2022. 6. 12. 04:34ㆍ강의 내용 정리/컴퓨터구조
Super Scalar
Extracting Yet More Performance

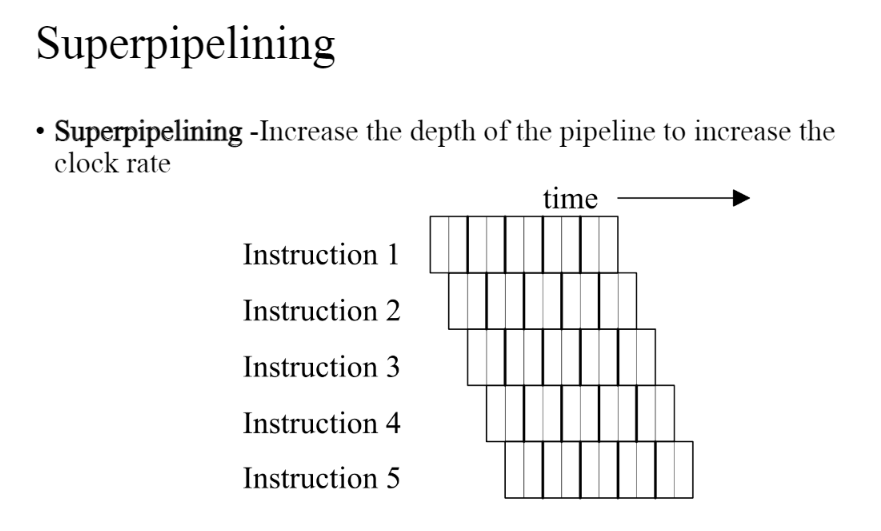
- Super Pipelining: 파이프라인에서 파이프 스테이지를 늘릴수록, 클락 레이트를 올릴수록 성능이 좋아진다. 클락 레이트는 가장 오래 걸리는 스테이지에 맞춰야한다. 가장 오래걸리는 것을 쪼개는 것이 중요하다. 이에 따라 파이프라인의 깊이를 늘리는 것이 중요하다.
- Super Scalar: 한 사이클에 하나보다 더 많은 명령어를 패치하고 실행한다. 매 파이프라인마다 하나가 아닌 여러개의 명령어가 돌아가는 구조를 의미한다.
- Super Scalar를 하면 CPI가 1보다 낮아질수도 있다.
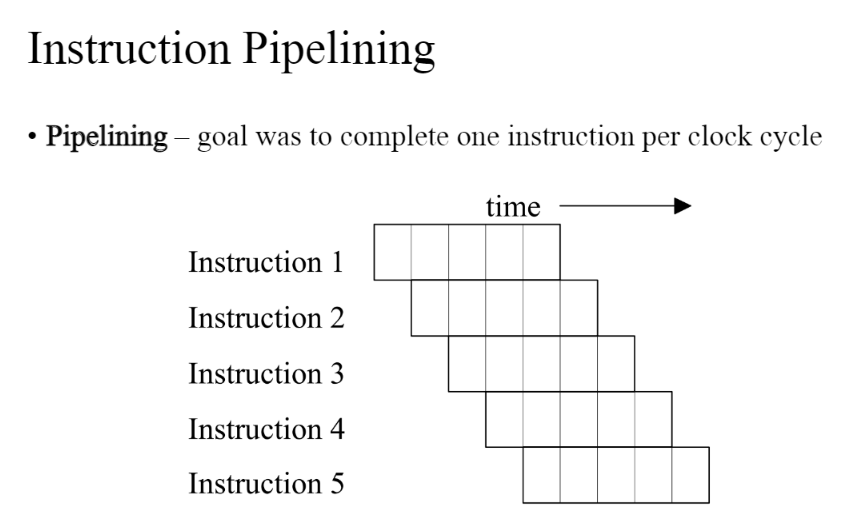
Instruction pipeline
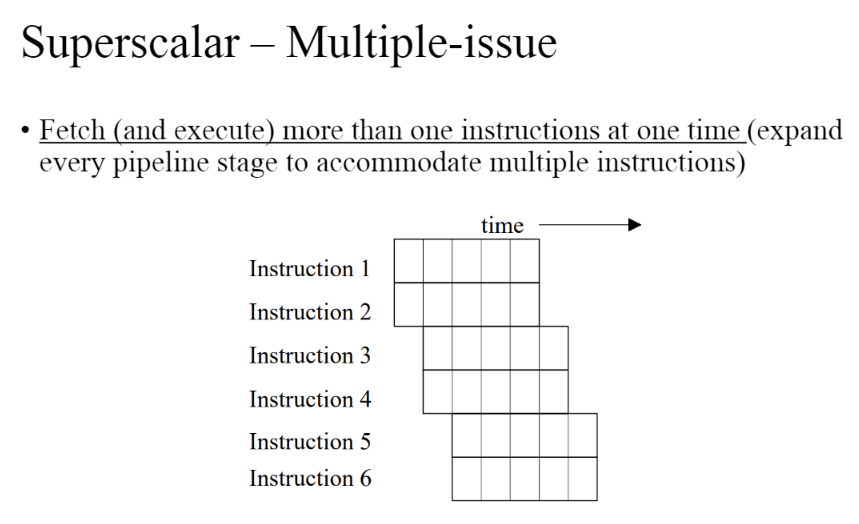
superscalar
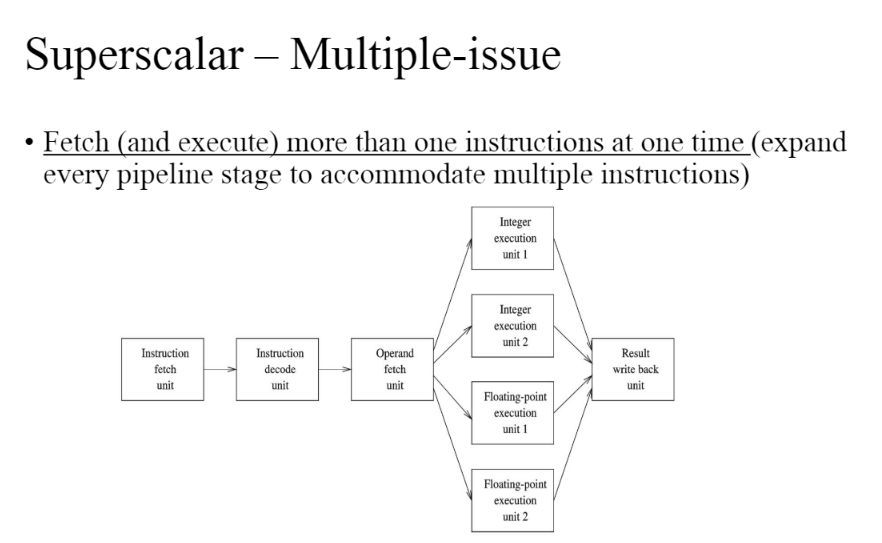
- 여러개의 명령어를 패치하는 것을 확인할 수 있다.
- 연산하는 것이 여러개 있어야할수도 있다.
Super pipelined processors

- depth를 늘리면 클럭 사이클이 짧아지고 클럭 레이트가 올라갈 수 있다. 하지만 아래와 같은 문제점이 발생한다.
- 데이터 디팬던시 해결을 위한 하드웨어가 많이 늘어나고 복잡해질 수 있다.
- 어쩔 수 없이 생기는 파이프라인 스톨도 늘어난다.
- 이론적으로 가장 오래걸리는 것을 정확하게 쪼갤수 있어도 선형적으로 좋아지지는 않는다.
Super pipelined vs superscalar

- Super pipelined가 명령어 레이턴시가 더 늘어나고, 디팬던시 이슈가 더 생긴다.
- Super scalar는 리소스 충돌이 있고, 여러개를 패치하니까 더 복잡할수도 있다. 멀티스레딩과 함께하면 효과가 더 좋아질 수 있다.
2. Multiple-Issue processor styles
1) Multiple-Issue processor styles

- VLIW: 스태틱한 방법이다.
- VLIW는 컴파일 타임에 같이 실행할 수 있는 것을 묶어서 그룹을 만들고 실행한다.
- 슈퍼 스켈라는 다이나믹하게 처리하기에 하드웨어가 런타임에 한다. 따라서 더 효율적일 수도 있다. 다만 복잡할 수도 있다. 이는 멀티스레딩과 함께한다면 더 좋은 퍼포먼스를 보인다.
2) VLIW Concept

- 컴파일러가 컴파일 과정에서 패킹하여 같이 실행할 수 있는 부분은 같이 실행한다.
- 하드웨어는 명령어 번들을 실행하기에 간단하다. 슈퍼스켈라는 다이나믹하게 해야하기에 복잡하다.
- 하드웨어는 동시에 패치되는 명령어 간의 디팬던시를 체크할 필요는 없다.
- 하지만 묶지 못하는 경우가 많다.
VLIW 컨셉
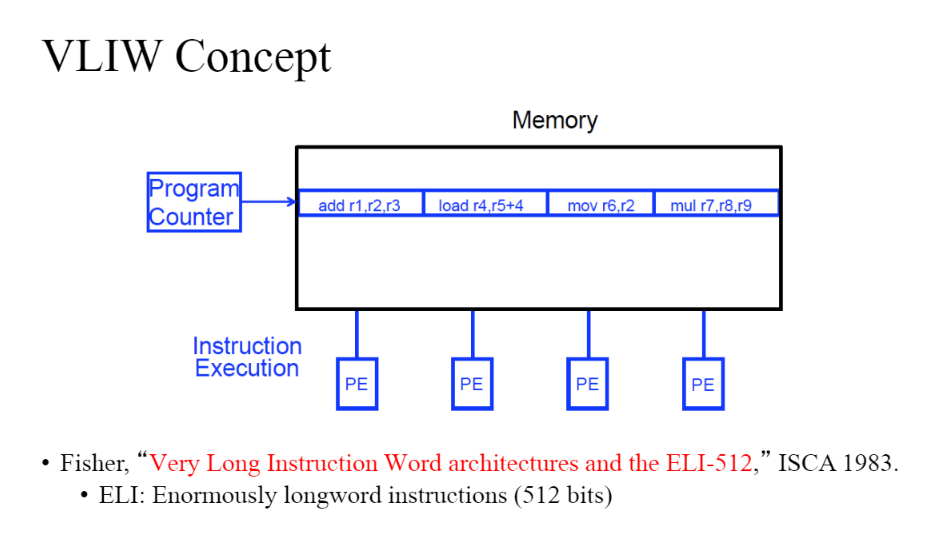

- 디팬던시가 없고, 한번에 관련 없는 명령어를 처리해줄 수 있다.
- 명렁어가 길어진다. 이는 컴파일러가 한다.
VLIW Performance Example (2-wide bundles)
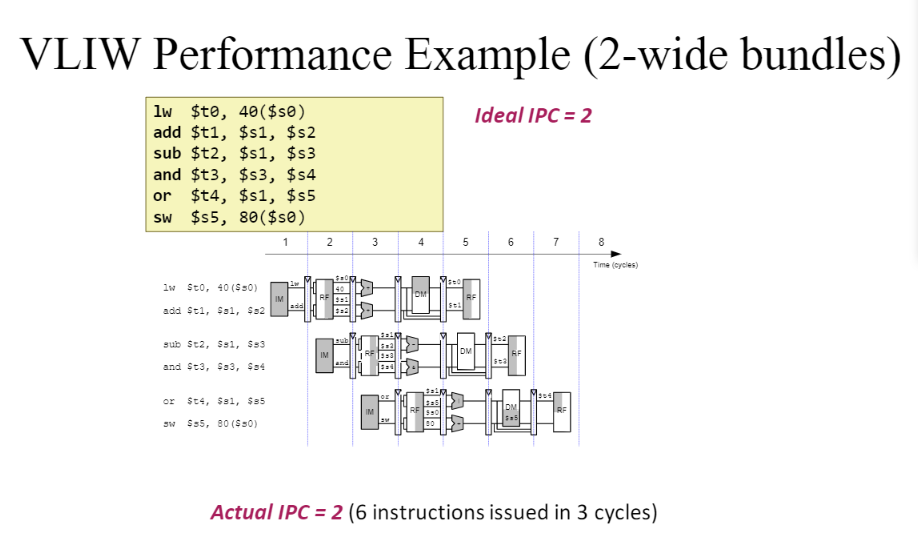
- 관련 없어보이는 것들을 묶어서 패치한다.
VLIW 장단점

- 하드웨어 관점에서는 간단하게 패치할 수 있다. 필요할 때마다 리소스만 제공하면 된다. 런타임에 하드웨어가 복잡하게 처리해야하는게 없다.명령어 alignment/distribution도 필요하지 않다.
- 하지만 컴파일러는 width가 n이면 n개의 독립된 오퍼레이션을 찾아서 컴파일해야한다. 이를 찾지못하면 꽉채워서 못할수도 있다.
- width나 환경이 달라지면 컴파일을 다시해야한다. superscalar는 동적이기에 상관없다.
VLIW Summary

- 컴파일 과정에서 이를 못찾으면 NOPs가 들어간다.
- 코드 최적화도 이뤄지지도 않을 수 있다.
- 레이턴시가 다른 명령어가 있다면 문제가 발생할수도 있다.
- 따라서 퍼포먼스가 엄청 좋아지지는 않는다.
- 하지만 대부분의 컴파일러가 VLIW를 지원했으며 컴파일 과정에서 이를 반영하기 쉽다면 적용하기 쉽다.
3) Superscalar Execution

- n wide superscalar마다 한 사이클에 n개의 명령어가 패치된다. 이를 위해 하드웨어가 복잡해진다.
Multiple-Issue Datapath responsibilites

- 동적으로 여러 명령어를 패치하면 데이터 디팬던시 이슈가 많아질 수 있다. 또한 컨트롤 해저드나 구조적 해저드도 더 많이 발생한다.
Out of Order(OoO) Execution

- 효율적으로 위의 문제를 해결하기 위한 것
- 명령어 이슈: 명령어가 들어오는 단계
- 명령어 컴플리션: 명령어가 끝나는 단계
- 명령어 커밋: 결과를 레지스터 파일 등에 업데이트하는 단계
-> 위의 서로다른 동작을 할 수 있는 개념이 있다.
- In-order issue with in-order completion: 이슈된 순서대로 끝나도록 디자인한다.
- In-order issue with out-of-order completion: 들어온 것과 상관없이 먼저 끝낼 수 있는 것은 끝낸다.
- Out-of-order issue with out-of-order completion and inorder commit: 들어오는거나 끝내는 것의 순서를 바꿀 수 있다. 다만 순서대로 커밋을 한다. 이에 따라 결과는 유지한다.
In-order issue with in-order completion

- 이를 가정하고 얘기를 했었다.
- 예제)

- 명령어를 한 사이클에 두개씩 패치할 수 있다. I2는 한사이클이 걸려서 일찍 끝나지만 I1은 더 늦게 끝난다. In order with in order는 이를 허용하지 않기에 기다린다.
- I4는 I3와 동일한 연산을 할수 없기에 이를 기다렸다가 사용한다.
- 이에 따라 8 cycles이 걸린다.
In-order issue with out-of-order completion

- I2가 I1보다 먼저 끝날수도 있다. 즉 오래걸리는 오퍼레이션이 있을 때 더 효율적으로 할 수 있다.
- 리소스 충돌이 있다면 충돌을 하는 것은 당연하긴 하다. 따라서 데이터 디팬던시를 해결하는 방법은 아니다.
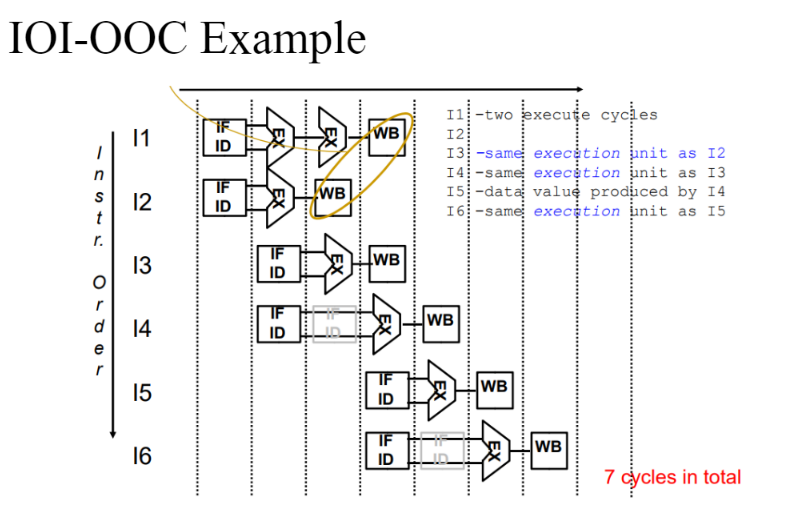
- 8사이클 걸렸던 것이 1사이클이 더 빨리 끝날수도 있다.
- 이는 In-order issue with in-order completion보다 퍼포먼스를 더 올릴수도 있다.
Handling Output Dependencies

- I1, I2는 R3에 쓰고, I5는 R3에서 read할 때는 문제가 될 수 있다. In-order issues with in order issues라면 문제가 안되지만 결과값이 바뀔 수 있다. 이러한 경우에는 문제가 될 수 있다. 이를 output dependency라고 한다. 이러한 문제를 피하기 위해서는 stall이 있을 수밖에 없다. 이러한 디펜던시가 있다면 하드웨어에서 이를 체크한 뒤 stall하도록 해야한다.
Out-of-order issue with out-of-order completion

- Issue하는 순서도 바꾼다.
- Conflict가 있는 것을 넘어서 패치 디코드를 한다. 만약 충돌이 있다면 stall했었어야했지만 이를 stall하지 않고, 뒤에 있는 것을 돌린다.
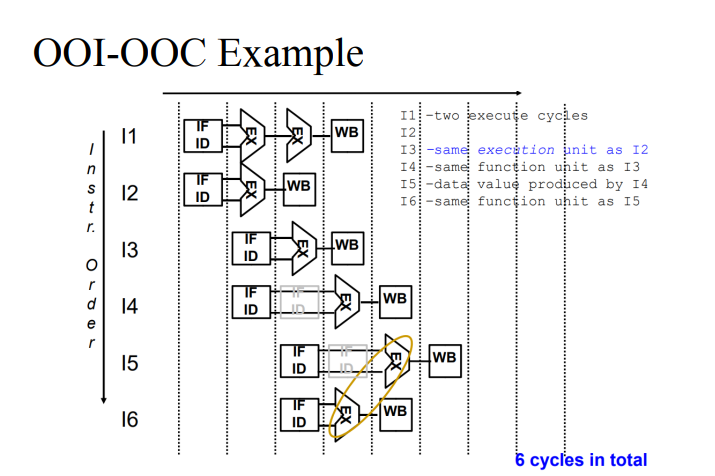
- 이때 In-order issue with out-of-order completion보다 사이클을 더 줄일 수 있다.
- Instruction을 바꾼 것은 아니다.
Antidependencies

- data dependency는 stall을 해서 문제를 해결했다. 이는 read after write이기에 문제가 발생할 수 있다.
- Write before read의 문제가 있을수도 있다.
디팬던시 리뷰

- super scalar와 out-of-order를 하면서 안티 디팬던시와 아웃풋 디팬던시가 발생한다. 이는 하드웨어가 체크해야하기에 복잡하고, stall도 해야하기에 쉽지 않다.
- true 디펜던시는 레지스터의 개수가 제한되어있기에 문제가 될 수 있다.
Storage Conflicts and Register renaming

- 디펜던시 이슈가 있을 때 스톨하는 것이 아닌 레지스터의 이름을 변경해서 구분할 수 있다. 하드웨어 내에서는 이러한 목적의 레지스터가 있다. 하드웨어가 결국 리네임을 해서 디펜던시 이슈를 줄일 수 있다.
Superscalar Execution TradeOffs

- 하나씩만 패치해도 복잡해서 디펜던시가 발생하기에 장단점이 있다.
- IPC를 높일 수 있지만 디펜던시 체킹을 해야하기에 복잡도가 늘어난다. 또한 하드웨어 리소스가 더 많이 필요하게 된다.
SuperScalar Summary

- 리소스 충돌(구조적 해저드), 컨트롤 해저드, 데이터 해저드 등의 문제가 발생한다.
- 이는 멀티쓰레드와 함께 사용하면 유용하다.
'강의 내용 정리 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터 구조(12), Memory Hierarchy & Caches (0) | 2022.06.13 |
|---|---|
| 컴퓨터 구조(11), Multithreading (0) | 2022.06.13 |
| 컴퓨터 구조(9), Control Dependence Handling: Predicated Execution and Loop Unrolling (0) | 2022.06.11 |
| 컴퓨터 구조(8), Branch Prediction (0) | 2022.06.08 |
| 컴퓨터 구조 (7), Pipelining (0) | 2022.05.23 |