2022. 5. 2. 17:43ㆍ강의 내용 정리/자료구조
Linked Structured
1. Linked Structure을 활용한 Stack
1) ADT의 장점
내부적으로 사용하는 자료의 유형을 변경할 수 있다.
- ADT의 장점은 사용된 구현 유형을 변경할 수 있다는 것이다.
2) (동적) 배열 구현 시 발생할 수 있는 문제점
자료구조의 최대 크기가 정해져있다.
- Stack의 (동적) 배열 구현에는 단점이 존재한다. Stack의 최대 크기는 매개변수로 생성자에 전달한다. 이에 따라 배열의 크기를 초과하는 데이터를 삽입해야할 때는 문제가 발생할 수 있다. 따라서 데이터의 입력 예측이 어려운 경우나 예측을 벗어난 데이터가 입력된 경우에는 배열이나 동적배열을 사용할 때는 문제가 발생할 수 있다.
3) (동적) 배열 구현 시 문제 해결
링크드 리스트를 통해 사전에 자료구조의 최대크기를 정하지 않을 수 있다.
- Stack에 push될 때 각 Stack 요소에 대한 공간을 동적으로 할당할 수 있다. 이에 따라 메모리를 동적할당하는 동작과 데이터를 연결하는 동작이 수반된다. 데이터는 동적할당했기 때문에 heap 영역에 저장된다.
- push할 때 데이터를 동적 할당했기에 pop할 때도 delete를 해야한다. 또한 IsEmpty함수가 topPtr == NULL이기에 delete할 때 포인터 또한 null로 초기화하는 동작이 필요하다.
- 동적할당을 하기에 메모리가 초과했을 때 new를 해서 동적할당을 하면 NULL이 될 수 있다. 이를 고려해 ISFULL을 체크할 수 있다.
4) Linked Structure를 사용했을 때의 단점
- 랜덤액세스가 어렵고, 어떤 데이터를 찾기 위해선 이전 요소에 연결되어있는 것을 확인해야한다. 이에 따라 검색 및 정렬 등의 연산 속도가 느리다. 즉, 전체 요소에 대해 탐색적인 요소가 필요하면 연산 속도가 느리다는 단점이 있다.
- 일반적인 Stack 구조에 비해 데이터 삽입이나 삭제에 대한 연산 속도는 크게 차이나지 않는다.
- 파이썬에서는 배열 형태로 문법을 제공하지만 내부에는 리스트로 구현되어있기에 인덱싱을 할 때 연산 속도가 느리다. 배열을 사용하기 위해선 numpy를 사용할 수 있다.
5) Linked Strutured를 활용한 Queue
- 위와 같이 비슷한 방법으로 구현할 수 있다.
2. Linked List
1) Unsorted Linked List
- 함수를 더 호출하는 경우에는 오버헤드가 더 발생할 여지가 있다. 단 명시적으로 inline을 사용해 함수의 헤더부분에 붙여준다면 함수를 복사 붙여넣기를 하기에 오버헤드를 줄일 수 있고, 묵시적으로 클래스의 선언 부분에 함수의 정의를 괄호 열어서 적어주면 된다.
2) Sorted List
- 정렬된 링크드 리스트에선 데이터를 삽입할 때 내부 정렬이 유지되어야하기에 이를 고려해야하지만 반면 데이터를 삭제할 때는 큰 문제가 없다.
- 단, 링크드 리스트에서 데이터를 삽입할 때 앞 뒤 노드를 비교해야하기에 하나만 탐색한다면 어느 위치에 삽입해야하는지 알 수 없다. 이에 따라 predLoc의 변수를 사용해 이전 노드를 확인한다.
- 가장 마지막에 삽입되는 경우 또한 동작 부분에서 크게 다른 부분이 없다. 단, 이를 고려해야하기에 location이 NULL이 아닐때만 반복하여 이동하는 것을 moreToSearch를 통해 저장하는 것이 중요하다.
- 링크드 리스트는 중간에 데이터가 삽입되는 경우에 사용하기 좋다. 이에 따라 단순히 동적 배열에 따른 사이즈 크기를 늘리는 방식을 넘어서 더 중요한 의미를 가지고 있다. -> Stack과 Queue에서 Linked Structure을 사용하는 것과의 차이점 파악하기!
3) Generic의 장점
- 코드의 재사용성적인 측면에서 장점이 있음
- 프로젝트의 크기가 커지는 경우 Generic 하지 않은 경우에는 빌드하는데 수정사항이 반영되는데 매우 오래걸려서 시간이 엄청 오래걸릴 수 있음
3. Lists Plus
1) Circular Linked List
(1) 배열 형태의 자료구조
- 배열 형태로 자료를 다루는 방식은 이미 정의가 되어있음
- 링크드 리스트는 값과 다음영역을 가리키는 포인터가 있는 노드 객체를 포함하고 있다.
(2) Circular Linked List
- 일반적인 queue에 비해 Circular queue는 데이터를 삽입, 삭제할 때 오버헤드를 줄일 수 있다는 장점이 있다. 이와 비슷하게 Circular linked list를 사용하면 currentPos를 사용해 데이터를 순회했을 때 매번 리셋을 하는 등 불필요한 과정을 없앨 수 있다. 이에 따라 리스트의 마지막 노드를 첫번째 노드를 가리키도록 하면 Circular linked list를 구현할 수 있다.
- 접근성이나 데이터의 활용을 위해 Circular linked list와 같이 노드의 앞 뒤에 대한 포인터를 두는 double linked list 등을 구현할 수 있다. 단, Circular linked list와 Doubly linked list는 모두 레코드 하나 당 저장 공간을 더 포함시키기에 연산을 할 때의 연산 등이 추가되는 경우가 존재한다.
2) Doubly Linked List
(1) Doubly Linked List
- 부모와 자식을 모두 가리키는 데이터를 모두 고려해 데이터를 삽입 삭제해야한다.
- 포인터가 두개씩 들어가기에 데이터를 삽입할 때 앞 뒤의 요소들을 모두 꺼내는 작업이 필요하다.
- Circular Linked List로 구현도 할 수 있다.
(2) 헤더와 트레일러 노드
- 헤더 노드에는 가장 작은 키값을 가지고 list 시작 부분에 위치한다.
- 트레일러 노드에는 가장 큰 키값을 가지고 list 끝 부분에 위치한다.
- 헤더와 트레일러 노드를 사용하지 않는 경우에는 리스트에 데이터가 없는 상황에서 삽입/삭제를 동작할 때 현재 아이템이 내부에 존재하는지 확인해야한다. 하지만 첫 삽입 이후에도 리스트에 데이터가 존재하는데도 불구하고 데이터를 삽입/삭제할 때마다 아이템이 내부에 존재하는지 확인하는 과정을 수반해야한다.. 따라서 헤더와 트레일러 노드를 생성자를 통해 생성하는 경우에는 위의 연산을 구현할 필요가 없다. 이에 따라 중간에서 데이터가 삽입되고 삭제되는 것만 구현하면 된다. 이를 위해 노드 두개에 대한 메모리를 통해 연산 횟수를 훨씬 줄일 수 있다.
(3) Doubly Linked List 구현
- itor에서 NotNull 함수는 Next 함수 내부에서 사용하는 식으로 구현해야한다.
- Iterator는 DoublySoredLinkedList를 인자로 전달받는다.
(4) 생성자에서 {} 내부적으로 코드를 작성하는 것과 초기화 리스트의 차이점
- 클래스 내부적으로 다른 클래스를 포함 관계, 상속 관계로 가지고 있는 경우에는 초기화 리스트를 사용해야 한다.
- 멤버 데이터는 선언과 대입이 다르기에 대입 연산자가 호출된다. 하지만 생성자를 통해 데이터를 입력하는 클래스의 객체에 대해서는 대입 연산자를 사용하면 생성자를 호출할 수 없기에 문제가 발생한다. 이를 해결하기 위해 초기화 리스트를 사용하면 포함관계인 클래스에 대해서는 생성자를 호출하여 객체를 사용할 수 있다. 따라서 포함관계인 경우에는 초기화 리스트를 사용해야한다.
- 또한 상속을 받는 경우에도 초기화 리스트를 사용해야한다. 보통 부모 클래스의 데이터를 Private으로 작성하는 것이 일반적인데, 자식 클래스에서 이를 접근해야하는 동작이 필요할 수 있다. 이에 따라 초기화 동작이 필요하다. 이를 위해 초기화 리스트를 통해 부모 객체의 생성자를 호출해야한다. 만약 {} 안에서 부모 생성자를 호출한 경우에는 객체가 하나 생성되었다가 사라지기에 멤버 변수를 사용할 수 없다.
3) 동적할당을 동해 클래스 객체(자료구조)를 pass by value 할 경우는?
(1) Pass by value
- 스택을 실제로 활용할 때는 내부에서 배열, 링크드 리스트로 구성되어있는지를 알 필요는 없다.(추상화)
- 동적으로 연결된 스택과 같이 클래스 객체를 값 전달(pass by value)로 사용하는 함수가 호출되면 문제가 발생할 수 있다.
- pass by value는 shallow copy(bitwise copy)를 진행하는데 포인터는 메모리 주소의 값을 그대로 복사하기에 문제가 발생할 수 있다.
- pass by value를 사용하는 함수로 호출한다면 포인터에 탑포인터의 값을 저장한다. 이에 따라 pass by value로 전달한 값을 바꿀 수 있다. 예를 들어 pop함수를 수행한다면 함수 내부로 전달된 값에만 pop하고 실제 데이터에도 pop이 되지만 유효하지 않은 데이터를 가리키게 된다. 따라서 dangling 문제가 발생한다.
(2) Dangling 문제
- 메모리 문제는 두 가지의 문제가 존재한다. 메모리 문제와 Dangling 문제이다. Dangling은 유효하지 않은 주소를 가리키는 것을 의미한다.
- 즉 pass by value의 디폴트 방법을 활용해 동적 데이터를 보내는 것은 좋은 방법이 아니다.
- 이를 방지하기위해 딥카피(logical copy)를 사용하는 복사 생성자를 정의해야한다.
(3) Dangling 문제를 방지하는 방법
- 딥카피를 사용한 복사 생성자를 정의해 문제를 해결해야한다.
- 딥카피는 자체 사본을 저장하기에 메모리 상에서 공간을 따로 만들어야한다.
- 따라서 동적 메모리 할당한 데이터에 대해 딥카피를 수행하는 복사 생성자를 작성해야한다.
(4) 복사 생성자
- 복사 생성자는 생성자와 마찬가지로 사용자가 명시적으로 호출하지 않고, return type이 없다. 또한 복사 생성자는 깊은 복사를 위해 pass by referece로 전달받아야한다.
ex) 파라미터 리스트를 통해 생성자를 구분할 수 있다. 만약 두가지 다른 생성자를 모두 만족하는 파라미터 리스트를 전달한 경우에는 에러가 발생한다.
- 복사 생성자를 만드는 파라미터는 pass by reference를 파라미터로 전달받으면 되기에 formal parameter로 헤더에 복사 생성자를 구현해야한다.
(5) 복사 생성자가 호출되는 경우
i) pass by value로 객체를 파라미터로 전달할 때 (actual parameter로 전달한다.)
ii) 선언과 동시에 객체 변수를 초기화하면서 다른 객체를 대입할 때
iii) 함수의 return value로 객체를 반환할 때 복사 생성자가 묵시적으로 호출된다.
ex) 예외처리에서 클래스의 객체를 리턴 타입으로 반환했었음
(6) 복사 생성자가 호출되는 경우와 대입 연산자가 호출되는 경우
(6-1) 복사 생성자가 호출되는 경우
- 선언과 동시에 대입을 하는 경우에는 복사 생성자가 호출된다.
(6-2) 대입 생성자가 호출되는 경우
- 이미 선언이 된 것에 대입을 하는 경우에는 대입 생성자가 호출된다.
(7) 동적할당을 하는 클래스의 멤버 중 포인터가 있는 경우 주의 사항
- 다시 돌아와서 위와 같이 shallow copy 등의 문제 때문에 멤버 중에 포인터가 존재하는 경우 생성자와 복사 생성자, 소멸자를 고려해야한다.
- 함수 내에서 복사 생성자를 통해 객체를 생성하더라도 delete나 프로그램 종료를 할 때만 데이터가 사라지는 것은 마찬가지이다. 이에 따라 함수의 스코프가 끝나면 새로 만든 객체의 메모리를 지우기 위해 소멸자를 통해 삭제해야한다.
문제 1) 포인터를 가지고 있는 클래스에서는 생성자, 복사 생성자, 소멸자를 구현해야한다. o / x?
x -> 포인터를 가지고 동적할당을 하는 경우에 생성자와 복사 생성자, 소멸자를 구현하는 것이 중요하다.
cf) 묵시적과 명시적
- 묵시적 예시: int a = 3.3 라고 적지만 3.3을 묵시적으로 int로 형변환해서 대입할 수 있다.
- 명시적 예시: int a = int(3.3)
- 어떤 상황에서 이것을 호출하라고 코드 상으로 기술하는 것이 명시적, 규칙에 따라 알아서 호출되는 것이 묵시적
(8) 대입 연산자
- 얕은 복사가 기본으로 사용된다.
- 클래스의 동적 데이터에 대해 멤버 변수 포인터가 있다면 대입연산자를 오버로드해서 깊은 복사를 사용할 수 있도록 해야한다.
- 즉, 복사 생성자와 대입 연산자 모두 오버로딩을 해야한다.
4) 객체 지향 언어 복습
(1) 연산자 오버로딩 가이드
- 재정의 할 수 없는 연산자: :: . sizeof ?:
- 삼항 연산자와 if else의 차이점: 삼항 연산자에서는 수행 후에 연산의 결과를 그 위치에 반환한다. 반면 if else는 분기를 만들어서 확인한다. -> 대입을 사용할 때는 삼항 연산자를 사용하는 것이 좋다.
- 최소 하나의 피연산자는 클래스 인스턴스여야한다. 클래스의 멤버함수를 오버로딩하는 것은 자기 자신을 넘긴 것이다.
- 연산자 우선순위, 연산자 기호, 피연산자 수는 변경 불가능하다.
cf) 배열 포인터: 배열을 가리킬 수 있는 포인터 // 포인터 배열: 포인터 변수를 가진 배열
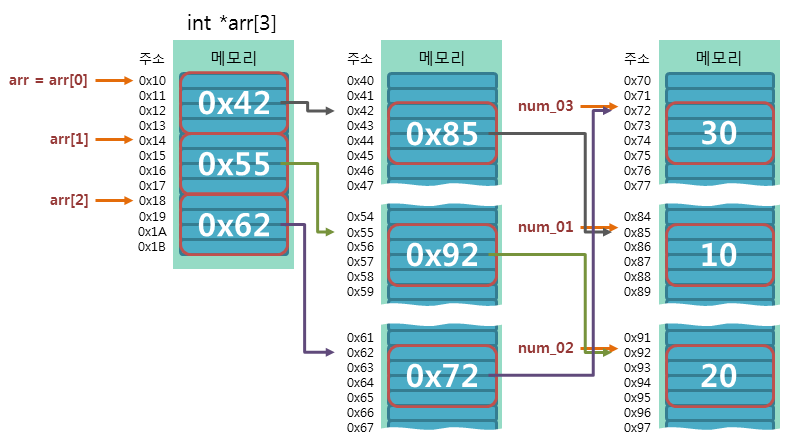
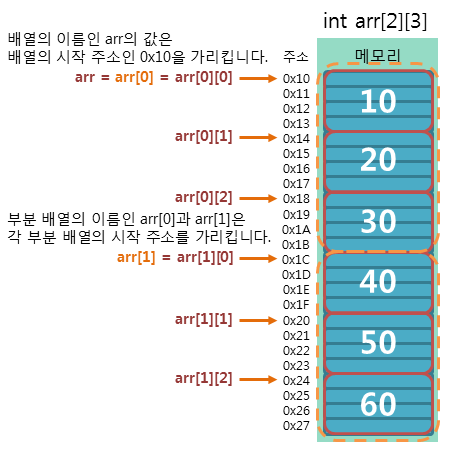
(2) 멤버함수를 클래스 내부에 적는 경우 vs 멤버함수를 클래스 외부에 적는 경우
- 클래스 내부에 적을 때는 멤버 함수를 적는다면 static 시간에 결정이 되어야한다. 따라서 멤버 함수에서 사용하는 멤버 함수나 멤버 변수는 먼저 적어줘야한다.
- inline을 사용하면 함수를 호출하는 것이 아닌 전처리기와 비슷하게 함수를 붙여주는 역할을 하기에 static 타임(런타임이 아닌)에 진행되어야한다. 클래스 내부에 멤버함수를 적을 때에는 멤버 데이터가 있는지 확인이 필요하기에 멤버 데이터의 선언이 없다면 에러가 발생할 수 있다.
- inline을 사용할 경우에는 함수 호출을 할 때의 오버헤드를 줄여줄 수 있다. 하지만 재귀함수를 사용하는 경우나 코드가 길어지는 경우에는 코드가 중복적으로 사용될 수 있고, 파일의 크기가 커질 수 있다.
- 템플릿은 컴파일 타임에 cpp에서 구성이 되어야한다.
- 생성자와 소멸자는 명시적으로 호출하지 않기에 inline과는 무관하다.
(3) 대입 연산자의 오버로딩
- 파라미터는 const를 작성해 데이터가 수정되는 것을 막아야한다.
- min은 오퍼레이터 오버로딩과 멤버 함수를 재정의할 필요가 있다.
(4) 멤버 함수로 연산자 오버로딩을 하는 경우와 전역 함수로 연산자 오버로딩을 하는 경우의 인자가 다르다.
- 멤버 함수는 자기 자신(객체)가 자동으로 포함되기에 좌측에 들어가는 항이 자기 자신이 된다. 우측에 들어가는 항은 인자로 받아온다. 그러나 Friend로 받아온 전역함수는 자기자신이 없기에 두 개의 항으로 입력을 받는다.
ex) myStack + yourStack -> myStack.operator+(yourStack) // operator+(myStack, yourStack)
- 전처리와 후처리(++) 연산자 오버로딩은 인자에 적어주느냐, 적어주지 않느냐로 할 수 있다.
T& operator++(T& lhs) # 전처리
T operator++(T& lhs, int) # 후처리
(5) Container
- 컨테이너(컴포지션)는 한 클래스의 내부 데이터 멤버가 다른 클래스 유형의 객체로 정의됨을 의미한다. 즉, 포함관계를 의미한다. STL(standard template library)이 이에 해당한다. 이를테면 벡터 또한 이에 해당한다. 본인이 오버된다면 크기를 두배로 늘려서 사용한다. like string.
(6) CountedQue
- 큐를 상속받아 CountedQue를 작성할 수 있다.
- 템플릿이 적용된 클래스를 상속받으면 자식도 템플릿이 적용된다.
- queue를 상속받아서 데이터의 개수를 반환하는 함수를 추가해서 만든다. get함수는 const를 달아주는 것이 좋다.
- 삽입 삭제를 많이 하는 경우에는 굳이 필요없을수도 있다.
4. Iterator Class
1) Iterator Class란?
컨테이너의 요소를 차례대로 검색할 때 사용하는 클래스
(1) Iterator Class
- 컨테이너를 차례로 검색할 때 사용하는 클래스로 대표적으로 리스트에서 많이 사용한다.
- 리스트클래스와 iteration을 분리해 하나의 리스트를 여러 군데서 동시에 사용할 수 있게한다.
(2) Why Iterator Class?
- 리스트에서 어떤 범위에 대해 값을 여러번 호출하게되면 GetNextItem을 여러번 호출하기에 특정 아이템을 얻어오거나 여러 군데서 동시에 리스트에 접근하는 것이 어렵다. 반면 Iterator class는 데이터는 하나만 두고 거기에 대해 접근할 수 있도록 도와준다.
- 내부를 비울 때 empty나 clear를 사용한다.
2) How to Implement Iterator Class
(1) Iterator Class 설계
- Iterator는 List와 ListNode에서 friend로 선언되어야지 내부 데이터에 접근할 수 있다. 한 쪽에서만 friend를 선언했기에 List나 ListNode는 Iterator를 참조할 수 없다.
- ListIterator의 객체는 이와 관련된 List 객체의 포인터 변수 list를 가지며 스캔할 리스트를 가리키도록 초기화된다. 또한 ListNode<Type>* 타입의 private 데이터 멤버 current를 포함하고 항상 리스트의 한 노드를 가리키게 한다.
- List class 내의 CurPos 변수와 resetList(), GetNextItem()과 같은 함수를 분리하여 사용한다.
cf) reset vs empty(clear)
- reset는 초기화하여 처음 상태로 돌리는 역할을 할 때 사용한다.
- empty와 clear는 비슷한 표현으로 내부를 삭제할 때 사용한다.
(2) Iterator Class 구현
const List<Type> &list
- 참조 변수는 선언과 대입 연산자를 통해 초기화에 쓰일 수 있지만 클래스의 멤버 변수인 경우에는 내부에 생성자를 호출하는 식으로 한다면 참조변수를 사용할 수 있다.
- 리스트의 내부를 복사하면 원본 데이터에서 수정 시 반영도 안될 뿐더러 메모리 측면에서 비효율적이기에 참조변수를 사용해서 값을 받는다. 참조변수는 선언만해서는 의미가 없기에 대부분의 경우에 참조변수를 선언하고 대입하여 초기화까지 진행한다. 하지만 클래스의 멤버변수는 초기화 리스트에 내부 생성자를 호출하는 경우로 사용할 수 있다. 이때 iterator에서 데이터를 수정하지 않기 위해 const로 받는다. 포인터를 사용하는 경우도 존재한다.
- ListNode<Type> *current에 대해 current에서 ++연산자를 사용하는 경우에는 연산자 오버로딩을 해야지 사용할 수 있다.
- null은 내부적으로 0으로 저장한다.
- shortcut에 의해 current && current -> next의 순서를 지켜주는 것이 중요하다. 만약 이 순서를 바꾼다면 에러가 발생한다. NotNull을 검사한 뒤 NextNotNull을 사용한다면 current를 굳이 사용할 필요는 없지만 로버스트한 프로그램을 만들기 위해서 위와 같이 구현한다.
(3) Why Class?
- 이터레이터를 함수로 작성하는 경우 이터레이터가 여러 탐색을 동시에 가능하게끔 하는 동작을 구현할 수 없다. 따라서 이를 클래스로 만들어 객체에따라 책갈피의 역할을 할 수 있도록 구현하는 것이 중요하다.
- 이터레이터는 자료구조와 함께 있어야하기에 선언과 동시에 초기화되어있어야한다.
- 문제가 발생하면 F5를 눌러 콜스택을 부를 수 있다.
(4) 이터레이터를 생성할 때의 주의 사항
- 순회할 자료구조에 대해 선언과 동시에 초기화해야한다.
cf) C++에서 ''와 ""
'': 문자이기에 메모리에 저장될 때 1바이트 단위로 저장한다.
"": C스타일의 문자열이기에 하나의 값을 저장하더라도 \0이 생략되어있어 2바이트로 공간이 잡힌다.
'강의 내용 정리 > 자료구조' 카테고리의 다른 글
| 자료구조 (7), 재귀호출 (0) | 2022.06.19 |
|---|---|
| 자료구조 구현 (1), Unsorted list (0) | 2022.05.11 |
| 자료구조 (5), Stack and Queue (0) | 2022.04.19 |
| 자료구조 (4) ADTs Unsorted List and Sorted List (0) | 2022.03.17 |
| 자료구조 (3) 데이터 디자인과 구현 (0) | 2022.03.17 |