2022. 6. 13. 02:41ㆍ강의 내용 정리/컴퓨터구조
Multithreading
1. Multithreading Basic

- thread: state한 명령어 스트림. state은 레지스터나 메모리에 있다. 쉽게 생각해서 프로그램으로 볼 수 있다.
- 쓰레드 컨텍스트는 레지스터에 있는 state를 의미한다.
- 그동안은 하나의 쓰레드에서의 동작 처리 방식을 배웠다.
- 매우 많은 쓰레드가 처리해서 시스템 성능을 올릴 수 있다.
- 동일한 프로그램 내에서도 여러 쓰레드가 있기도 하다.
- 포탈 사이트에 접속하면 사용자가 접속할 때마다 쓰레드를 배정해준다. 로컬 컴퓨터에서는 각각의 프로그램으로 이해하면 쉽다.
- 프로세서는 쓰레드의 컨텍스트를 명령어를 통해 업데이트해준다.
- 레지스터의 개수가 제한되어있기에 쓰레드의 컨텍스트를 업데이트하고 내리고 하는 것을 반복한다.
Hardware Multithreading
- 하나의 프로세서에서 여러개의 쓰레드 컨텍스트를 받고 처리하는 것을 의미한다.
- 멀티스레딩을 하면서 레이턴시가 발생했을 때 스톨을 하는게 아니라 다른 쓰레드의 일을 함으로서 프로세서를 더 효율적을 처리할 수 있다. 유틸라이제이션 향상!
- 하나의 프로세서가 롱 레이턴시 오퍼레이션을 가지면 프로세서는 다른 쓰레드의 오퍼레이션을 실행한다. 이를 통해 레이턴시를 해결한다.
- 쓰레드에서 병렬처리를 해서 시스템 퍼포먼스가 올라간다. 컨텍스트 스위치의 패널티도 줄일 수 있다.
Benefit
- 모두 하고있고, 얼마나 잘하는지가 중요한 문제이다.
- stall을 하는 대신 다른 쓰레드를 사용한다. latency를 줄이고, 하드웨어 유틸라이제이션을 늘리고, 레지스터 파일을 늘리기에 컨텍스트 스위치 패널티를 줄인다.
Cost
- 다만 Hardware cost가 더 많이 든다. 멀티쓰레딩을 하더라도 싱글 쓰레드 퍼포먼스는 줄어들 수 있다. -> 스위칭, contention resource sharing문제 때문이다.
2. Types of Multithreading
- Fine-grained MT: 매 사이클마다 쓰레드를 바꾼다.
- Coarse-grained MT: 이벤트가 발생했을 때 쓰레드를 바꾼다. ex) cache에 찾는 데이터가 없는 경우(cache miss) 메모리로 간다. 이를 기다리지 않고, 쓰레드를 바꾼다.
- Simultaneout MT: 한 사이클에서 여러개의 쓰레드가 동시에 들어와서 처리한다.
1) Fine-grained MT
- 매 사이클마다 다른 쓰레드로 스위치한다. 이 때문에 굳이 이벤트가 발생하는 것을 찾을 필요가 없기에 복잡한 하드웨어의 구현은 필요 없다.
- 하나의 쓰레드를 처리하는 속도는 더 오래 걸릴수도 있다. 하지만 시스템 전체 속도는 올라갈수도 있다.
- Fine-grained MT를 하는 쓰레드의 개수만큼 레지스터 파일이 더 필요하다. 즉, 이를 위한 하드웨어가 더 필요하긴하다.
- 매 사이클마다 스톨이 발생할 수 있는데, 파이프라인을 하면서 발생하는 디팬던시 이슈를 줄일 수 있다. 브랜치가 있더라도 이미 이를 계산할 수 있다. 파이프 스테이지 간 컨트롤 해저드나 데이터 해저드를 줄일 수 있다.
- 네 개의 쓰레드를 올려놓고 사용하는 예시로 PC와 Register는 4개씩이다. 매 사이클마다 PC1 -> PC2 -> PC3 -> PC4 등으로 넘어간다. 만약 싱글 쓰레드를 사용한다면 1/4정도 수준으로 성능이 낮아진다.
- 왼쪽 아래처럼 쓰레드를 셀렉트하는 것도 있어야한다.
장점
- 디펜던시 체킹이 없다. 매 사이클마다 다른 쓰레드의 명령어를 가져오기에 하나의 쓰레드를 처리할때보다는 디펜던시를 줄일 수 있다.
- 파이프 스테이지가 충분하다면 브랜치 예측 로직이나 스톨을 없애거나 줄인다.
- 시스템 성능을 늘릴 수 있다.
단점
- 추가적인 하드웨어 복잡도가 필요로 한다. (PC와 register가 추가로 필요하다.)
- 싱글 쓰레드 성능이 낮아진다.
- 다른 쓰레드 간에도 충돌이 발생할 수 있다. 이럴 때는 디팬던시 체킹이 필요하다.
- superscalar 구조면 한 사이클 내에서 여러 명령어 간의 디팬던시 체킹이나 브랜치 예측이 필요하다. 하지만 줄어들기는 하다.
2) Coarse-grained MT

- cache misses, Floating-point operations, Accessing slow I/O devices와 같은 이벤트가 발생하면 쓰레드를 바꾼다.

- 파인 그레인드의 구현이 조금 더 쉽다. 또한 스위치할 때 패널티가 없고, 만약 파이프라인을 날릴 때는 1/N만큼 날릴 수 있기에 강인하다.
- 다만 파인 그레인드의 경우에는 싱글 스레드 환경에서는 최대 1/n만큼 성능이 떨어질 수 있다. 이 때문에 사용자 입장에서는 더 느리게 느낄 때도 있다. 예를 들어 파일을 열 때도 메일을 정리하는 등의 작업을 하기에 단순한 것도 더 느리게 되고, 사용자의 만족도는 낮아질 수 있다.
3) Simultaneout MT

- 우리가 실행할 수 있는 명령어는 다 채워넣는다.
- 복잡한 하드웨어가 필요하지만 성능은 좋아진다.
- superscalar 구조에서 한 사이클에서 네 개씩 명령어를 채울 수 있다하더라도 이를 다 사용하지 못하는 경우가 있는데 다른 쓰레드에서 할 수 있는게 있다면 끌고올 수 있다.
- 과거 멀티쓰레딩 지원이 안되던 때는 익스플로러를 켜고 다른 것을 켜면 버벅이게 된다. 지금은 여러 개를 열어도 속도가 많이 떨어지지 않는다.
예시)
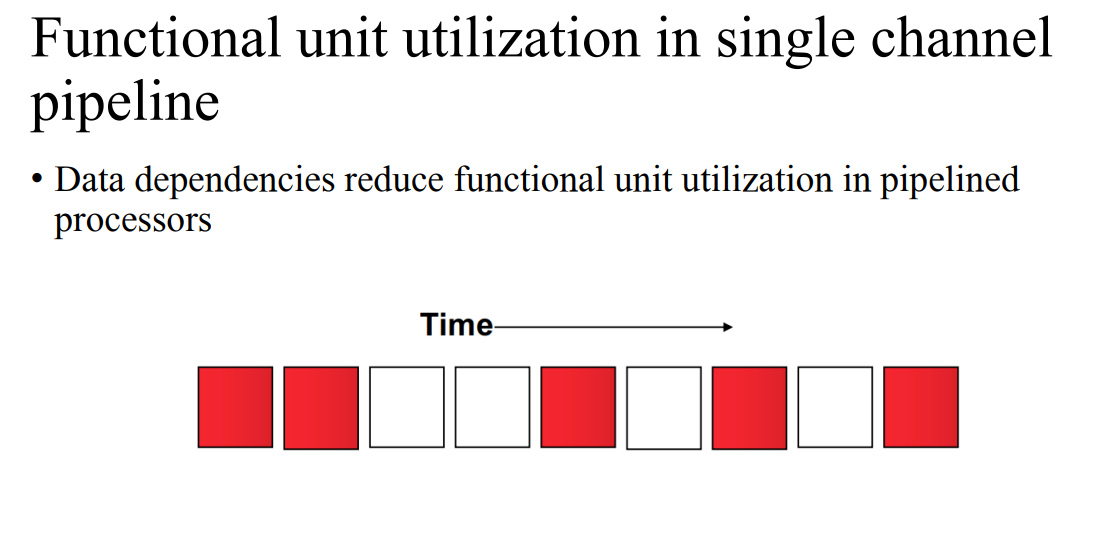
- 빨간색은 사용하고 있기에 명령어가 있고, 하얀색은 스톨이다. 데이터 디팬던시가 있으면 스톨이 발생한다.
- 싱글 채널은 하나의 명령어를 한 사이클에서 사용하기에 super scalar는 아니다.
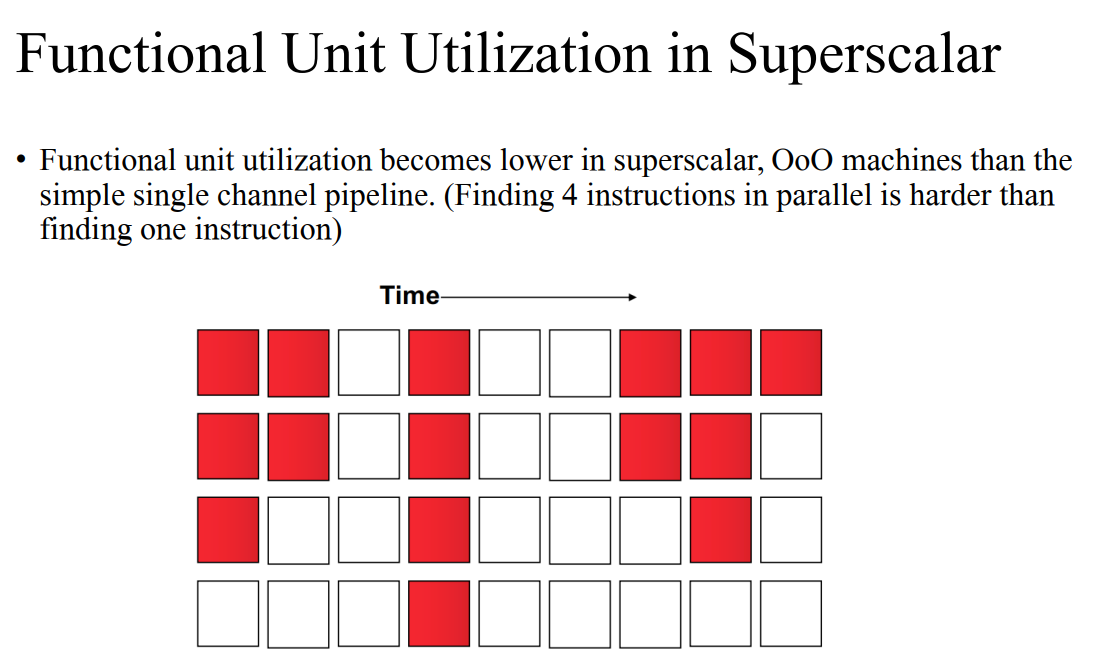
- 디팬던시 이슈가 있으면 스톨이 존재한다.
- 슈퍼스칼라 구조로 가면 펑셔널 유닛 유틸라이제이션이 줄어든다. 이를 효율적으로 하기위해 OoO가 있긴하지만 스톨은 발생한다. 이를 줄이기 위해 predicated Execution을 했다.

- 하지만 FU utilization이 많이 줄어들지는 않는다.
Chip Multiprocessor
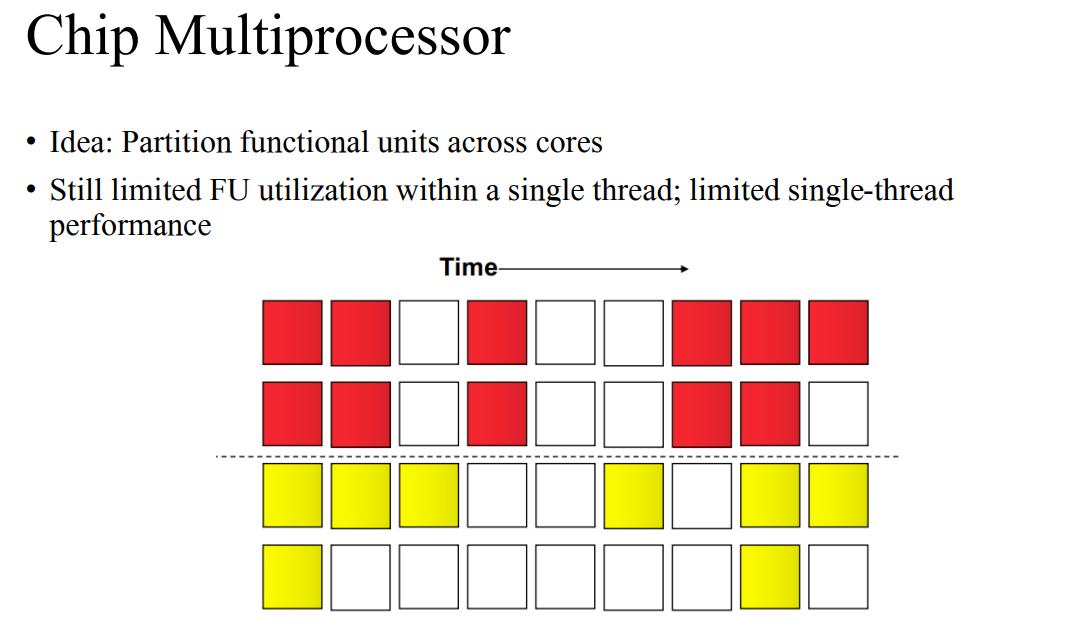
- 코어마다 다른 쓰레드를 처리한다. 코어별로 구분을 지으면 디팬던시를 조금 더 줄일 수 있다.
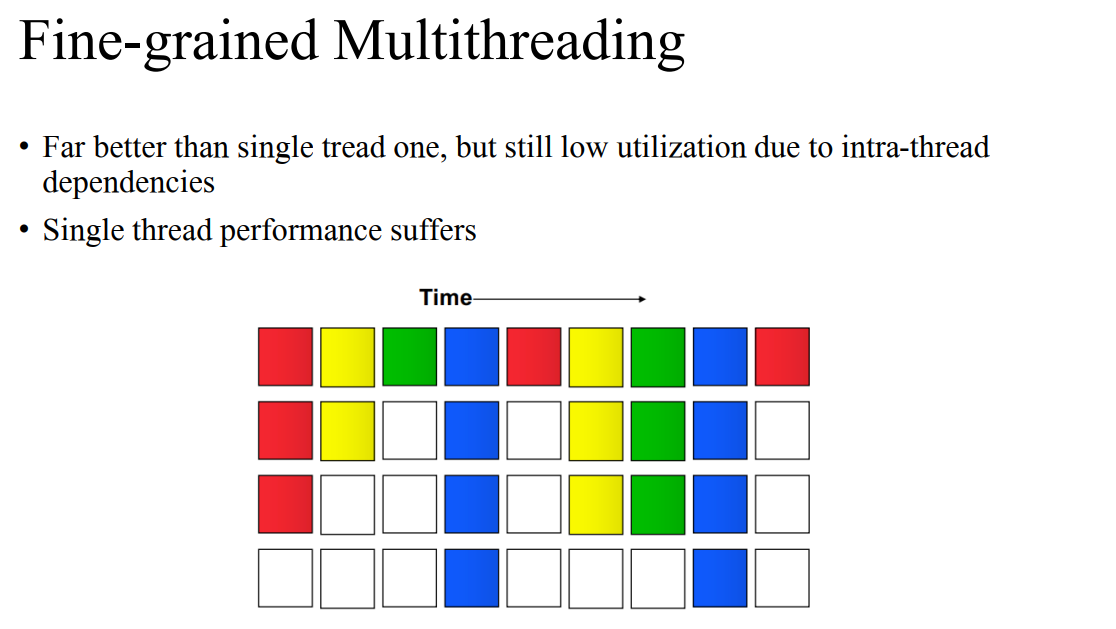
- 색깔마다 따른 쓰레드이다.
- 매 사이클마다 달라진다. 이는 superscalar보다 더 효율적인것을 볼 수는 있다.
- 빨간색 쓰레드는 성능이 더 줄어든다.
- 쓰레드 간에는 디팬던시가 없다.
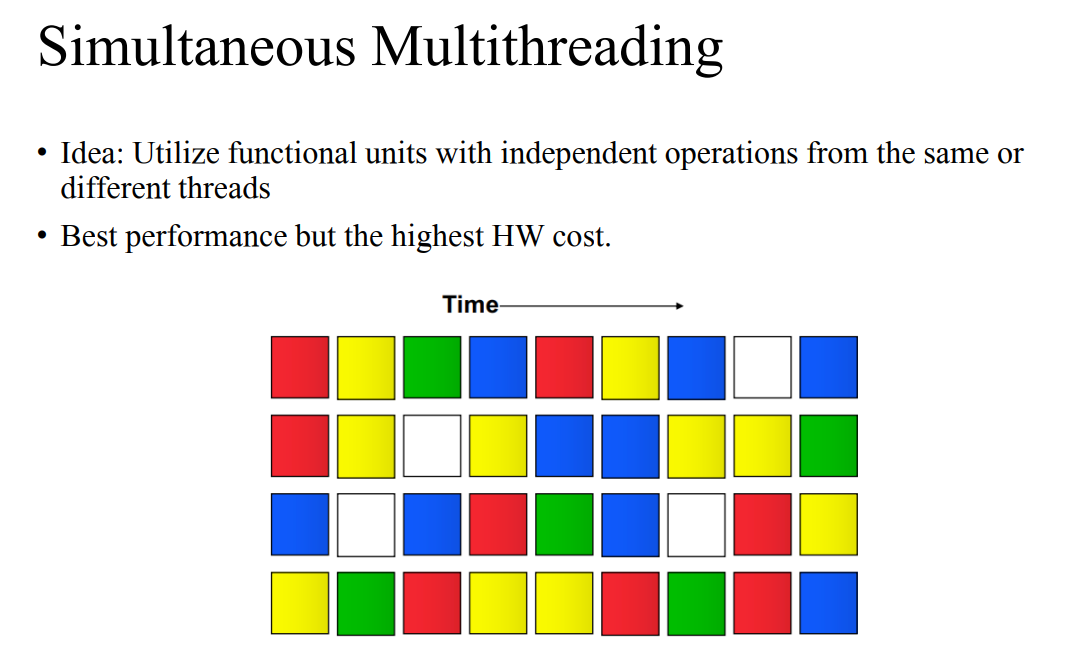
- 한 사이클 내에서도 여러 개를 채워서 사용한다.
- 이를 잘할 수 있도록 만들면 퍼포먼스는 늘리지만 하드웨어가 매우 복잡해질 수 있다.
- 멀티쓰레딩을 얼마나 잘하는지가 매우 큰 이슈다.
- 쓰레드 우선순위가 있다면 그거부터 할 수 있기에 싱글 쓰레드에서도 크게 손해를 보지 않고 사용 가능하다.
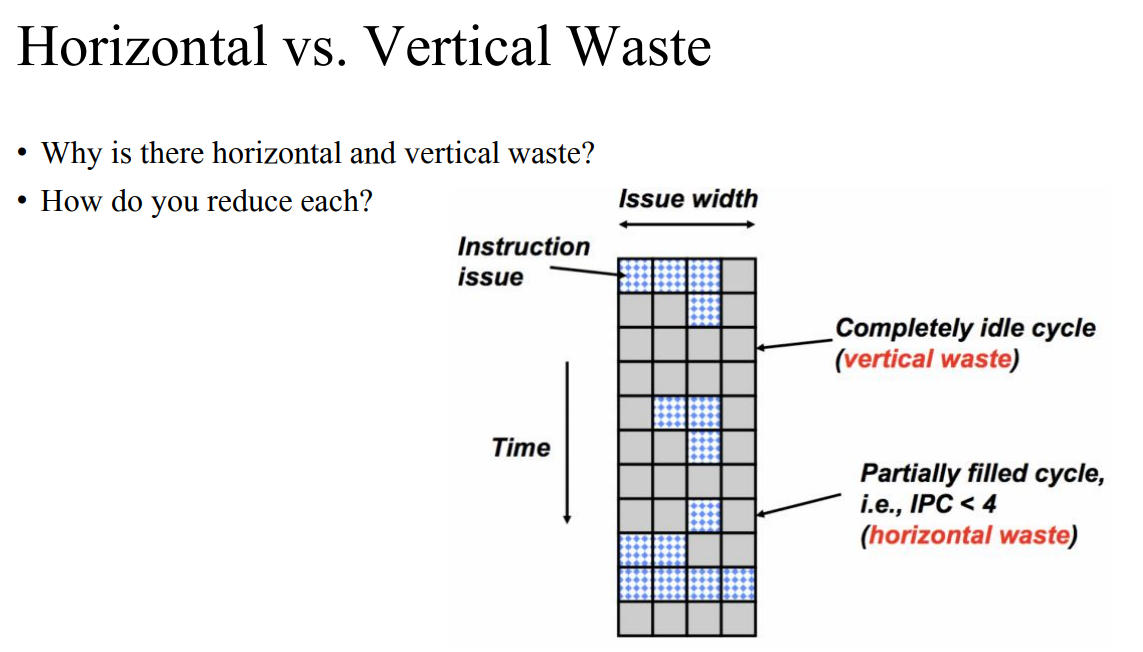
- 위의 그림을 90도 돌린 것이다.
- 파란색은 instruction issue된 것이다. 이때 어느 한 타임에 대해 스톨을 한다면 vertical waste라고 한다. 만약 MIPS가 4개인데 이를 다 못채우면 horizontal waste라고 한다.

- SM은 horizontal, vertical issue를 모두 줄인다.
- 하드웨어가 매우 중요해진다. 명령어를 여러개 불러와서 동시에 처리할 수 있어야한다. 결국 하드웨어 비용이 높아진다.
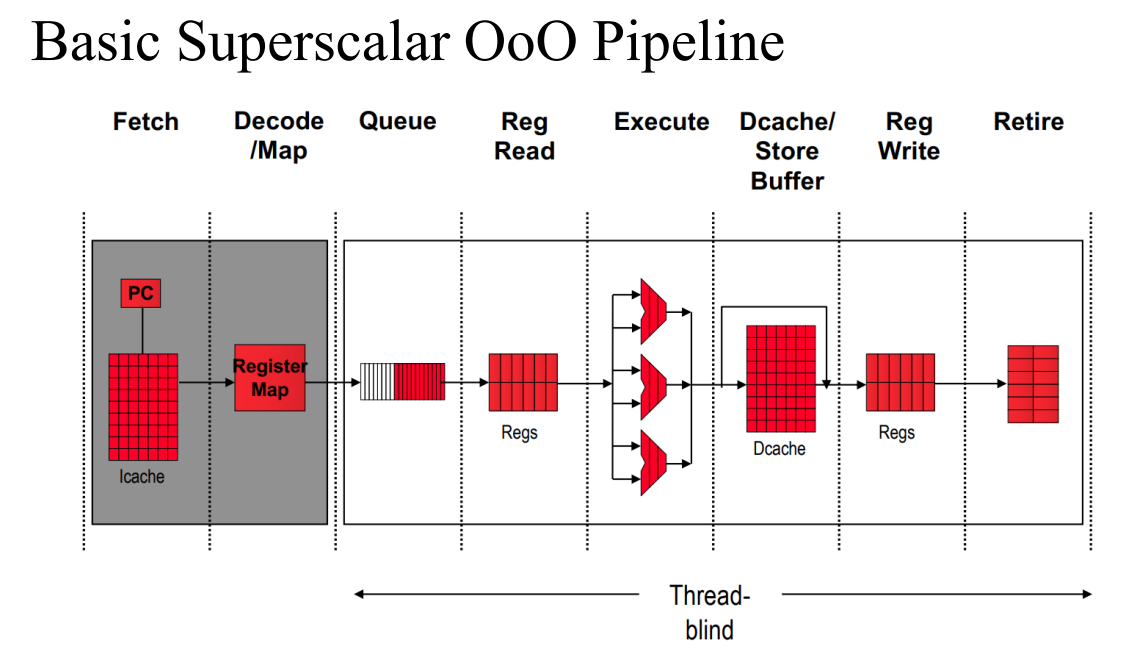
- 하드웨어가 어떻게 달라져야하는가
- 파이프 스테이지가 더 많아졌다. 현재는 6개이다.
- 인스트럭션 캐쉬에서 PC에 해당하는 것을 가져오고, RM을 통해 디코드하여 매핑한다. 이를 큐에 쌓고, Reg Read한 뒤, 실행하고, Dcache(메모리)에 저장한다. 이후 Reg Write한다.
- Register Map은 구형의 컴퓨터에서 컴파일한 프로그램이 신형에서 사용할 때 미스매치될 수 있기에 이를 연결해준다.
- Loop unrolling(브랜치 예측을 줄이는 방법)은 컴파일 단계에서 하면 프로그램 크기가 커지기에 이를 하드웨어에서 하기에 Queue에서 진행한다.
- Retire는 out-of-order 방식으로 할 때 문제가 발생할 수 있기에 이를 체크하여 풀어주는 단계이다. 혹은 이름을 붙여주는 방식 등을 사용할 때 이를 다 사용하고 풀어준다.
- 복잡한 구조로 바뀐다.
SMT
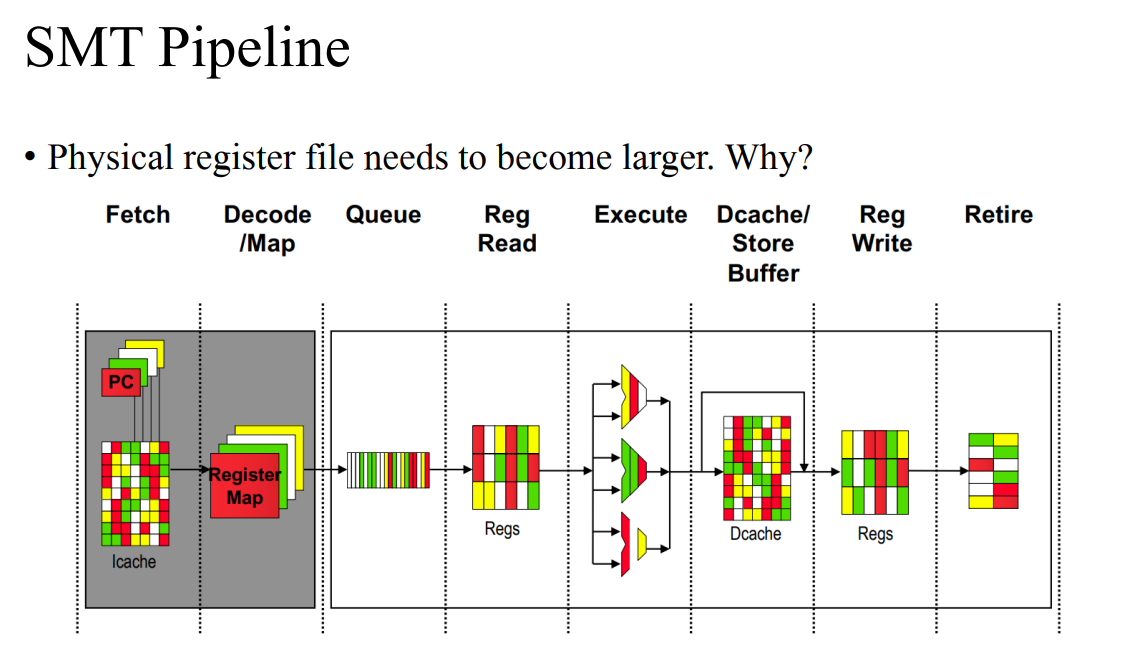
- 큐에서 디펜던시를 체크해서 order를 변경해준다.
- 다른 색깔이 사용된다. 레지스터 파일도 제한이 있었는데 멀티 쓰레딩에서는 레지스터 파일이 커져야한다.

- SMT를 할 수 있는 파이프라인 구조에서는 다음과 같은 것을 바꿔야한다.
- 디자인하는 것에 따라 PC, Register map, return address stack, global history register(브랜치 예측에서 사용) 등과 같은 리소스를 바꿔야한다.
- 하지만 Register file은 사이즈를 키워서 공유할 수 있다. 혹은 레지스터 파일을 쓰는 크기에 따라 다르게 할당한 다음에 쉐어할 수 있다. First and second level caches, instruction queue, Translation lookaside buffer, Branch predictor도 공유할 수 있다.
- 파란색은 공유할수도 있고 다시 사용할수도 있다.

- PC가 여러개여야하고, 매 사이클마다 어떤 쓰레드의 명령어를 가져올 것인지 가져오는 매커니즘이 필요하다.
- 각각 쓰레드에 대한 리턴 스택도 각각 들고 있어야한다.
- 쓰레드마다 명령어 retirement나 큐 플러쉬 등이 필요하다.
- 브렌치 예측을 위한 쓰레드 ID가 필요하다.
- 레지스터 파일은 더 크게 사용해서 데이터 디팬던시 이슈를 해결해야한다.
- 레지스터 사이즈는 영향을 준다.

- SMT에서 고려해야하는 부분
- 한 사이클에서 최대로 실행할 수 있는 쓰레드의 개수를 얼마나 할 것인지에 따라 IPC가 얼마나 증가하는지 확인한다.
- SMT를 하면 퍼포먼스가 증가하지만 어느 정도까지는 사용가능한 쓰레드의 개수를 늘림으로서 IPC가 증가한다. 쓰레드의 개수를 늘릴 수록, 비용이나 복잡도가 늘어난다. 결국 얼마나 쓰레드의 개수를 사용할지는 이 모든 것을 고려해 디자인해야한다.

- 어떤 쓰레드로부터 명령어를 패치하고 우선순위를 줄 것인지를 정하는 것은 중요하다.
- 공유하는 자원에 대한 규칙을 정하는 것도 중요하다. 어떤 쓰레드가 계속 패치가 못되는 것을 방지할지, fairness/Quality of Source 제공, throughput 최대화, 리소스를 파티션할지, 공유할지 등을 정해야한다.
- 성능은 어떻게 잴 수 있을지 정해야한다. PoS가 있다면 빨리 처리해야하는 쓰레드가 있는 경우 어떤 것을 기준으로 성능을 체크할지 정해야한다.
- 어떻게 쓰레드를 선택할지 정해야한다.

- Round-robin: 가지고 있는 쓰레드를 하나씩 패치한다. 간단하지만 퍼포먼스가 좋은지는 의문이다.
- Static한 방법은 간단하지만 퍼포먼스가 좋지 않을 수 있다.
- Dynamic은 복잡하지만 퍼포먼스 관점에서 더 좋다.
- minimal in-flight branch: 브랜치가 적은 쓰레드에 선호를 줘서 해당 쓰레드에서 먼저 가져온다.
- outstanding misses: 캐시 미스가 많으면 오래걸리기에 이게 없는 것을 위주로 우선순위를 준다.
- in-flight instructions: 명령어가 적은 쓰레드에 우선순위를 준다.
- higher real time requirements: 실시간이 필요한 것에 대해 우선순위를 준다.

- Round robin: 다른 쓰레드에서 각 사이클마다 번갈아가면서 골고루 패치하는 방법이다.
- 구현은 간단한데 퍼포먼스가 좋지는 않다.
- 느린 쓰레드 있다면 파이프라인을 독점할수도 있다.
- 우선순위를 고려하거나 오래 걸리면 다른 쓰레드를 먼저 채우는게 더 좋다. 하지만 이러한 부분을 반영하지 못하기에 손해볼 수 있다.
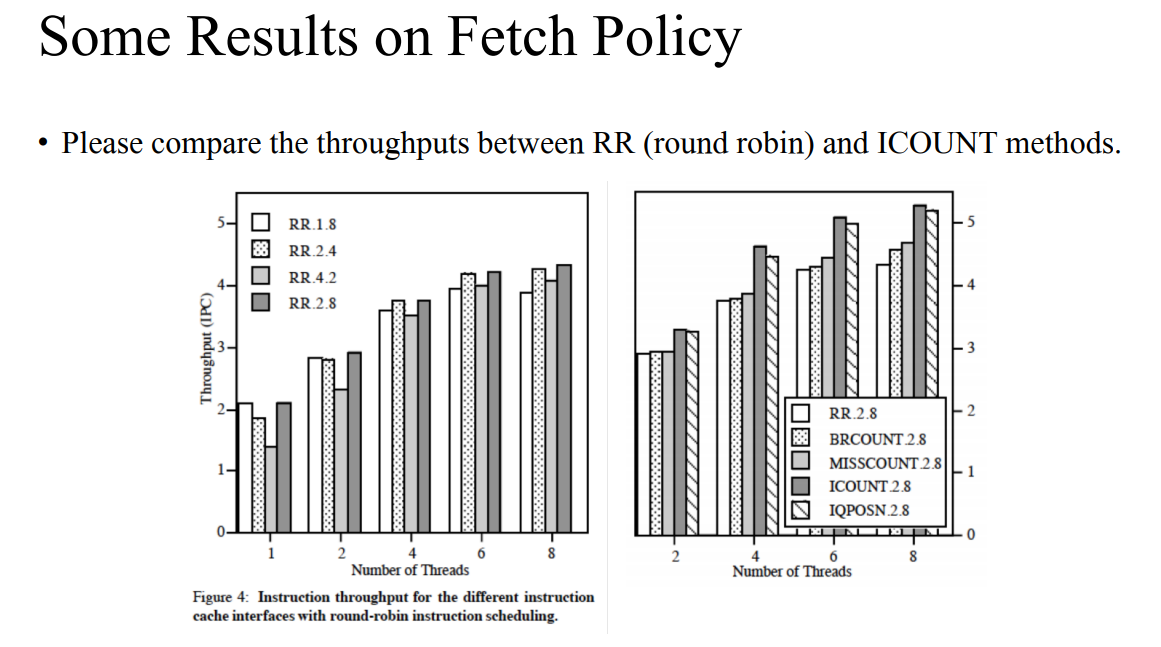
- SMT를 만들 때의 문제점을 고려하여 이에 대한 솔루션을 바탕으로 디자인을 해야한다.
- 왼쪽 그래프는 round-robin 방식이다. 오른쪽 그래프는 다양한 방법을 적용했을 때의 성능이다.
- round-robin은 네개 이상일 때는 성능이 조금 좋은 것을 확인할 수 있지만 다양한 방법들을 적용했을 때의 성능이 더 좋다. 그 예시 중 하나인 ICOUNT는 다음과 같다.
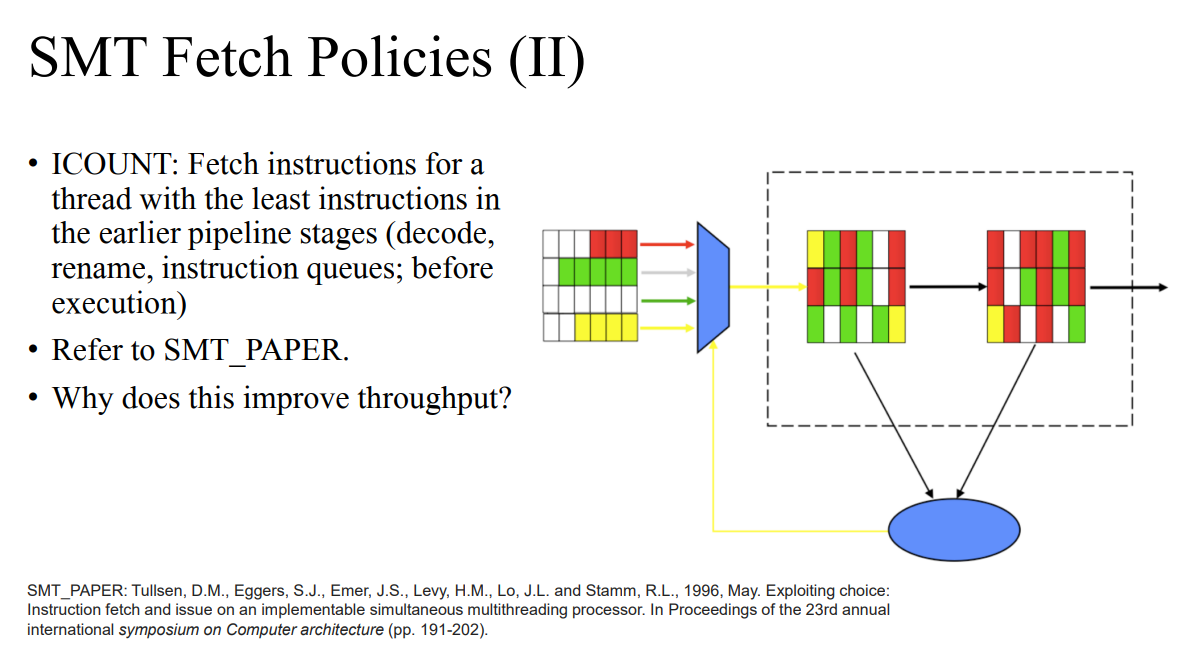
- ICOUNt: 명령어 개수가 적은 쓰레드부터 보낸다. excution unit에 가기 전에 먼저 패치한다.

- 논문 저자는 서로 다른 패치 정책을 정의했다. round-robin보다 더 좋은 성능을 가지는 것을 정의했다.
- BRCOUNT: 높은 wrong path로 갈 가능성이 낮은 것에 우선순위를 줬다. 이는 브랜치를 보고 판단하거나 브랜치가 적은 것을 기준으로 확인한다.
- MISSCOUNT: instruction Queue를 보고 캐시 미스가 적은 것들에 대해 우선순위를 준다.
- ICOUNT: Instruction Queue를 보고 명령어가 적은 쓰레드부터 우선순위를 준다. 하나의 쓰레드가 파이프라인을 독점하는 것을 막을 수 있다. 또한 IQ에서 빨리 처리되는 것을 계속 가져올 수 있다. 이에 따라 느린 것은 조금 쌓이지만 빨리 처리되는 것은 계속 가져올 수 있다. 이를 mix해서 가져올 수 있다.

- 큐를 보고 Waiting이 적게 있는 명령이 있는 쓰레드를 가져온다.
- 빠르게 처리되는 것은 더 빠르게 처리할 수 있도록 한다. 이에 따라 long latency를 막을수 있기에 성능이 늘어난다.
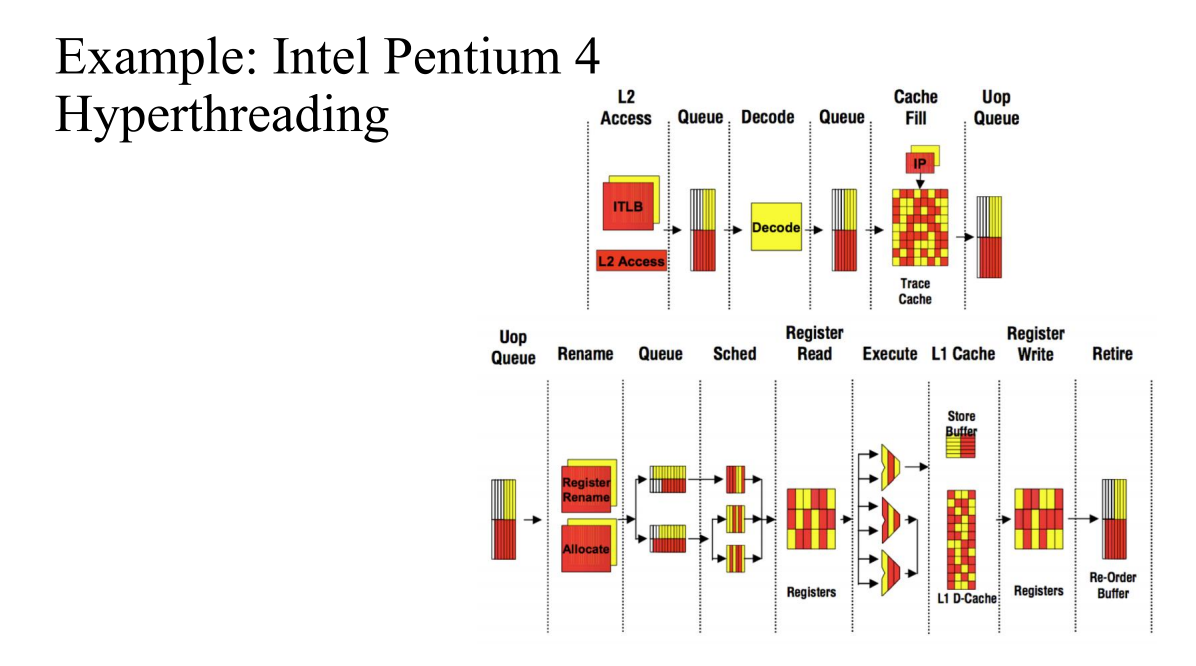
- 실제 Intel Pentinum 4로 상용 CPU이다.
- 단계가 매우 많아서 15개의 스테이지로 구분한다. 실제로는 조금 복잡하다.
- PC 순서대로 실행된 것이 아니기에 실행 순서를 추적할 수 있도록 캐시에 넣는다.
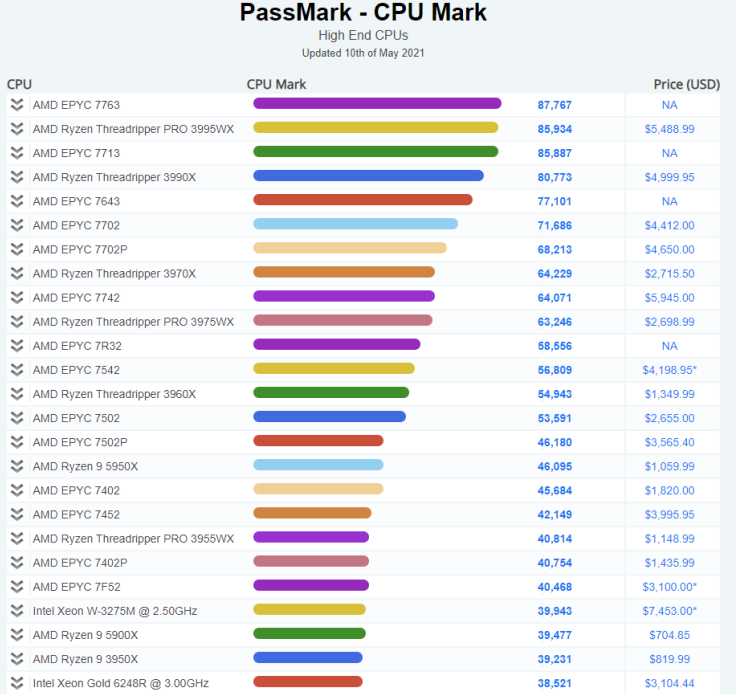
- CPU 벤치마크 웹사이트로 21년도 5월의 성능과 가격을 확인할 수 있다.
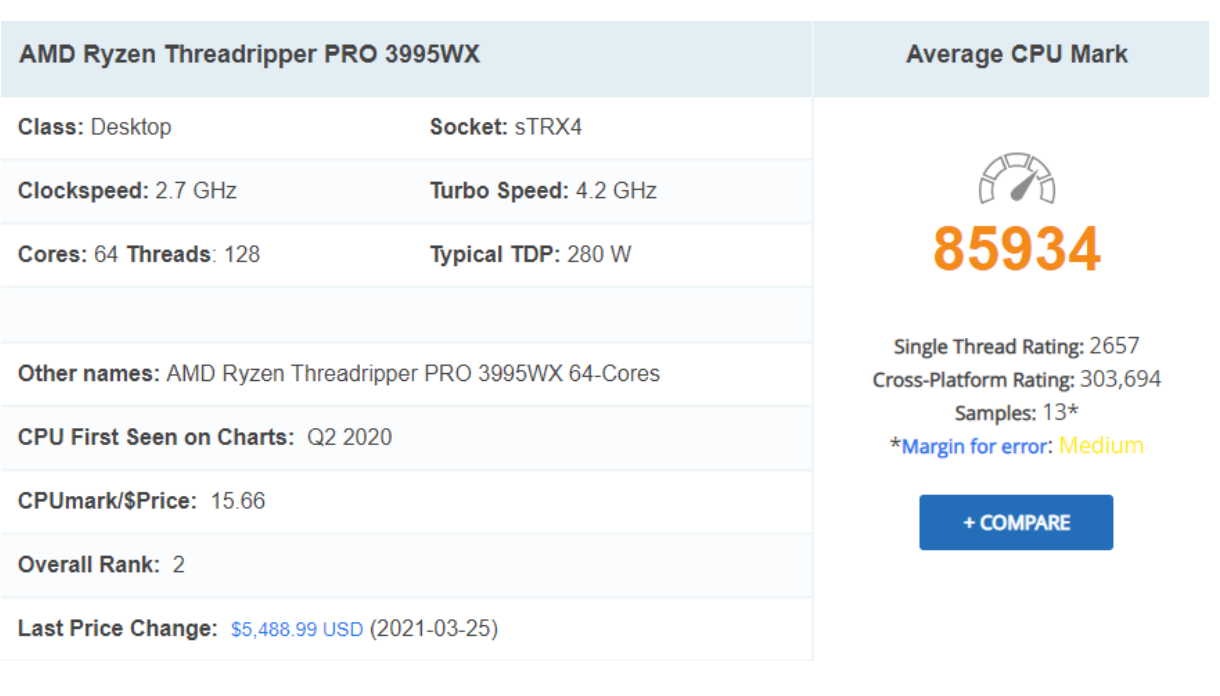
- CPU를 클릭하면 각 정보를 확인할 수 있다.
- Core 64개에 Threads 128개는 채널 2의 superscalar 구조이다.
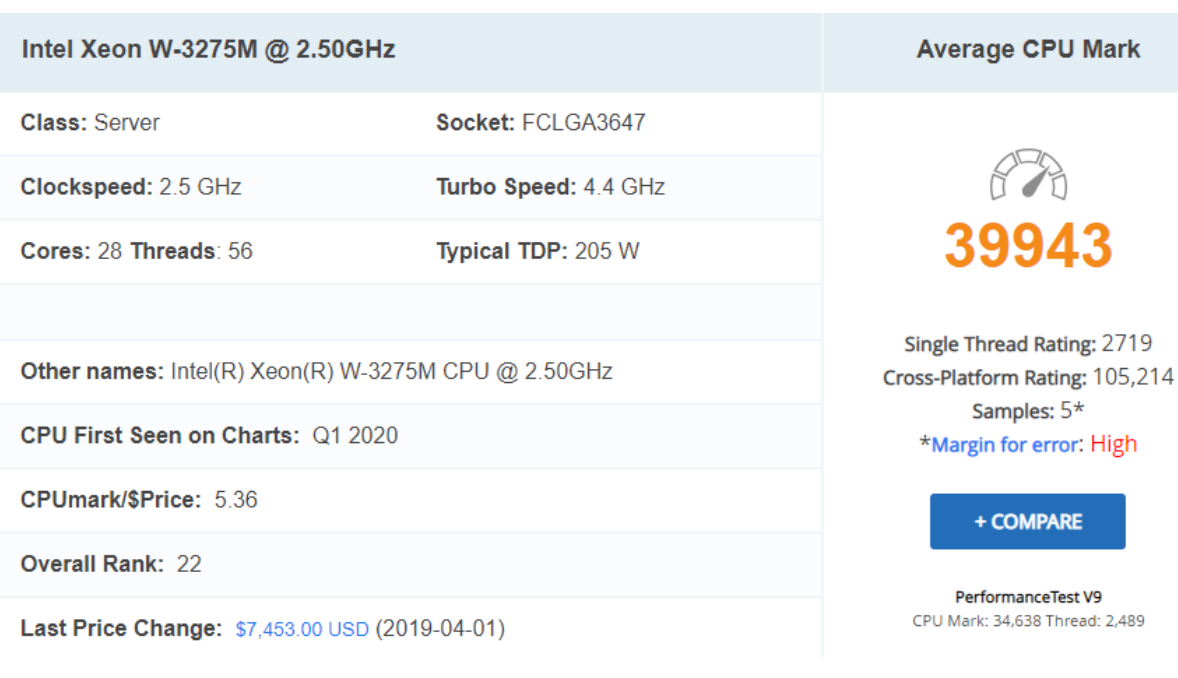
- 위와 같이 성능을 확인할 수 있다.
'강의 내용 정리 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터 구조(13), Prefetching (0) | 2022.06.15 |
|---|---|
| 컴퓨터 구조(12), Memory Hierarchy & Caches (0) | 2022.06.13 |
| 컴퓨터 구조(10), Super Scalar (0) | 2022.06.12 |
| 컴퓨터 구조(9), Control Dependence Handling: Predicated Execution and Loop Unrolling (0) | 2022.06.11 |
| 컴퓨터 구조(8), Branch Prediction (0) | 2022.06.08 |