지만 정점을 찍은 이후에는 일정하게 throughtput을 유지해야한다.
- 원하는 loss의 수준이 있어야한다.
ex) 음성 전화 100개 중에 1개가 깨지는 경우 돈받고 서비스를 할 수 있음
- 이에 맞춰 지연을 얼마만큼 감당할 수 있는지 확인해야한다.
- 지연은 loss를 야기하기도 하고 버퍼가 무조건 큰 것도 좋은 것은 아니다는 것도 확인할 수 있다.
4. Addressing
IP 프로토콜의 어드레스를 중점적으로 설명
1) Addressing
- 버전은 두 가지가 있는데 일반적으로 알려진 것은 IPv4이고, 그 외에 IPv6가 존재한다.
- TCP/IP
- IP는 internet protocol의 약어이고 IPv4는 4바이트(32비트)를 사용한다. 이에 따라 2의 32승계를 나열할 수 있다.
- 전세계에서 유일한 유니크한 종속값을 가지기에 다른 컴퓨터와는 중첩되지 않는다.
- IP 주소는 컴퓨터와 연결된 줄의 주소를 의미한다. 즉, 무선랜과 이동통신 선을 통해 컴퓨터를 연결할 수 있다면 IP가 두개가 될 수 있다. 서버는 하나의 컴퓨터가 두 개 이상의 초고속 인터넷과 연결하는 경우가 많아서 IP 주소가 두개 이상인 경우가 많다. 라우터 또한 연결된 줄의 주소에 따라 IP 주소가 배정된다.
- 지금까지 본 것은 IPv4 주소 필드가 유한된 사이즈로 있었다.
- IPv4는 비트로 이를 계산한다.
- 특수 목적을 제외하면 232부터 4십억개 이상의 주소를 사용할 수 있지만 인터넷을 깔기 시작한 선도국가에 의해 이미 고갈되었기에 이를 어떤 식으로 부여하고 관리하는 지에 초점을 맞춰 공부하는 것이 더 중요하다.
2) 주소의 notation
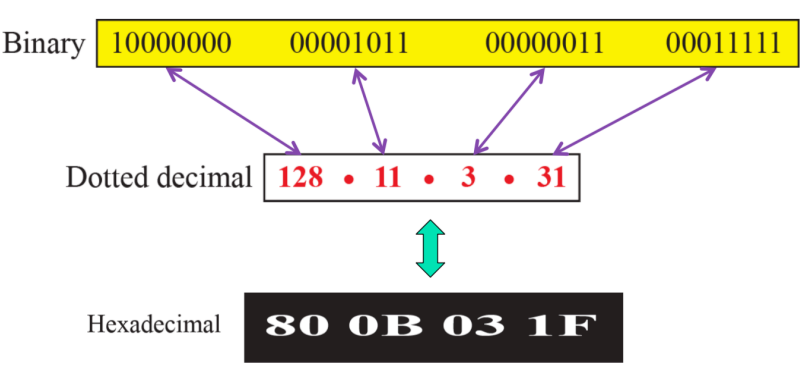
- Dotted decimal은 각각의 8비트 값을 10진수로 표현하는 것으로 가장 많이 사용하는 notation 방법이다.
- Hexadecimal은 점을 빼고, 각각이 4비트를 나타낼 수 있고, 프로그램을 짤 때는 이를 많이 사용한다.
3) Hierarchy in addressing
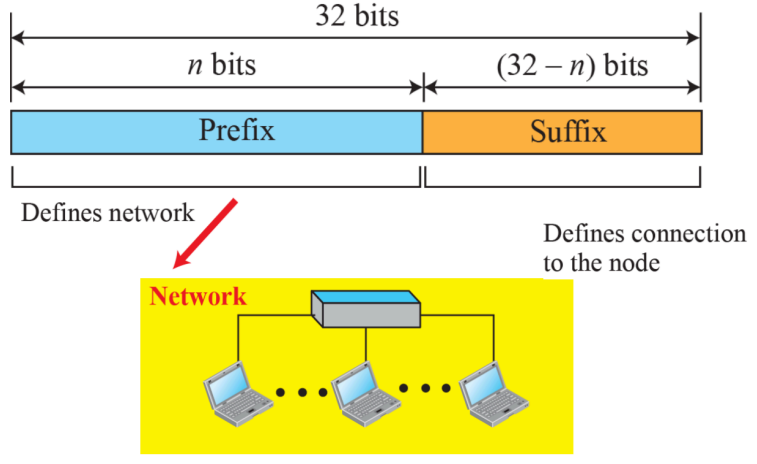
- 최근에는 시계까지 IP 주소를 가지고 있기 때문에 앞으로 컴퓨터가 몇 대가 나올 지 알 수 없고 당연히 32비트로 표현할수도 없다. 이에 따라 나라별로 IP를 잘라서 두고, 특정 값을 시작으로 특정 값으로 끝나는 것을 국가에게 전달해주고, 국가는 기관에 나눠주고, 기관은 건물에 나눠주는 등 영역을 나누기 시작하는 도메인의 개념이 도입된다.
- n 비트 값을 계산했을 때 이에 해당하는 것을 제외한 뒤쪽에 있는 것을 사용할 수 있다.
- IPv4 32비트를 앞쪽에 n비트를 네트워크에 부여된 주소로 정의하고 이를 부여받으면 호스트는 뒤쪽에 있는 suffix를 알아서 활용한다. 이에 따라 외부에서는 Prefix만 보고 기관 등을 확인할 수 있다. 묵시적으로 앞 쪽은 네트워크를 의미하는 주소가 되고, Suffix는 그 내부의 컴퓨터를 의미하는 것으로 고려된다.
(1) 문제점
- 초창기에는 인터넷을 많이 사용하지 않을 것이라 생각해 간단하게 고려해 prefix를 8, 16, 24비트로 표현했다. 이에 따라 각각 class A, B, C, D, E라고 표현하고 이를 classful addressing이라 표현했다.
- 컴퓨터가 많아지자 classful addressing은 비판을 받기 시작했다.
(2) Occupation of the address space in classful addressing
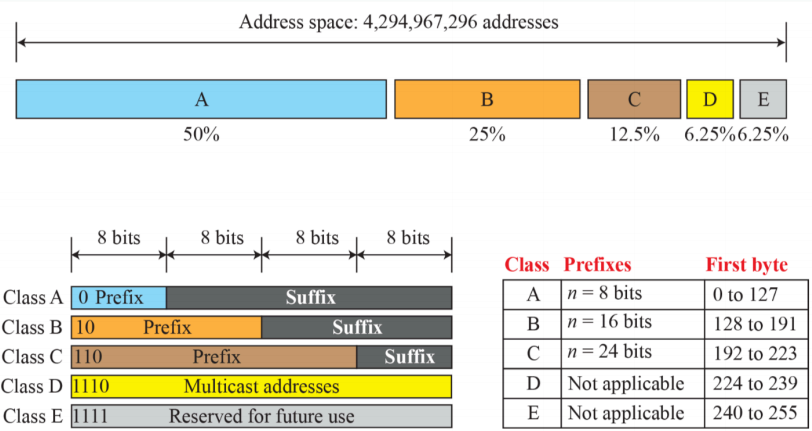
- 0으로 시작하는 주소는 class A
- 10으로 시작하는 주소는 class B
- E는 미래를 위해 대비했지만 낭비가 된 사례이다.
- 클래스 A를 받으면 네트워크 주소가 8비트이기에 24비트는 마음대로 할 수 있다.
- 처음에는 인터넷을 많이 쓸 것이라 생각하지 않았기에 위와 같이 사용했지만 차후에 컴퓨터가 많이 늘어나서 classful 방식은 이론적으로만 처음에 적용이된다. 이후에는 classless 방식이 도입되었다.
(3) classless
- 가변적으로 네트워크 주소인 n비트를 부여하여 4바이트를 어떻게든 활용하고자 했다. 하지만 기존 장치에서 사용하던 방식을 바꿀 수 없기에 IPv6는 신흥 국가나 특정한 조직 내에서만 사용 가능하다.
(4) classless addressing에서의 가변 길이 블럭

- 필요한 곳에 적당하게 flexable하게 사이즈를 정해 조직에게 전달해준다. 이에따라 prefix는 가변적으로 전달이 가능하게 된다.
(5) slash notation

- 가변적인 suffix방식이기에 네트워크 주소를 따로 알려줄 필요가 있다. 이에 따라 /이후에 있는 값만큼 앞에서부터 네트워크 주소라는 의미이다.
(6) information extraction in classelss addressing
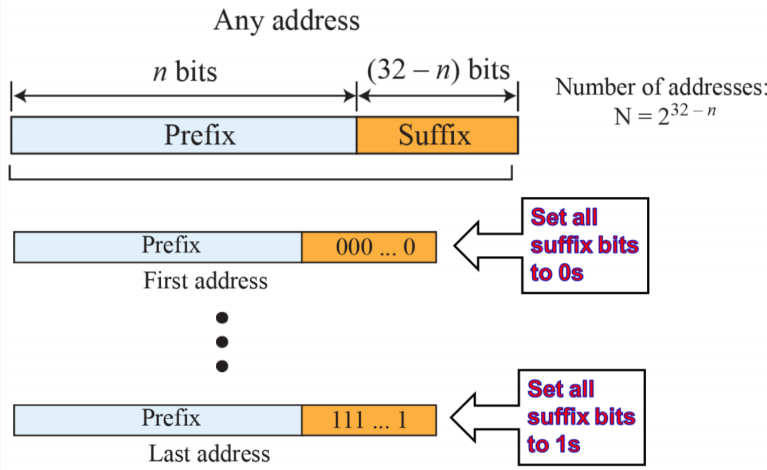
- Prefix가 자율적으로 배정될 수 있지만 Suffix는 조직 내에서도 이를 쪼개는 과정이 필요하다.
- 조직 내에서 Suffix가 부여되지만 조직 외부에 있는 사람들은 네트워크 주소를(prefix) 아는 것이 관심사이다. 따라서 라우터가 알아야하는 것은 목적지의 네트워크 주소가 된다. 라우터는 컴퓨터 주소의 모든 것을 알 필요가 없다. 즉, 통상적으로 라우터는 외부에서 전달하는 것이기 때문에 목적 주소에서 32비트를 모두 봐서 전달하는 것은 아니다.
(7) Network address routing example
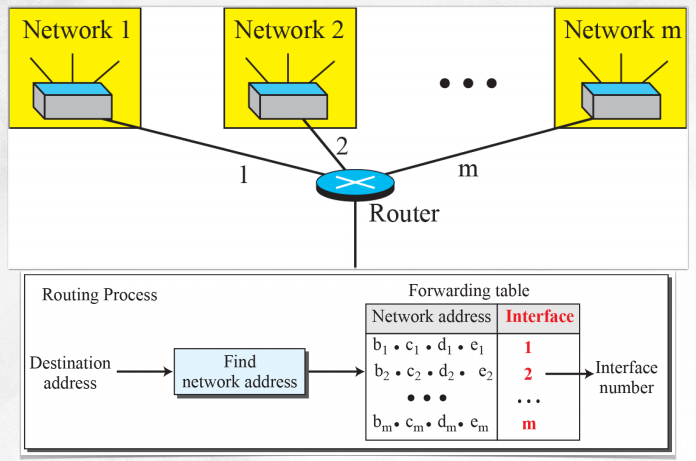
- 라우팅에서 찾는 키 값은 네트워크 주소이다.
(8) Example of address aggregation
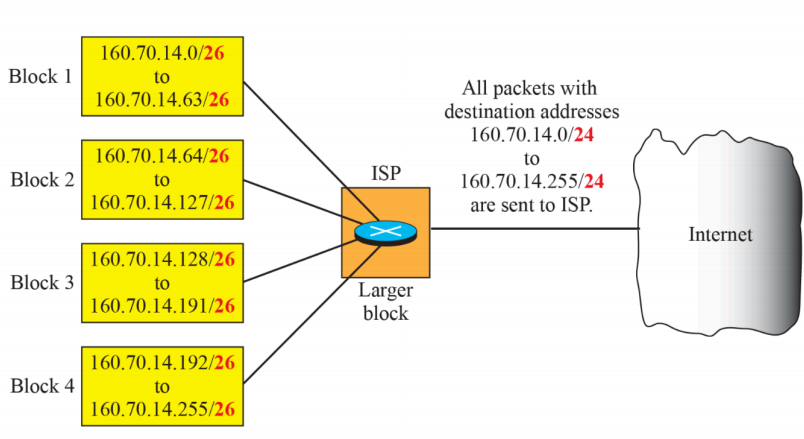
- 조직 내부에 들어온다면 조직 내부의 라우터에서 IP를 확인해서 내부적으로 26비트를 모두 확인하지 않고, block 1, 2, 3를 확인하지 않고 2비트를 확인하지 않고, 24비트만 보고 주소를 합쳐서 보낸다. 이에 따라 4개의 레코드가 하나의 레코드로 줄어들고 주소의 네트워크를 합치는 행위를 address aggregation이라고 한다.
- 대부분 건물 단위로 라우터가 존재한다.
5. More Issues
부족한 IP 주소를 해결하기 위해 등장한 기법들, 보충 설명
1) DHCP (Dynamic Host Configuration Protocol)
장치에 네트워크 환경을 자동으로 설치하는 기법
(1) DHCP란
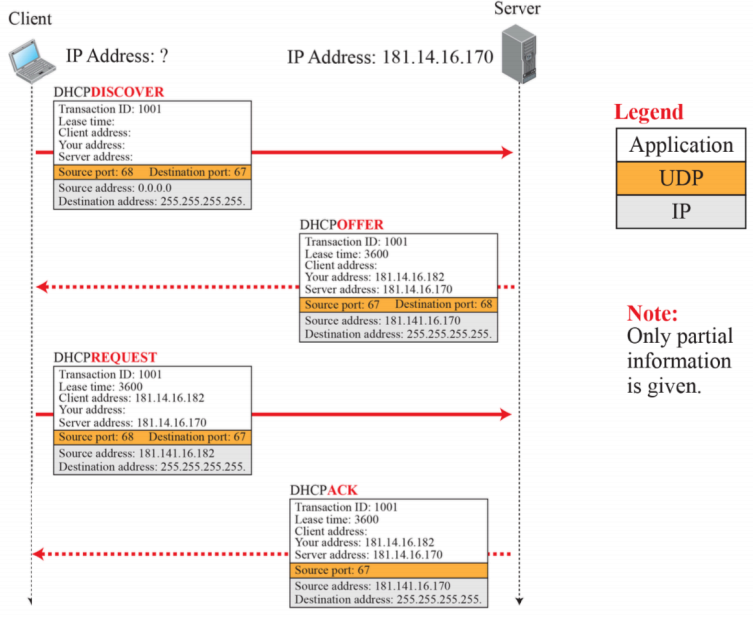
- IP 주소를 네트워크의 어딘가로부터 정보를 자동으로 가져온다.
- 네트워크 내에서 Dynamic은 manual과 반대되는 의미로 사용된다.
- IP 주소가 부족하기에 이를 일단 full로 사용하고 필요한 장치들이 빌려가고 반납하는 식으로 재사용한다는 점에서 의의가 있다.
(2) 메세지 포맷
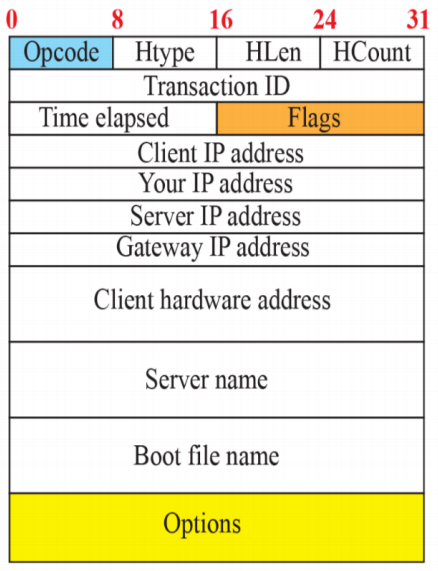
- 위의 메세지를 주고 받는다.
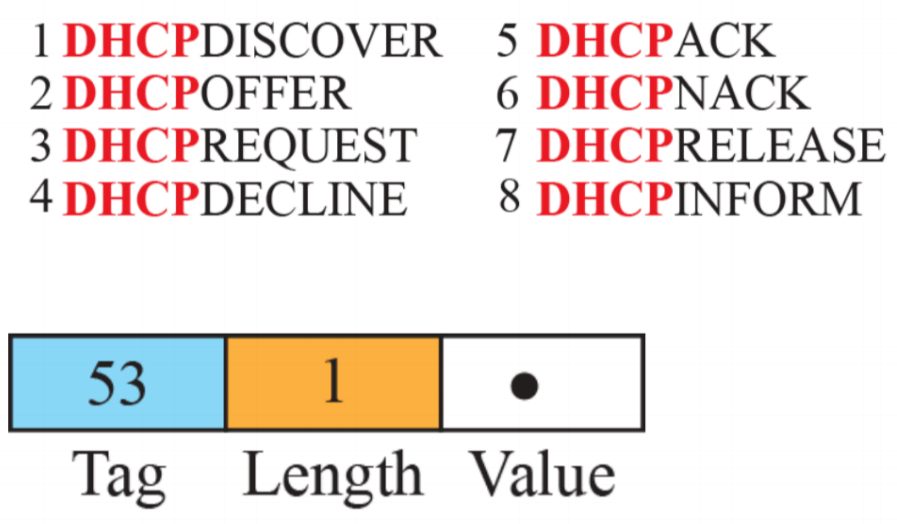
- 위의 옵션 명령을 활용해 의미를 담을 수 있다.
(3) 메세지 송수신 과정
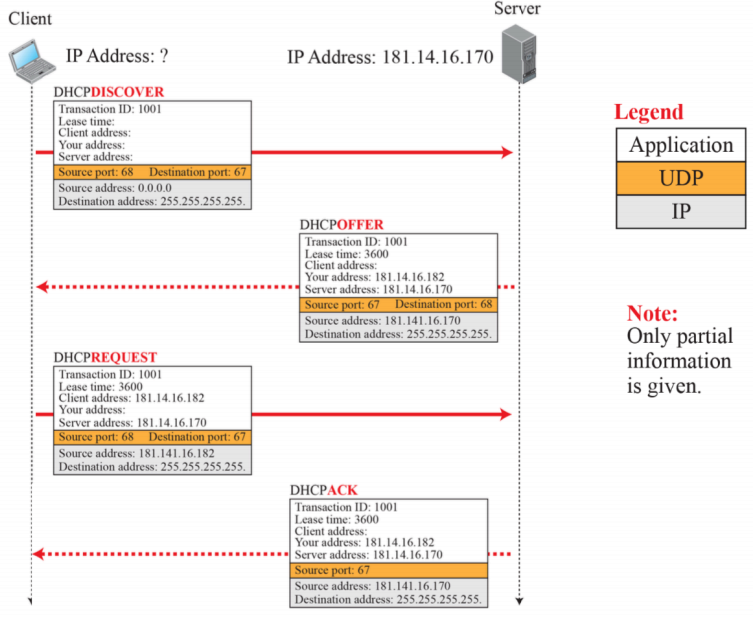
- 초기에는 client의 IP address가 없는 것을 확인할 수 있다.
- 하얀색은 Application layer, 주황색은 UDP layer, 회색은 IP layer이다.
- UDP는 connection less로서 4계층이고 이를 메세지를 통해 주고받을 수 있다.
- Port number는 어플리케이션과 관계가 있다.
- DHCPDISCOVER는 IP 주소를 요청한 것이다. 이때 Source 주소는 본인이기에 0.0.0.0이고 Destination 주소는 255.255.255.255이다. 서버가 있는지 없는지 모르는 상황에서 가능한 모든 곳에 요청을 보내기 위해 destination 주소를 위와 같이 설정한다.
- DHCPOFFER는 주소를 제안하는 것이다. 이때 source 주소는 본인의 주소를 의미한다. 이때 destination 주소는 client의 주소가 없기에 255.255.255.255로 설정해 모두에게 보낸다. Lease time은 최대 네트워크를 빌려주는데 허용하는 시간으로 이 시간이 지나면 재요청을하거나 연장해야한다. Your address로 주소를 전달해준다.
- DHCPREQUEST는 원하는 네트워크 주소를 요청하는 것이다. 오퍼받은 주소로 클라이언트 주소를 채우고, 아직 과정이 끝나지 않았기에 Destination 주소를 모두에게 보낸다.
- DHCPACK는 REQUEST를 수락하고 이를 보내는 것이다. Destination address도 이전과 마찬가지로 255.255.255.255로 보낸다.
- 매일 사용한다.
2) NAT
Network Address Translation
(1) NAT란?
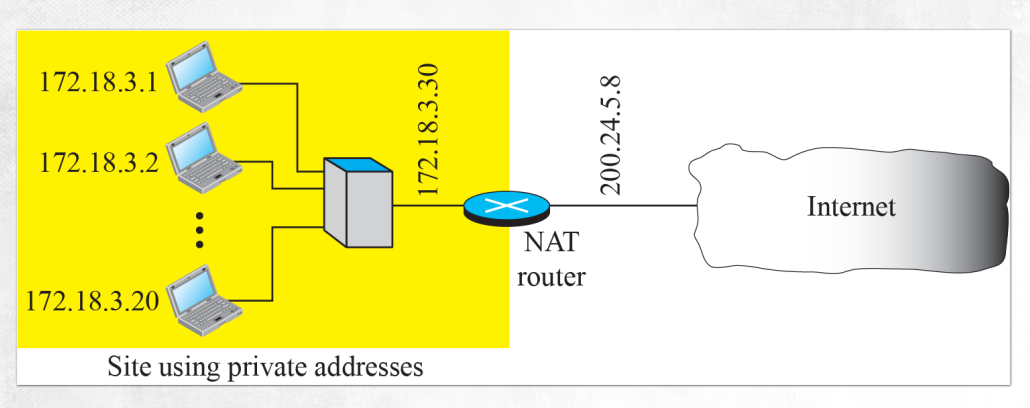
- 과거 컴퓨터의 IP Address가 부족하니 Universal Address와 Private Address를 구분하여 사용하는 기술
- Universal(Public) Address는 지역 외부에서 사용할 수 있다.
- Private Address는 지역 내에서만 의미가 있다. 이에 따라 외부에서 사용하고자하더라도 접근할 수 없다. 또한 이는 IP Address에서 정한 규칙을 준용할 필요는 없다.
- 유무선 공유기는 유선/무선 자원을 공유하는데 바깥 네트워크에 의미가 있는 universal address 혹은 KT에서 부여한 address를 하나 부여 받고 유무선 공유기를 사용하는 컴퓨터에서는 해당 주소를 공유한다. 유무선 공유기는 집 내부에 있는 기기에 DHCP를 사용해 private Ip address를 할당한다.
- Private IP Address를 사용해 집 내부에서 통신할 때는 문제가 없으나 집 밖에 있는 universal IP address가 필요할 때는 Private IP address를 번역하는 것이 NAT이다.
(2) 네트워크 통신 예시
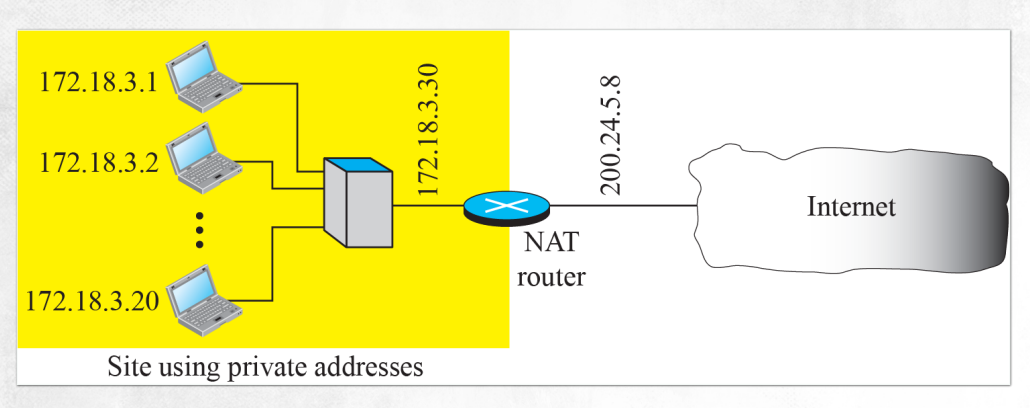
- 200.24.5.8은 universal address이기에 외부에서 사용할 수 있다.
- 동일한 NAT router가 커버하는 지역에 대해서는 172.18.3.30을 공유한다.
- 기기에서 외부와 통신할 때는 1:N의 관계로 address를 번역해야한다. 이에 따라 IP address를 아낄 수 있다.
(3) 구체적인 네트워크 통신 예시
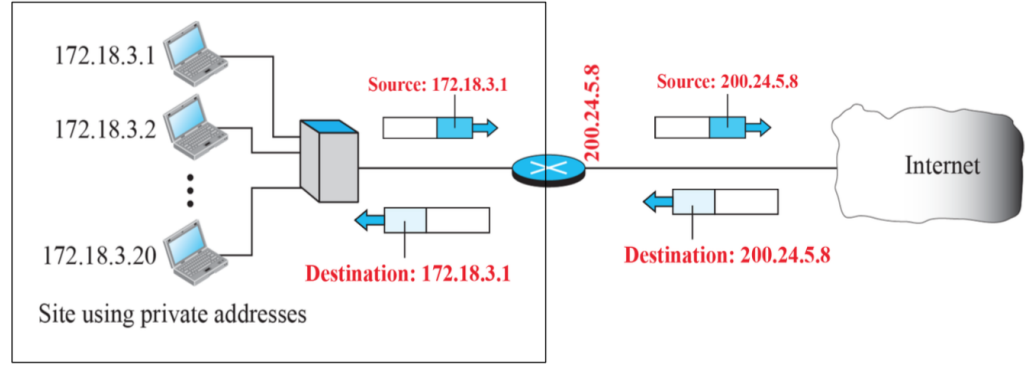
- Source Address를 NAT router는 Public Address로 바꿔 송신을 하고, 받을 때는 public address를 private address로 번역해 보낸다. 하지만 어디로 보낼지 알기 어렵다. 따라서 source address만 보고 주소를 바꾸는 행위는 동작하지 않는다. 즉, 더 많은 정보를 가지고 각 장치의 키 값을 확인해 이를 보내야한다.
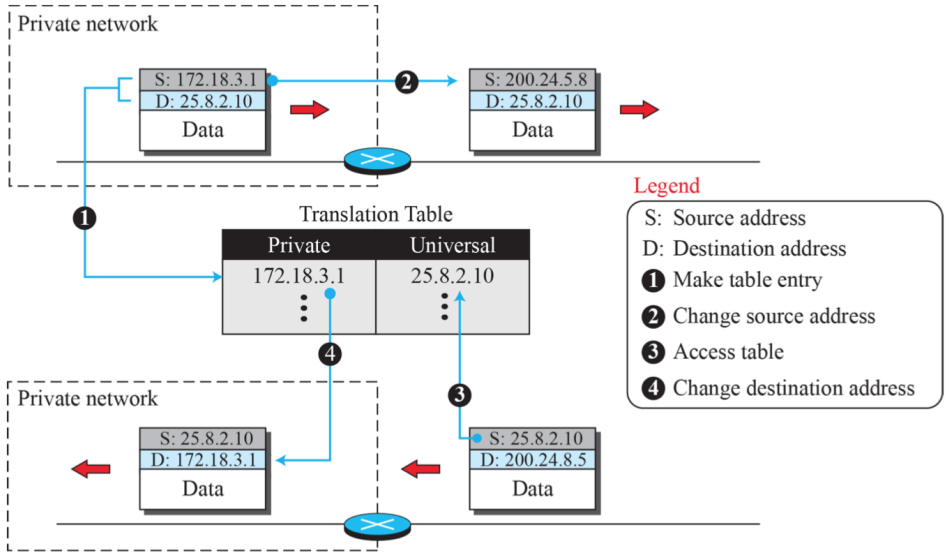
- 번역할 수 있는 테이블이 존재해야한다. 하지만 NAT에 대한 표준 방법은 존재하지 않는다. 데이터를 보낼 때 Source address만 확인하진 않는다.
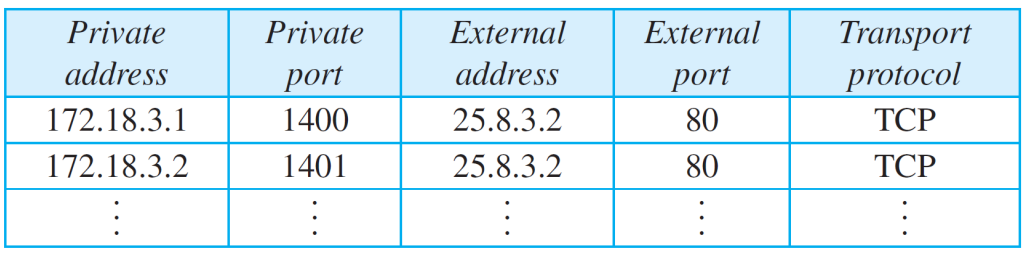
결국 IP Frame 내에 있는 많은 정보를 가지고 테이블을 구성하고, 각 정보를 조합해 중첩되지 않는 키 값을 만들어서 소스에게 전달해야한다. 가능한 많은 정보를 가지고 조합할수록 성공적으로 보낼 수 있게된다. 하지만 그럼에도 불구하고 중첩되는 경우가 많다. 소프트웨어를 설치했을 때 동작하지 않는 경우가 존재할 수 있다. 따라서 업체마다 고유한 알고리즘을 만들어서 복잡한 정보를 읽어서 나간 패킷의 정보를 확인할 수 있도록 키값을 만들어내는 것이 핵심이다.
가장 큰 NAT는 KT와 SKT이다. SKT는 내부적으로 Private IP address를 사용하기에 하나의 거대한 Private address이기에 이를 바꾸는 과정이 굉장히 중요하다.
(4) address aggregation
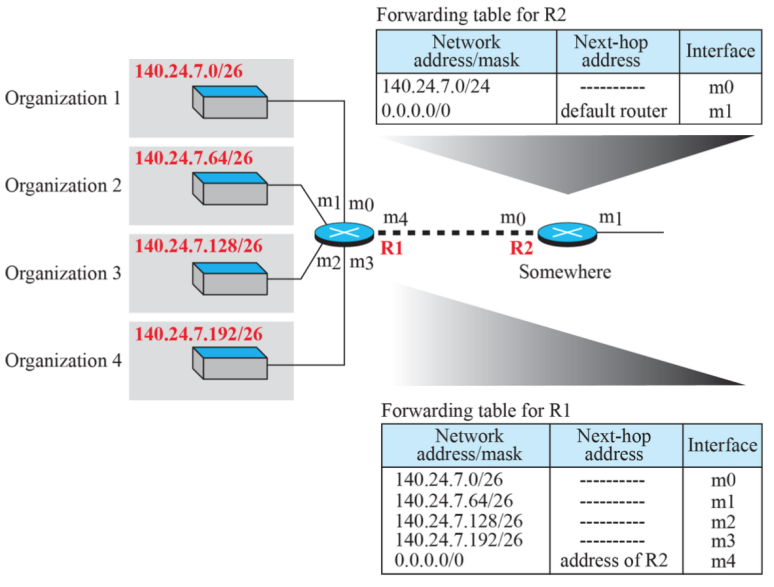
- 4개의 건물을 분할해서 R1으로 흘려보내고, R2는 인터넷이다. R1에서의 앞의 26비트가 건물을 나누는 주소 필드로 사용되지만 R2의 입장에서는 굳이 하나하나 분할할 필요가 없이 24비트까지만 확인하고 R1에게 바로 보낸다.
(5) 만약 네개의 건물에 위치한 장치를 하나 떼어내서 외부로 옮길 경우에는?
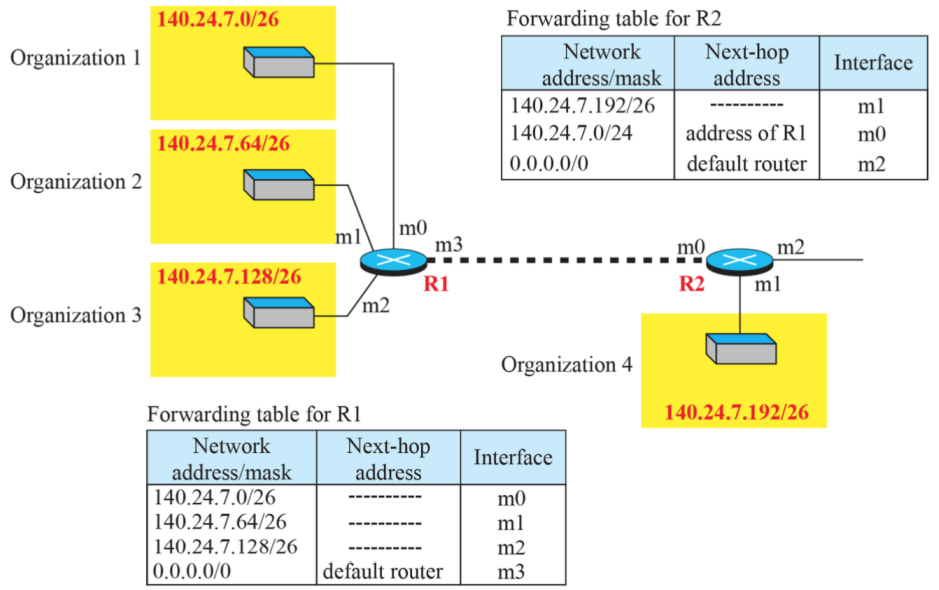
- 떼어낸 장치의 주소는 그대로 존재한다. 하지만 R2의 network address가 추가된다. 또한 하나만 빠져나왔다고 해서 Network address aggregation을 버리지 않고, 기존 주소의 위쪽에 이를 추가한다. -> 위에서 아래로 혹은 긴 것을 중심으로 먼저 확인하기 때문에 위쪽에 추가한다.
(6) Hierarchical routing with ISPs
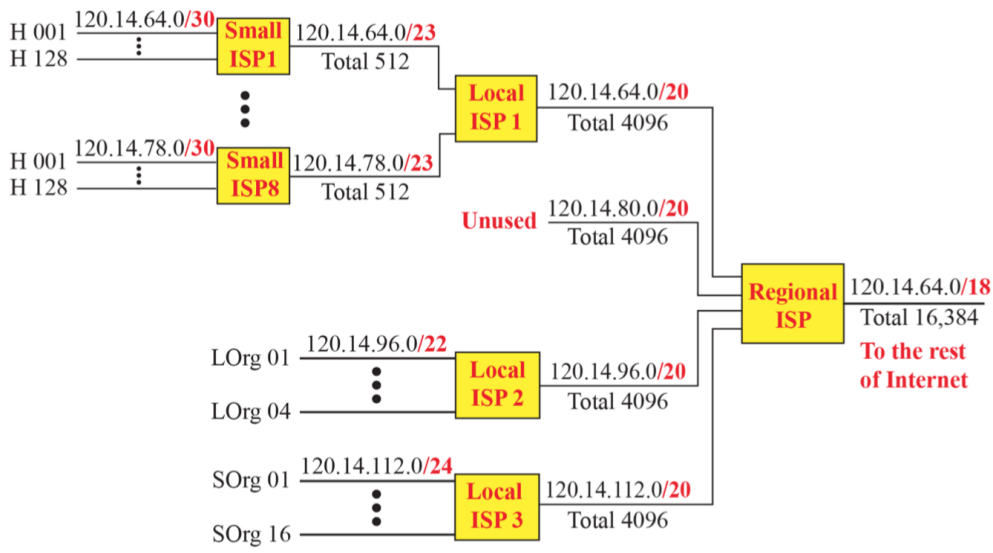
- Regional ISP: 바깥 네트워크와 처음 연결되는 곳으로 최초로 인터넷을 접속하는 지점
- Local ISP와 같이 한 지점에서 바깥 네트워크와 연결되어있는 뿌리가 존재하고 각각에 대해 네트워킹을 나눠줘야하는데 이를 서브 네트워킹이라 한다. 계층이 존재한다는 것을 확인할 수 있다.
(7) Forwarding based on destination address
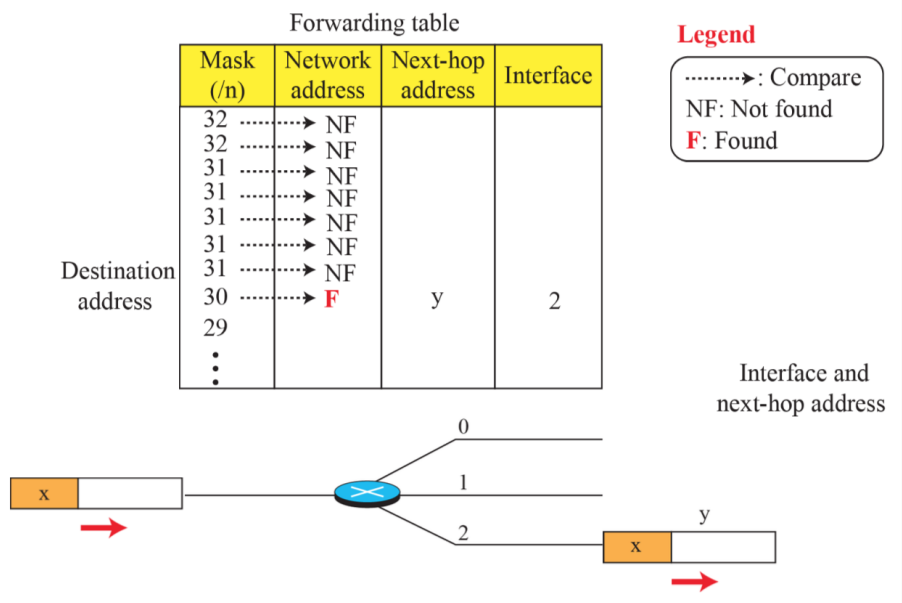
위에서부터 아래로 X를 찾아내려가고 F를 찾으면 해당 위치로 내보낸다. 굉장히 부하가 많다. 연결 설정 및 해제를 하지 않아도 된다.
(8) Forwarding based on label
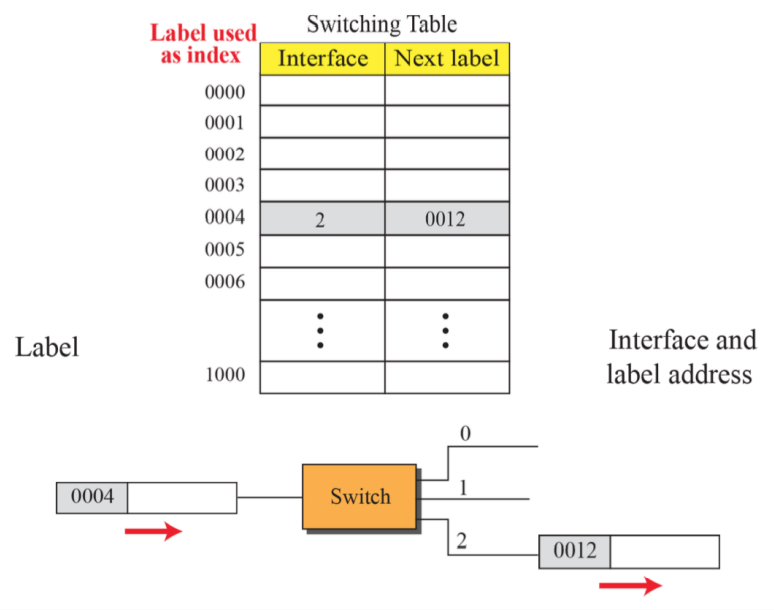
- 라벨은 테이블에서 검색하지 않는다. 라벨을 인덱스로 활용하여 이를 키값으로 취해 바로 interface를 얻어낼 수 있다. 이에 따라 lookup 기능이 없어진다. virtual circuit은 통신에서 보고 그 외에서는 자주 볼 일이 없다.
6. IP Protocol
네트워크 레이어로서 인터넷을 지탱하는 소프트웨어
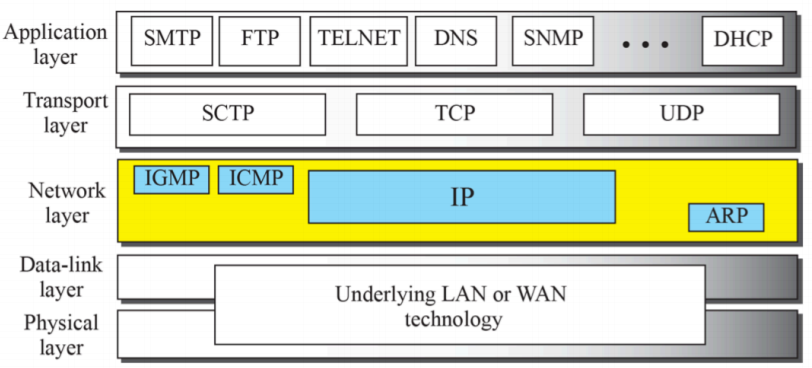
- tansport에서 TCP UDP를 가장 많이 사용한다.
1) Datagram format
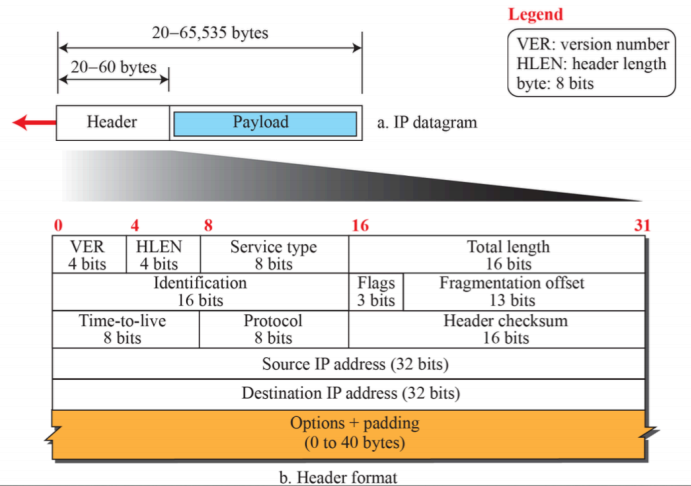
- IP protocol의 헤더는 가변적이다. 최소 20바이트에서 60바이트까지 갈 수 있다. 헤더가 붙고 payload가 들어간다. 최대 64kb까지 들어갈 수 있지만 실제로 지원하는 장비의 제한이 있기에 이정도까지 들어가기는 어렵다.
- 옵션을 통해 새로운 기능을 확장할 때 위에 있는 헤더를 제외하고 추가적으로 넣을 수 있다.
- 패딩은 32비트로 align 해야하지만 이게 맞지 않는 경우에는 추가적인 정보를 집어넣는 패딩을 할 수 있다.
- 어드레스는 각각 32 비트, time-to-live: 메세지가 어느 구간에서 루프를 돌 수 있고, 너무 많이 가는 것을 막기 위해 라우터를 지날때마다 값이 1씩 줄어들고 TTL이 0이되면 메세지는 삭제된다.
- IT 버전에 대한 버전 정보, 헤더 랭스, 데이터의 특성을 나타내는 서비스 타입이 존재
- 헤더에 대한 길이 뿐만 아니라 메세지 전체에 대한 길이가 존재한다.
2) Multiplexing
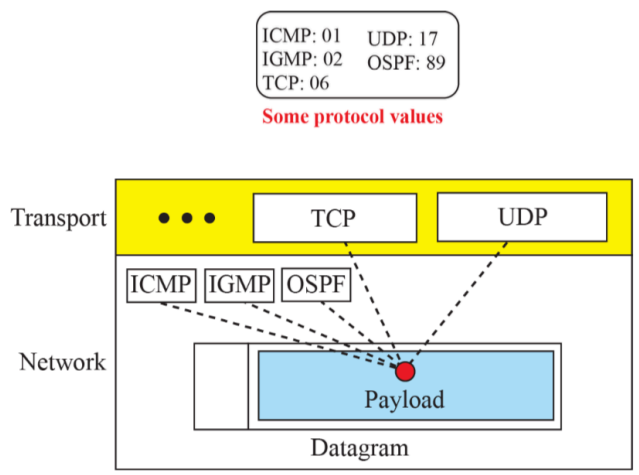
- layer4 정보를 위의 값을 통해 실어나름
- IP layer를 가장 아래에 깔고 여러 소프트웨어를 IP가 실어나름
- 프로토콜 필드를 위와 같이 명시할 수 있다.
- 하나의 IP 프로토콜 위에 여러 개의 프로토콜이 돌아갈 수 있다는 가정 하에 Multiprotocol을 얘기할 수 있다.
3) Fragmentation
- Ip 프로토콜은 서로 다른 유무선 네트워킹이 가능하다.
- layer 2는 layer1 을 반영한다. layer1이 안정적이면 layer 2의 프레임 사이즈가 길어도 되지만 안정적이지 않다면 사이즈는 짧아야한다.
- 옛날에는 버퍼도 작고 에러도 많았기에 1kb를 ip 패킷을 최대 사이즈로 해놓은 경우가 많다. 하지만 하나의 IP 패킷에 최대 64kb만큼 담을 수 있기에 이를 받았을 때 쪼개는 역할을 하는 것이 fragmentation이라 한다.
- 무선랜은 최대의 2계층 패킷 사이즈가 정해져있다. 유선은 8kb로 ip 프레임을 만드는 것이 흔하다.
- 기술적으로나 오래된 장치에 의해서나 전달받은 ip 프레임을 쪼개는 경우가 있을 수 있다. 이때 fragmentation이 수반되어야한다.
(1) maximum transfer unit
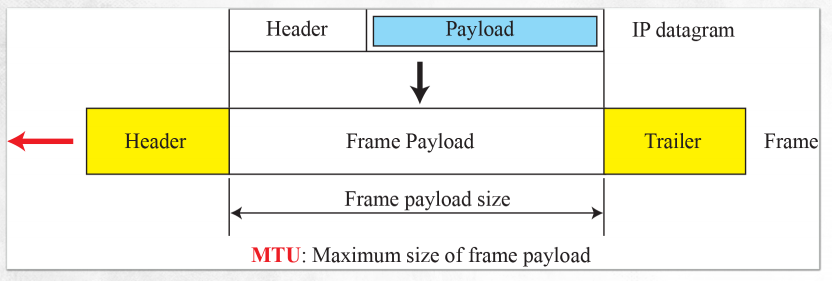
- 2계층에서 받을 수 있는 최대 사이즈는 MTU라고 한다. 이를 넘어가는 경우에는 쪼개서 전달받는다.
(2) fragmentation example
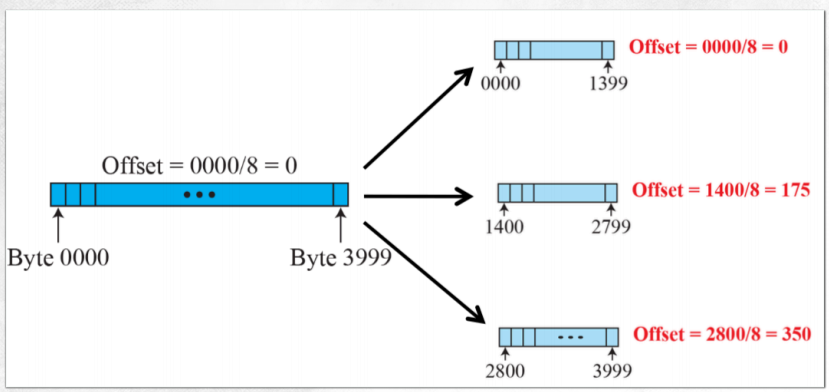
- 4000바이트를 세개의 바이트로 쪼개서 보낸다. 이를 data 필드라 하면 보내고자 하는 데이터의 시작을 0으로 환산하고 이를 8로 나눈다.
- 최초로 만드는 것은 무조건 0이다.
- 두번째 ip 프레임의 offset은 1400을 8로 나눈 값이 된다.
- offset이 0인 경우는 쪼개지지 않은 경우이거나 쪼개졌으나 첫번째인 경우를 의미한다.
(3) Detailed fragmentation example
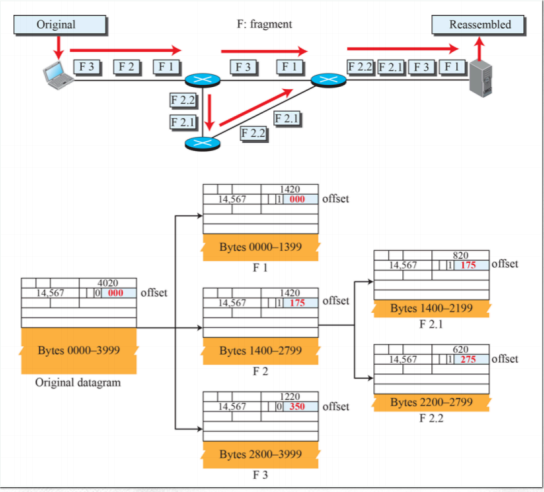
오리지널에서 프레임을 만들어서 내보냄
- 4000바이트짜리를 보냄
- 헤더의 빨간색은 offset이다.
- 쪼개질 때 ip의 다른 헤더값은 그대로 유지된다.
- 같은 것을 쪼갠 이후에도 쪼갤 수 있다.
- 대등관계로서 독립적으로 동작한다.
- 오래된 네트워크를 통과할 때 패킷이 나눠져서 통과한다.
4) IPv4에서의 보안
초기에는 보안을 신경쓰지 않았음
(1) 보안의 두가지 측면
i) 변질: 패킷을 바꾸거나 변질시키거나 쳐다보는 것
ii) 암호화: 별도의 레이어를 사용해 암호화를 사용한다. IP에서 보안은 IP sec에서 얘기를 많이하고, 일반적으로 IP에서 보안은 암호화를 얘기 많이한다.
(2) IPv4에서의 보안 이슈 및 특징
- packet sniffing, packet modification, IP spoofing
- public을 연결하지 않으면 보안을 신경쓰지 않는다. ex) kt 망 내에서는 보안에 큰 신경을 쓰지 않는다.
- 성능에 부담이 많이되기 때문에 해야하는 부분에서만 진행해야한다.
(3) ICMPv4
- IP 프로토콜이 동작하는지 관찰하고 관리하기 위한 프로토콜
- 인터넷을 컨트롤하기 위한 목적의 메세지를 실어나르는 프로토콜
- 리눅스 명령어들이 등장
- 지연이 얼마나 걸리는지, 관리하고 제어하며 에러 리포팅이나 본인이 필요한 정보를 물어오는 쿼리도 동작한다.
(4) Contents of data field for the error messages
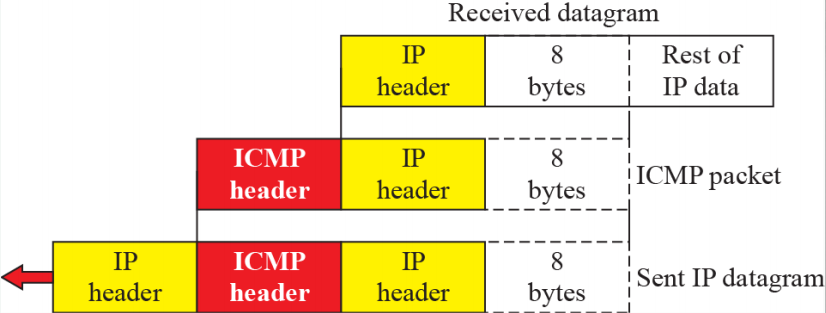
- IP 메세지를 하나 받는다면 IP 메세지의 데이터와 헤더를 포함해 ICMP 프로토콜에 줘서 IMCP가 헤더만 덧붙인다. 이후 도착지에 다시 보내준다. 일종의 루프백의 동작이다. -> 받은 것을 돌려주고 헤더를 추가한다.
- ICMP를 사용해 받은 것을 돌려준다.
- 네트워크나 라우터, 링크 등이 살았는지 죽었는지 체크 가능하다.
- ping and traceroute가 ICMP를 사용해 만든 어플리케이션이다.
- 운영체제에 따라 이름은 조금 달라질지 모르지만 모든 운영체제는 이를 포함되어있다.
5) ICPM에서 디버그를 위한 도구
(1) Ping
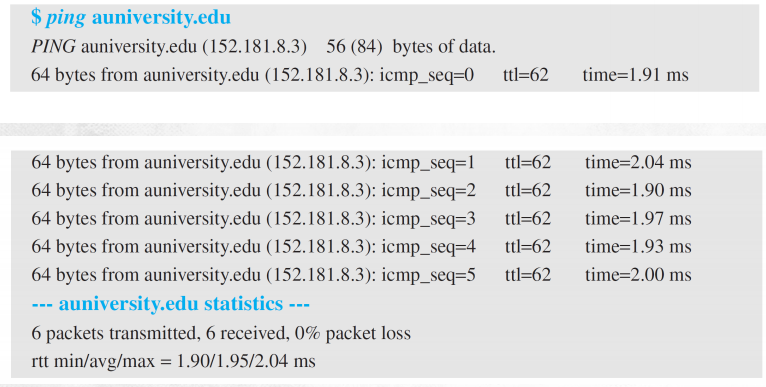
- 운영체제에 모두 있고 사용법도 동일하다.
- 주소값을 검색한다.
- PING을 시작하면 ICMP4를 통해 imcp4 메세지를 보내고 상대방 측에서 리턴을 한다. 또한 이를 반복적으로 진행해 상대방이 존재하고, 안정적으로 동작하며 줄이 모두 괜찮다는 것을 확인하고, 평균 속도 등을 알 수 있다. 상대방이 없거나 줄이 끊어지면 답장이 안올 수 있다. -> ping을 통해 서버가 살았는지 체크 가능하다. + 노드가 돌아가는지 확인 + 성능이나 지연 시간 등을 확인할 수 있다.
(2) Traceroute
ICMPv4를 개선하고 ping을 살짝 바꿈
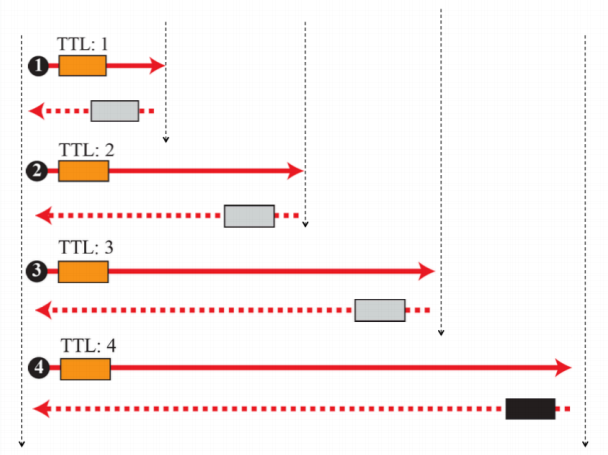
- 가장 마지막에 있는 것이 상대방 컴퓨터임
- TTL은 traceRoute에는 핑처럼 그대로 돌려준다. 이에 따라 중간에 거쳐야하는 것들을 하나하나 핑하기에 TTL의 숫자가 많아질수록 더 깊숙히 들어가는 것을 확인할 수 있다.
- 만약 ping으로 했을 때 응답이 안온다면 3장째 장치가 죽거나 가는 길이 끊어진 것이다.
- traceroute: 중간에 있는 것을 하나하나 점검하기에 상대방에 가는 경로에 있는 것들도 확인히 가능하다.
- 유닉스와 리눅스는 동작한다.
- 네이버와 같은 검색엔진 소프트웨어는 반응하지 않는다. -> 메세지가 뜬다는 것은 해당 소프트웨어를 켜놓기 때문에 과다한 트래픽이 발생하면 다운되기에 응답이 안되도록 막나놨다.
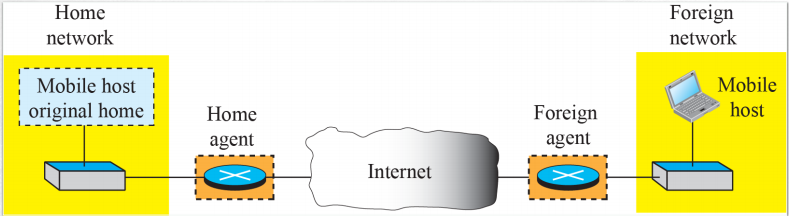
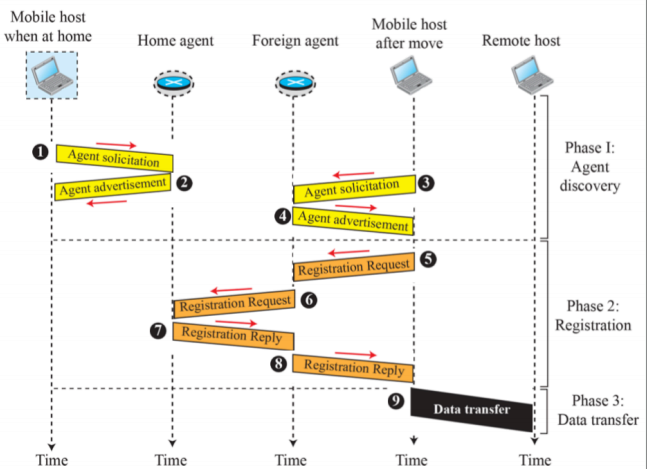
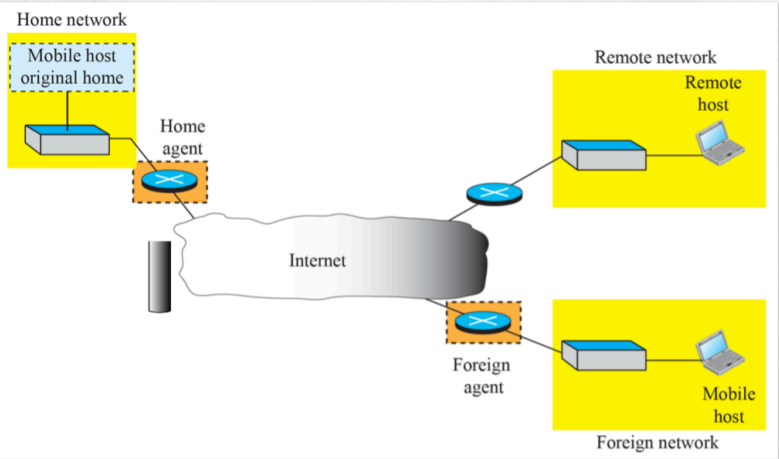
6) Mobile IP
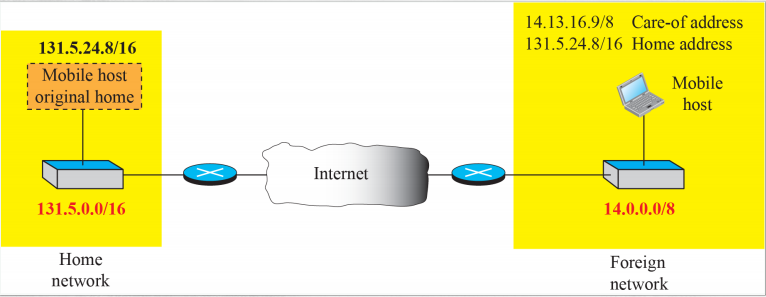
- 휴대폰을 생각해보자. 한국에서 개통한 스마트폰을 외국으로 갔을 때 loding이 뜬다. -> 우리가 해외에 있다면 로밍한 사업자로 IP를 옮겨준다.
- 지역과 상관없는 가상의 IP를 준다. 이에 따라 끊임없이 IP 어드레스를 반영한다.
- 추적이 안되고 보안상에서 문제가 발생할 수 있다.
'강의 내용 정리 > 컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크 (7), Transport layer 1 (0) | 2022.04.28 |
|---|---|
| 컴퓨터 네트워크 (6), Network Layer 2 (0) | 2022.04.28 |
| 컴퓨터 네트워크 (4), MAC/DLC (0) | 2022.04.28 |
| 컴퓨터 네트워크(3), DLC Layer (0) | 2022.04.28 |
| 컴퓨터 네트워크(2-2), MAC Layer (0) | 2022.04.14 |