2022. 4. 28. 16:23ㆍ강의 내용 정리/컴퓨터 네트워크
Transport layer 1
TCP/UDP를 중심으로 설명
1. Transport layer basic
Process to Process Delivery
- Physical layer와 Data link layer는 두 장치의 송수신을 배움 -> node to node 전송
- 통신 장비가 매우 많아지면 network layer로 했다. -> host to host 전송
1) Process-to-Process Delivery

- 앞서 4계층인 경우에는 컴퓨터 안에 있고, 어느 프로그램 중에 어느 프로그램이 목적지인지, 소스인지 확인하는 작업을 주로 한다. 그림을 보면 컴퓨터 내부에 있는 프로그램 중 소스프로그램이 존재하고 오른쪽의 프로그램 중에 데스티네이션이 있다.
- host 내부에 있는 어느 프로세스가 패킷을 받을지 정한다.
- 시작했을 때 인터넷이 node to node해 이어서 host to host를 진행한 뒤, process to process 전달을 지원한다.
- Process to Process 커뮤니케이션은 일반적으로 클라이언트/서버 아키텍쳐로 볼 수 있다.
- 클라이언트를 요청을 하고 서버는 요청을 처리해준다.
ex) 시간을 요청하는 소프트웨어와 시간값을 확인한뒤 알려주는 프로세스
- 통신을 위해 아래 네가지의 정보가 필요하다. -> 행위를 하는 주체와 시점에 따라 상대적으로 달라진다.
(1) Local host
(2) Local process
(3) Remote host
(4) Remote process
- host를 위해 네트워크 주소를 사용한다. 즉, source address는 Local host로 destination address는 remote host로 쓰인다.
- 하나의 컴퓨터 안에서 프로세스를 식별할 수 있는 고유의 주소도 존재한다.
2) Addressing
(1) Port number
- 호스트 내부에서 어느 프로그램이 통신의 대상인지 식별하는 것이 중요하다.
- transport layer는 특정 프로세스를 식별할 수 있도록 한다.
- MAC address, IP address가 각각 이전 계층에서 존재했는데 transport layer는 특정 프로그램을 지칭하기 위해 port number라고 부른다. 운영체제 위에 올라가 있는 형태이기에 운영체제가 프로그램에게 구멍을 뚫어서 통신을 가능케하는데 이를 port 번호라고 한다.
- 목적 포트번호를 통해 컴퓨터 내에 있는 프로세스를 찾아간다.
- 프로세스를 식별하기 위한 포트 넘버는 대부분 16비트로 정한다.
- UDP와 TCP는 대부분 16비트 숫자로 칭한다.
- Well-known port number: 많이 사용하는 경우에는 0번부터 1023번까지 번호를 미리 지정해놓고 대부분 고유하다. ex) HTTP: 80번
- Ephemeral port number 1024개 외의 나머지 값은 소프트웨어를 만드는 사람이 임의로 랜덤하게 정하는 경우가 일반적이다. 그러나 널리 알려진 소프트웨어 같은 경우에는 충돌을 피하기 위해 이를 피해서 만든다.

- 컴퓨터 간에는 IP Address를, 프로세스 간에는 port number를 사용한다

- 특정 컴퓨터를 찾기 위해서 IP Address를 사용했는데, 컴퓨터 내에서 중복되지 않게 프로세스를 찾기 위해 포트 넘버를 사용한다.
- 위에서 언급한 네 가지 정보가 있다면 어디로 보내는지 확인할 수 있다.
(2) Socket Addresses

- 4계층 이상에서 소프트웨어를 만드는 사람은 IP Address와 Port Number를 함께 설명하는 경우가 많다. 따라서 IP Address와 Port number를 합친 것을 socket address라고 한다.
- 어플리케이션이 외부 통신을 위해 운영체제에 구멍을 뚫는 것
(3) Multiplexing and Demultiplexing

- 여러 프로세스가 IP Address를 통해 다른 컴퓨터와 통신을 할 수 있다.
2) Connectionless Vs Connection-Oriented Service
(1) Connectionless
- 필요한 것을 필요할 때 보내고 연결 설정 및 해제가 필요없다.
- UDP
(2) Connection-Oriented
- 연결 설정 및 해제의 과정이 필요하다.
- TCP와 SCTP
3) Reliable Vs Unreliable
(1) Reliable
- 신뢰성이 보장되어야하는 경우 연결 지향적인 TCP와 SCTP를 사용한다.
- TCP는 혼잡제어도 들어간다.
- 신뢰성은 성능이라는 비용을 지불한다.
- 본인이 제공하고자 하는 서비스가 초고속인 경우에는 이 속도를 맞출 수 있는가에 대한 계산을 필요하다.
(2) Unreliable
- 에러검출 및 복구, 흐름제어, 혼잡 제어를 하지 않기에 연결리스의 UDP를 사용한다.
- 굉장히 빠른 초고속 서비스를 제공할 때 이를 사용하는게 좋다.
- 에러 대비 품질에 대해 정량적으로 비교할 수 있는데 이를 비교해 적절한 프로토콜을 사용하는 것이 좋다.
- 신뢰성이 많이 필요하지 않는 경우에는 UDP를 사용하는 경우도 많다.
4) 2계층에서 신뢰성을 보장했을 때 상위 계층에서도 신뢰성을 보장할 필요가 있을까?
무조건 필요하다. 왜냐하면 3계층 장치에서 16개의 인터페이스 중 15개의 인터페이스의 트래픽이 동시에 몰린 경우에는 버퍼가 쌓이고 loss가 발생할 수 있다. 이에 따라 컴퓨터 메모리를 관리하는 입장에서 메세지가 유실되는 경우가 발생할 수 있다. 즉, 2계층에서 신뢰성을 보장하더라도 3계층에서 신뢰성을 보장하지 못할 뿐더러 사람들이 만든 것이고, 신뢰성을 제한적으로 보장하는 경우가 많다. 이에 따라 transport layer는 신뢰성을 보장해야한다. 3계층은 대부분 신뢰성을 보장하지 못하고, 2계층도 와이파이나 초고속 인터넷은 제한적인 재전송이기에 신뢰성을 보장하지 못할수도 있다. -> 신뢰성을 보장해야하는 서비스라면 transport나 application layer에서 이를 검증해야한다.
5) Error control

- 버퍼가 차서 로스가 발생할 수 있다.
- 에러를 0으로 떨어뜨리는 데이터 링크 계층은 존재하기 어렵다.
- 따라서 위와 같은 에러가 발생할 수 있기에 신뢰성을 보장하는 transport layer를 사용할 수 있다.
6) Major Transport layer protocols

2. User Datagram Protocol(UDP)
Connection less 형식의 사용자의 데이터를 실어나르는 프로토콜
1) UDP란?
- 앞 패킷과 뒤 패킷의 관계가 없다.
- unreliable 프로토콜이다.
- 포트번호를 집어넣어서 어느 프로그램이 어느 프로그램에게 메세지를 전달하는가를 확인할 수 있다.
- 최소한의 오버헤드를 가지며 프로세스 식별할 수 있는 정보를 포함하고 있다. -> connectionless
- 신뢰성을 보장하지 않아도 되는 작은 메세지를 보낼 때 많이 사용한다.
- 작은 메세지를 상대방에게 보낼 때 유실이 될 수 있는 가정 하에 보낼 때 사용한다.
- 만약 대량의 데이터를 보내고 유실되면 다시 보내야하는 경우에는 TCP를 사용한다.
2) Well-known ports used with UDP

- 포트 넘버는 16비트이고 1024 아래 숫자는 미리 예약되어있고, 표준화되어있다.
- port number가 예약되어있는데, 이 중 대표격을 가져왔다.
- 13번 Daytime: 시간 값을 알려주는 포트번호
- 123번 NTP: 기계간에 시간을 맞출 때 사용
- 67~68번 BOOTPsc: 네트워크에 있는 장치 중에 원격으로 디스크를 접속해 해당 장치로부터 부팅을 할 때 사용
- 해당 포트번호는 사용할 수 없다.
3) Frame format

- 위의 네 정보는 모두 가지고 있어야한다.
- 프레임에 대한 길이값, 헤더가 망가졌는지 아닌지 체크할 수 있는 checksum을 가지고 있다.
- 소스 포트 번호와 목적 포트 번호가 프로세스를 식별하기 위한 용도로 제일 중요하다.

- UDP 헤더
- UDP 전체 길이인 16비트
- 패딩: 리저브드되어있거나 임의로 사용할 수 있는 부분
- UDP는 거의 정보가 없다.
- 하늘색은 IP 헤더이다.
- UDP의 목적은 어느 프로세스가 보냈는지에 대한 식별과 어느 프로세스가 받아야하는지에 대한 내용이 들어가야한다.
4) Operation
- Connection less 방식이며 모든 UDP 패킷은 독립적이다.
- 흐름제어나 에러 컨트롤이 없다.
- 포트번호를 포함한 헤더 필드를 통해 어느 프로세스가 보내고 어느 프로세스로 보내는지를 식별하는 것이 가장 주요한 기능이다. (encapsulation, decapsulating)
5) Queuing in UDP
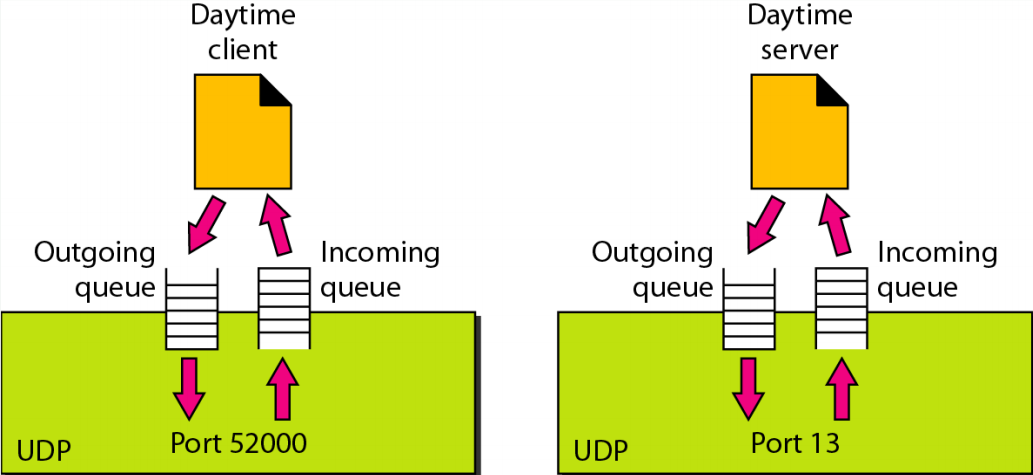
- 데이터를 보낼 게 있으면 outgoing queue에 쓰고, UDP는 필요할 때, 여유 있을 때 이를 읽어서 UDP 헤더를 붙이고 IP를 통해 전송한다.
- 클라이언트는 랜덤하게 포트 번호를 받고, 서버는 well-known port를 사용한다.
(1) Queuing ay client site
- Connection oriented 방식이 아니기에 선행되어야할 작업이 있다.
- 서버가 항상 클라이언트보다 먼저 동작하고 있어야한다. 이는 TCP도 동일하다. 하지만 UDP는 연결설정 과정이 없기에 서버가 없으면 데이터가 유실될 수 있다. TCP는 서버가 살아있지 않으면 연결설정을 하지 않기에 서비스가 개시되지 않기에 데이터 유실을 방지할 수 있다.
- 클라이언트에서 프로세스가 살아나면 본인이 사용해야하는 랜덤 넘버 기반의 포트 번호를 OS로부터 받아야한다. 클라이언트 프로세스가 포트 번호를 받으면 이를 소스 포트번호로 사용할 수 있다. 데이터 보낼 때 UDP 프로토콜에게 요청을 전달하면 UDP는 운영체제로부터 할당받은 포트번호를 기반으로 헤더를 만들어 5계층 이상에서 전달한 메세지에 UDP 코드를 붙여서 완성한다. 그리고 UDP 헤더가 붙은 것을 IP 계층으로 전달한다. 그러나 OSI 7 계층에서는 위에서 보내는 수신 버퍼와 아래로 보내는 송신 버퍼가 레이어 별로 존재했다. 따라서 UDP가 헤더를 붙인 데이터를 IP에게 전달하기 위해 UDP에서 IP 쪽으로 향하는 송신버퍼(outgoing queue)가 UDP 헤더를 가지고 있는 프레임을 집어 넣는 과정이다. UDP를 내리지 못할만큼 버퍼가 차면 5계층에게 경고를 줄 수 있다.
- 클라이언트는 UDP가 위에서 받은 패킷을 내리거나 IP에서 받은 패킷을 위로 올리는 과정을 처리한다.
(2) Queuing at server site
- 특정 포트를 열고 데이터를 기다린다.
- 운영체제의 도움을 받는다.
- 수신할 incomming queue, 트래픽을 내려보낼 outgoing queue를 통해 wellknown port를 사용해서 동작한다. 별다른 연결설정 없이 대기 상태에 있다가 문득 UDP를 사용해 본인에게 메세지를 보내는 것이 있다면 호스트인 IP 프로토콜이 UDP 패킷을 IP 레이어로부터 받는 incomming queue에 뭔가 있다면 목적 포트 주소를 보고 이에 해당하는 서버 어플리케이션에 전달한다.
- 클라이언트와 다를 바가 크게 없지만 먼저 살아있어야하고, well-known 포트를 사용해야하고 본인이 데이터를 받으면 IP 레이어로부터 받아서 destination port 주소를 보고 적절하게 전달하는 점이다.
- 작업 후엔 outgoing queue에 넣고, IP가 보고 끄집어 내는 작업을 한다.
6) Applications of UDP
- 필요할 때 보내고, 기다리다가 받는 단순한 동작을 한다.
- UDP는 bulk data를 안정적으로 보내야하는 파일 전송(FTP)에서는 사용하면 안된다. -> 변경되면 안되기 때문
- TFTP: 안정적인 네트워크에서 소량 데이터를 보내는 FTP에 대해서는 간헐적으로 사용 가능하다.
- 멀티 캐스트를 위한 전송 프로토콜로 사용할 수 있다. 하지만 이는 거의 존재하지 않고 이는 이론적으로 얘기한다. 방송을 보낼 때는 에러검출 및 복구를 하지 않기에 그냥 사용하는 경우도 있다.
- 라우터와 라우터 간의 통신에서 라우터는 정보를 계속 주고 받는다. 따라서 라우터는 주변 지식이 없기에 연결 설정 및 해제가 없다. 이에 따라 라우턴 간의 정보를 취득할 때에는 UDP를 사용하는 것이 일반적이다.
- SNMP(simple, network management protocol): 네트워크 장치가 많지만 알고싶은 정보의 양이 적을 때 주기적으로 관리자에게 보고하고, 데이터를 전송할 수 있기에 데이터가 크지 않고, 중요하지 않는 경우에는 UDP를 사용한다. 이런 경우에 TCP를 사용하면 데이터 링크 계층에서 제일 복잡한 알고리즘을 모두 동작하기에 프로세스와 메모리 부하가 크다.
3. Transmission Control Protocol(TCP)
1) TCP란?
- Connection oriented이고, virtual한 연결을 두 개의 TCP 사이에 연결한다.
- 에러 검출 및 복구, 흐름제어 추가
- 네트워크의 혼잡도를 검출하고 이를 방어하고자 한다.
2) TCP Services

- TCP와 주로 통신하는 프로토콜
- 13번 포트를 쓰는 Daytime와 67번을 쓰는 BOOTP는 앞쪽에서 UDP에서 나온 것을 확인할 수 있다.
- 그 외의 상당량이 UDP에서 나왔다.
- 상위 계층 어플리케이션과 독립적으로 동작한다.
- 하지만 20번과 21번은 대량의 데이터를 전달할 수 있는 내용이지만 이는 UDP에 없기에 이를 고려해서 어플리케이션을 개발해야한다. 즉, 어플리케이션과 transmission 계층은 서로 독립적이지만 이를 고려해 개발해야할 필요가 있다.
3) Stream delivery

- Virtual한 연결을 만들어서 파이프를 하나 뚫어 TCP 간의 정보를 주고받을 수 있다.
- TCP와 데이터링크 계층과 비슷하다. 데이터 링크 계층에서는 패킷과 프레임을 보내고, 메세지 시퀀스 번호(메세지를 쪼갠다.)를 1번, 2번, 3번과 같이 보낸다. TCP는 바이트를 흘러 보낸다. 따라서 바이트를 보내는 stream of bytes이다.
- 바이트를 주고받을 수 있는 Virtual 연결을 bytes stream으로 뚫는다.
4) Sending and Receiving Buffers

- Circular queue를 원처럼 만들어서 데이터가 저장되다가 쌓이면 공간을 초과하면 버퍼를 넘어 초과된다.
- 데이터를 보냈을 때 대기중이다. 응답이 없거나 잘못 보낸경우에는 재전송한다.
- 회색은 보냈는데 응답이 없고, 분홍색은 보낼 것, 하얀색은 위쪽으로부터 받을 것
- 버퍼의 단위는 바이트이다.
- TCP는 바이트 단위로 전송한다는 점이 매우 중요하다.
- 수신단은 메세지를 받아서 보관하고 있는데 바빠서 못가져간 not read와 하얀색 공간이 존재한다.
- 버퍼를 가지고 작업을 한다. + 버퍼 단위는 바이트이다.
5) Segment

- TCP에서 주고받는 단위는 세그먼트이다.
- 헤더가 붙고 5계층 이상의 프로세스가 주는 정보에 TCP 헤더를 붙여 IP 레이어에 전송한다.
- TCP의 전송은 TCP의 수신과 peer comunication을 하고, 주고받는 메세지에 따라 동작한다.
- 세그먼트가 없어진 것을 알기위해 순서가 뒤집어지거나, 안오거나, CRC 체크 등을 했을 때 제대로 안나오면 재전송을 한다.
- 데이터링크 송신단의 동작과 별 반 차이가 없다.
- 스트림 오브 바이트 -> 세크먼트로 바뀜
- 세그먼드는 분횽색으로 되어있는 경우 바이트이다. -> 헤더 안에 어떤 정보가 들어갔는 지를 보기위해
- 데이터 링크 계층에서는 송신단과 수신단의 헤더의 상응하는 값이 존재해야지한다.
- 1이나 n은 안에 있는 값을 떼서 헤더에 바이트 단위로 보낸다.
6) Full Duplex Servuce
- 기능적으로 동시에 보낼 수 있다.
- 보내면서 받을 수 있다.
- Piggybacking: 데이터에 컨트롤 정보를 얹는 것.
- 상대방에게 연결요청 및 동의하면 연결설정을 하고 버퍼 만들어서 송수신을 한다.
- 보낼 데이터가 없으면 연결해제한다.
- 데이터링크 계층에서와 매우 유사하다.
7) Byte number
TCP는 바이트를 실어나른다.
Why?
- TCP는 세그먼트 번호를 쓰는 필드가 없다. -> 보내는 입장에서 시퀀스 번호가 있고, 받는 쪽은 ack를 통해 응답을 한다. 그러나 이것은 세그먼트와 상관없이 바이트 단위를 센다.
- TCP 필드에서 만약 보내고 싶은 바이트가 6000개라면 어떤 작업을 하다보니 시퀀스 번호가 1057일 때 이를 가지고 시작하는데 이 단위가 바이트이다.
- 1057이라는 시퀀스 넘버를 가지고 1000바이트만 보내면 1057에서 2056이 마지막으로 가는 바이트의 번호가 된다. 이후 1000개를 보내는 경우에는 2057이라는 시퀀스 번호를 가지고 날라간다.
- 세그먼트를 보낼 때 세그먼트의 시퀀스 번호가 세그먼트의 번호를 의미하는 것이 아니라 바이트를 의미한다.
- 내가 보낼 보내는 바이트 중 첫번째 바이트의 시퀀스 번호가 세그먼트의 번호가 된다. 따라서 시퀀스 번호와 ack 번호가 있긴 하지만 바이트 단위로 센다는 점이 포인트이다.
- 에러 검출 및 복구를 할 때 세그먼트가 아니라 바이트의 개수를 가지고 한다.
- 데이터 링크 계층은 연결 설정 과정에서 시퀀스 번호를 보통 0으로 설정하지만 TCP는 랜덤 번호를 가지고 활용한다. 보안을 위해 랜덤 넘버를 사용한다.
- 보내는 데이터의 양을 바이트 단위의 입장에서 시퀀스 넘버를 부여하는 것과 랜덤 번호를 처음 시퀀스 번호로 사용한다는 점이 매우 큰 특징이다.
- 세그먼트의 시퀀스 넘버는 전달하는 바이트 중의 첫번째 바이트의 시퀀스 넘버가 된다.
- Acknowlegement number는 마찬가지로 존재한다. 데이터 링크에서는 받고자하는 n+1번째 메세지를 보냈지만 TCP는 단위만 바이트로 바꿔서 보낸다.
8) TCP 세그먼트 포맷
(1) TCP 세그먼트 포맷

- checksum, 샌딩 넘버에 해당하는 시퀀스 넘버, acknowledgment 번호가 존재한다. -> 재전송을 위해 사용한다.
- HLEN: 헤더 랭스, Reserved 6비트는 표준에서 용도를 정하지 않기에 사용하고 싶으면 쓴다.
- URG, ACK, PSH, RST, SYN, FIN은 1비트씩있는데 연결 설정 및 해제, 에러검출을 한다.
- 데이터링크에서 슬라이딩 윈도우를 하면서 윈도우 값을 상대방에게 알려주고 데이터 값을 더 보내~ 하는 흐름제어와 마찬가지로 수신 버퍼의 사이즈를 알려주는 window size가 존재한다.
- urgent pointer 존재
- 보내고 받는 것에 대한 번호가 존재한다.
- 추가적인 옵션을 넣을 수 있고, allign이 안되면 이를 위한 padding field도 존재한다.
(2) control field

- 각 비트에 1을 넣으면 해당 필드 실행이다.
- SYN: 시퀀스 번호를 동기화한다. -> 연결 설정 요청
- FIN: 연결 해제 요청
- RST: 오동작 상태가 됐을 때 초기화값으로 바꾼다.
- ACK: acknowlegment number를 보낼지 말지를 정한다.
9) TCP는 Connection oriented이다.
(1) 특징
- TCP에서의 연결 지향은 virtual하게 진행한다.
- TCP의 path를 통해 정보를 주고 받는데, 에러검출 및 복구에 대한 재전송을 동작한다.
- TCP는 IP를 사용할 수 있다. -> 그러나 IP는 connection less이고 이는 신뢰성이 보장되지 않기에 IP 위에서 TCP에서 많이 사용한다.
- 4계층이 1계층을 직접 다루는 것은 불가능
(2) connection establishment

- TCP는 full-duplex를 동작하는 프로토콜이며 연결요청을 하기 위해 보내는 과정이 있다.
- 이를 위해 승인을 하면 주고받는다.
- 클라이언트와 서버가 존재한다.
- 시간은 위에서 아래로 흐른다.
- 연결 설정은 클라이언트가 요청해서 서버쪽으로 보내는데 SYN은 무조건 존재해야한다.
- 서버는 SYN에 대한 응답으로 ACK와 SYN을 보내며 클라이언트는 ACK를 보낸다.
- 최초의 보내는 바이트 시퀀스를 랜덤으로 만들기에 이때 8000과 15000은 랜덤하게 만들어진다.
- ACK는 1씩 증가한다.
- 위의 과정을 거쳐 연결요청을 수락한다.
- 클라이언트와 서버는 모두 SYN을 보내 duplex한 통신링크가 만들어진다.
(3) SYN Flooding Attack
- 서버가 포트를 열고 대기하고 있기에 SYN 메세지를 무지하게 많이 보내면 수신단의 버퍼와 프로세스를 많이 띄워야하기에 서비스 불능상태가 될 수 있다. 이를 악용해서 공격을 가하는 행동이 발생할 수 있고 이를 SYN Flooding Attack이라 한다. 보안업체는 특정 서버에 데이터가 많이 모이면 이를 차단하기도 한다.
(4) Data transfer

- 8001번째 바이트 데이터를 보낸다. 이후에는 9001로 시퀀스 넘버가 바뀐다.
- 데이터는 1000개 단위로 보내지는 것을 확인할 수 있다.
- piggibacking인 것을 확인할 수 있다.
- Full duplex이다.
- 데이터링크 계층에서 윈도우 사이즈를 알려주는 스킴과 동일한 내용도 들어간다.
i) Pushing data
- 어플리케이션이 sending에게 요청해 바로 보내라는 것이다. 즉, 윈도우가 찰 때까지 기다리지 않고 보내는 것을 의미한다. 원래 상위계층에서 보낸 것을 하위 계층에서 바로 보내지는 않고, 링크의 효율을 위해 시간 단위별로 모아서 쏜다. Push는 이를 모으지 말고 바로 쏘라고 의미한다.
- 실제로 필드로는 살아있고 쓸 수 있지만 사용한 사례는 거의 없다.
ii) Urgent Data
- 수신에서는 수신 버퍼에 넣고, 수신 순서가 맞는지 확인하고 오래 기다리지만 그렇게 하지 않고 상위계층으로 바로 올린다. Urgent에 대한 위치값을 그대로 가지고 있다.
- 실제로 필드로는 살아있고 쓸 수 있지만 사용한 사례는 거의 없다.
-> 위와 같이 긴급하게 보내야하는 경우에는 UDP를 짜는 경우가 일반적이다.
(5) Connection termination
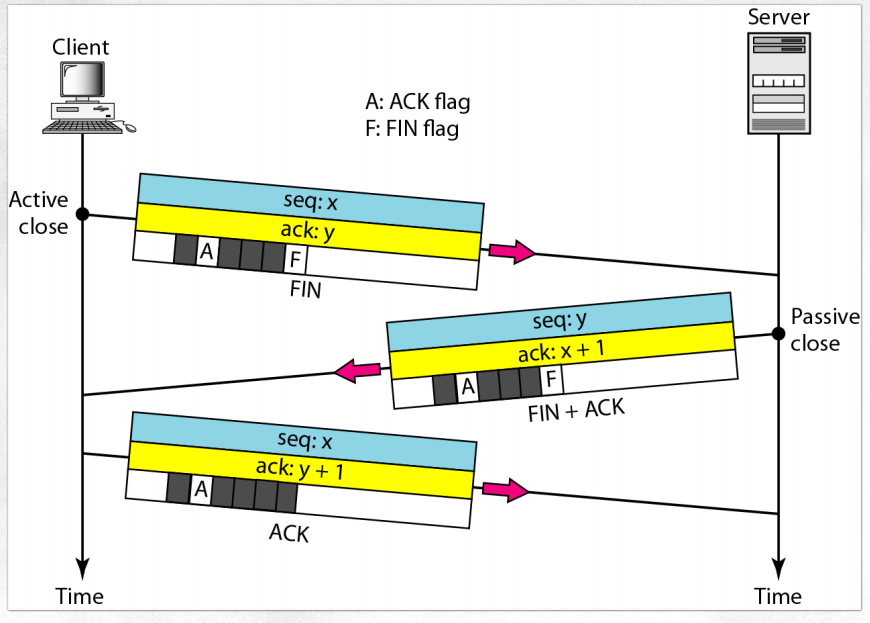
- FIN: 연결 해제를 한다.
- 대게 클라이언트가 먼저 끊는다. 이후에는 서버에서 FIN을 보내 연결해제를 한다.
- 이후에는 각자 버퍼 해제하고 프로그램 종료를 한다.
- 그러나 클라이언트는 보낼 게 없더라도 서버에서 보낼 것이 남아있다면 Half close가 나올 수 있다.
i) Half close

- 서버는 클라이언트에게 꾸준히 데이터를 보낼 수 있고, 클라이언트는 ACK를 보낼수는 있다. -> 데이터를 못보내지만 ACK는 보내는거 가능
- 모든 것을 다 보낸 이후 FIN을 해서 종료할 수 있다.
(6) An example of flow control

- 클라이언트가 서버로 SYN 연결하고, sq 넘버를 랜덤으로 만든다. -> 서버가 이를 받고 ack를 보내면서 syn도 보낸다
- 서버는 수신에 대해 버퍼를 800바이트만큼 할당한다. 이후 해당 사이즈를 세그먼트로 보낸다.
- 받았다고 해서 바로 올리지 않기에 rewd는 줄어든다. 또한 현재 rewd도 보내준다.
- 수신 버퍼의 사이즈에 따라 슬라이딩 윈도우를 조율한다.
- 수신 버퍼의 사이즈가 늘어나도 이를 따로 보내주기도 한다.
- 이를 통해 흐름 제어를 한다.
(7) Normal operation

- 에러가 발생하지는 않지만 추가적으로 타이머를 사용해 디테일하게 에러가 나지 않을 때의 동작을 설명하고자 한다.
- 클라이언트에서 ack를 받으면 타이머를 켜지만 이는 재전송을 위한 것이 아닌 ack를 몰아서 보내기 위해 사용한다.
- 간헐적인 데이터를 주고받을 것이라 생각했고, 받을 때마다 응답하지 않기에 느리고 효율이 떨어지는 링크를 최적화해서 사용하고자 한다. 응답을 받을 때마다 하나씩 전달하면 비효율적이니 ACK를 모아서 보낸다. -> ACK-delaying를 통해 500ms이내에 보낸다.
- 응답을 바로하지 않으면 쏠게 많지만 보내지 못할 수 있다. 즉 대량의 데이터를 보낼 때 통신 효율은 떨어진다.
- 긴급한 메세지를 보낼 때는 효율이 떨어진다. 요즘은 안맞는 부분이 존재한다.
(8) Lost segment

- 701에서 800의 데이터가 없어지면 801 ~ 900 데이터를 보내면 서버에서는 ACK 701을 보낸다. 이후 타이머가 지난 뒤에 701을 나중에 보내주고 이를 재전송해준다.
(9) Fast retransmission

- 데이터를 잘못 보내 동일한 ACK를 반복적으로 보내지면 타이머를 리스타트하고 재전송한다. -> 대량의 데이터를 주고받을 때 빠르게 에러 검출 및 복구를 동작할 수 있다.
- 초기전에는 없었지만 이후 개량되었다. 이를 활용하기 위해서는 추가적인 공부가 필요하다.
(10) Lost acknowledgment

- Ack가 없어질수도 있다.
- 재전송 타임 이내에 Ack가 사라지고 이후에 보내더라도 상관없다.

- 재전송 시간이 지나고도 ack를 받지 못해 클라이언트에서 데이터를 다시 보내게되면 ack를 다시 보낸다.
(11) 네트워크 연결 설정 후 데이터 주고받는 방법
(i) Slow start, exponential increase

- 수신 버퍼를 고려하는 것이 아닌 클라이언트와 서버 사이에 있는 많은 연결이 존재해 네트워크에 부하를 크게 주지 않으면서 동작하는 방식이다.
- 연결설정을 하고 첫번째 데이터가 나가는 순간부터 적용한다.
- 큰 데이터를 보내면 네트워크의 부하를 야기한다.
- 수신단의 수신 버퍼를 상관없이 보내는 양을 정하는 방법이다.
- Ack가 올 때까지 하나의 세그먼트만 보낸다. -> congestion window(리시브 윈도우 상위 계층에 존재하므로 리시브 윈도우가 있더라도 congestion window가 없다면 보낼 수 없다.) -> 시간이 지나 Ack를 받는다. 그러면 cwnd의 사이즈는 2배가 되고, 위의 과정을 매번 거친다. 즉, 쏘고 상대방이 잘 받으면 cwnd를 매번 2배씩 늘린다.
(ii) Congestion avoidance, additive increase

- 하나씩 늘린다.
(iii) Example of Tabo TCP

- Slow start와 Congestrion avoidance를 합친다.
- 8에서 에러가 발생한다. -> 지연이 발생하거나 오버플로우가 존재하는 경우가 많다.
- 시간이 지나면 slow start를 한다. 에러가 발생하면 congestion window를 내리고 slow start threshold level을 설정한다. 이에 따라 가장 마지막으로 성공한 congestion window의 값을 threshold 값으로 가지고 해당 값까지 2배로 올린다. 이후 threshold 값에 도달하면 1씩 증가한다.
- 3dupACKs는 위에서 본 3개 연속 ACK가 온 경우를 의미한다. 이후에는 Threshold는 이전에 올라간 것의 반으로 설정한다.
- 하지만 일관된 품질을 제공하지 못한다.
- 네트워크의 에러가 드문드문 발생하면 위와 같이 사용하는 것은 별로이다.
(iiii) Example of Reno TCP

- 네트워크는 잘 설계되어있지만 드문드문 혼잡구간이 발생할 수 있기에 3 dup acks는 cwnd를 조금만 내려서 다시 올린다.
- 다양한 버전이 존재하기에 이를 구현하기 위해선 깊게 공부해야할 필요가 있다.
(iiiii) Additive increase, multiplicative decrease

'강의 내용 정리 > 컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크 (9), HTTPS and SIP (0) | 2022.06.09 |
|---|---|
| 컴퓨터 네트워크 (8), Transport Layer 2 (0) | 2022.05.24 |
| 컴퓨터 네트워크 (6), Network Layer 2 (0) | 2022.04.28 |
| 컴퓨터 네트워크 (5), Network Layer 1 (0) | 2022.04.28 |
| 컴퓨터 네트워크 (4), MAC/DLC (0) | 2022.04.28 |