2022. 6. 8. 23:59ㆍ강의 내용 정리/컴퓨터구조

- 브랜치가 존재할 때 이를 어떻게 처리해줘야하는가
- 브랜치 예측을 잘 해야한다.
- 브랜치 예측을 하기 위해서 아래의 세 정보가 필요하다.

1. 패치한 명령어가 브랜치인지 아닌지 확인
2. 조건에 따라 어디로 가는가 (branch direction): taken이나 not taken이냐
3. taken인 경우 어디로 가야하는가.
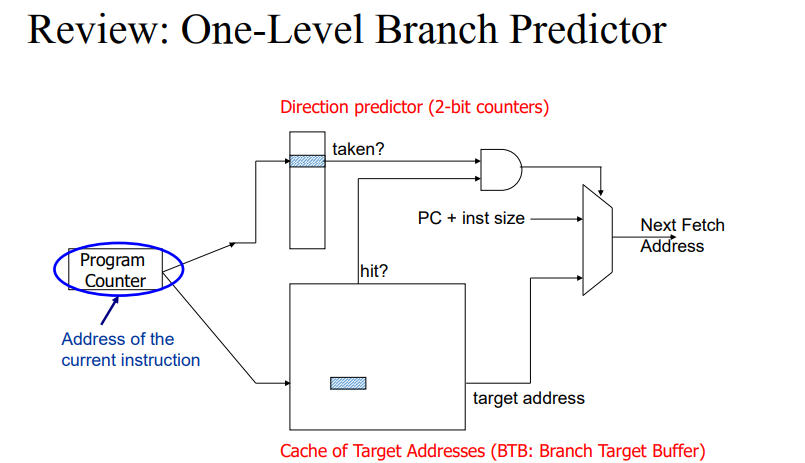
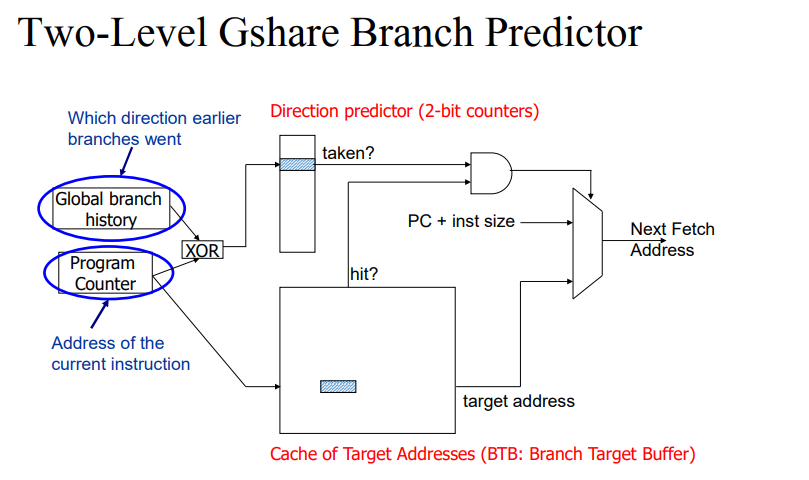
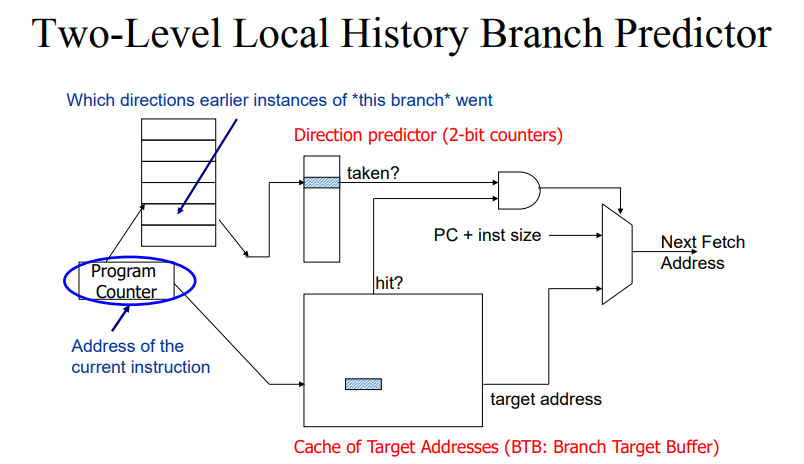
- 타겟 어드레스가 프로그램 실행 과정에서 남아있게된다. 이를 이용해서 예측에 사용하자는 개념이다. 이를 BTB에 저장한다.
- 타겟 어드레스를 저장하는 공간을 BTB를 부른다. 이는 메모리에 올리자니 접근 시간이 오래걸리고 레지스터에 넣자니 공간이 부족하다. 이에 따라 효율적으로 저장하기 위한 공간인 캐쉬에 저장한다.
그림

- 아래 박스(Cache of Target Addresses)에 도달하면 이전에 branch taken인 경우 그 Address를 저장한다. 초기에는 0 값을 넣다가 target address가 남아있다면 branch인지 아닌지 알 수 있다. 실제로 taken했을 때 남아있다면 그 값을 꺼내서 주면 target address를 계산할 필요가 없어진다.
- 이때 taken이냐 not taken이냐는 Direction predictor에 이전에 taken했는지 안했는지에 대한 정보가 남게된다.
- Direction predictor와 BTB가 둘 다 1이라면 다음 패치에 이 값을 넣는다.
- 처음에는 당연히 계산을 해야하지만 다음에 체크할 때는 더 효율적으로 계산할 수 있게된다.
- Direction predictor가 있으면 훨씬 높은 prediction이 가능하다.

- 1번과 3번은 BTB를 통해 해결할 수 있다. 2번의 경우 branch direction을 어떻게 예측할지는 아래의 정보를 활용하면 문제를 해결할 수 있다.
Direction Prediction

Dynamic branch prediction
- 런타임에 결정된다. 이 경우가 Complie time에 예측을 하는 것보다 훨씬 정확하게 된다.
- Last time prediction: 바로 직전에 taken했으면 이번에도 taken한다고 예측한다.
- two-bit counter based prediction: 바로 직전과 그 전의 정보를 바탕으로 예측한다.
- two-level prediction: 글로벌, local 등을 모두 본다.
Dynamic Branch Prediction의 장단점

- taken이 여태 얼마나 발생했는지에 따라 브랜치가 달라지기에 정확도가 높아진다.
- 이전 정보를 저장하기 위한 하드웨어가 더 필요하다.
Last time prediction의 오토마타

Last Time Predictor

- 하나가 틀리더라도 이후에 계속 맞힌다면 정확도가 높다. 반면 아래와 같이 TN이 반복된다면 정확도가 모두 틀리게 된다.
- 다만 컴파일 타임에는 반영하지 않는다.
위의 문제를 해결하기 위한 Last time predictor의 개선 사항

- 2비트를 할당하고, 이를 가지고 예측한다. 2비트로 각 브랜치마다 테이큰인지 아닌지 예측하기에 two-bit counter로 발전한다.

- 위의 개선사항을 반영했을 때 50%의 정확률로 올릴 수 있다.
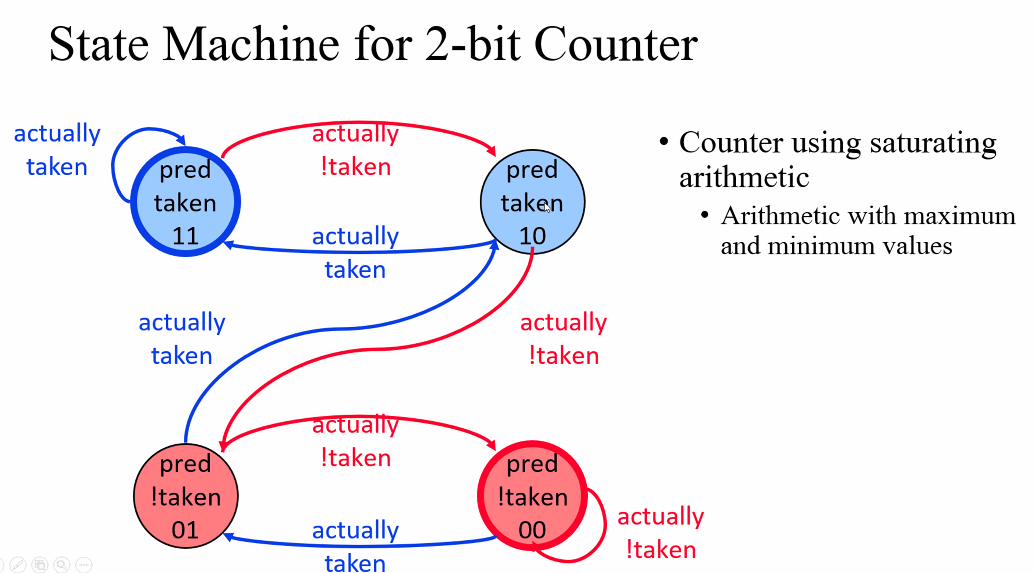
- taken에서 taken으로 예측한 경우에는 연속으로 틀려야지 not taken으로 바꾼다.
- 위의 내용을 아래와 같이 수정할 수 있다.
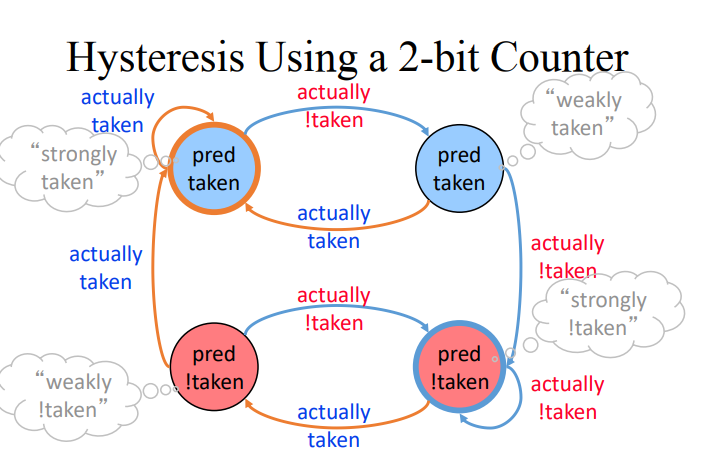
- taken으로 예측을 했을 때 두번 연속 not taken인 경우 혹은, 반대의 경우는 위와 같이 표현할 수 있다.

- Direction predictor에 1비트나 2비트를 위와 같이 남겨놓는 경우에는 성능이 아래와 같이 높아질 수 있다.

- 2비트 환경에서 85~90% 가량 정확도가 늘어난다.
Two-Level Prediction

- 어떻게 더 정확하게 할까를 고민하다가 나온 의견
1. 다른 branch's outcome과 관련이 있다. global branch를 사용한다.
2. 같은 branch's outcome도 관련이 있다. 하나의 브랜치에서 어떤 패턴이 있다고 가정한다.
Global branch correlation

- 첫번째 브랜치가 not taken이면 두번째 브랜치도 not taken이다.

- 브랜치들 간에 관계가 있다.

- global T/NT history를 고려해서 예측에 활용하고자 해서 이를 하드웨어에 저장해서 성능을 올리고자 했다.
- GHR: 글로벌 히스토리 레지스터로 여기에 글로벌 브랜치의 히스토리를 저장한다.
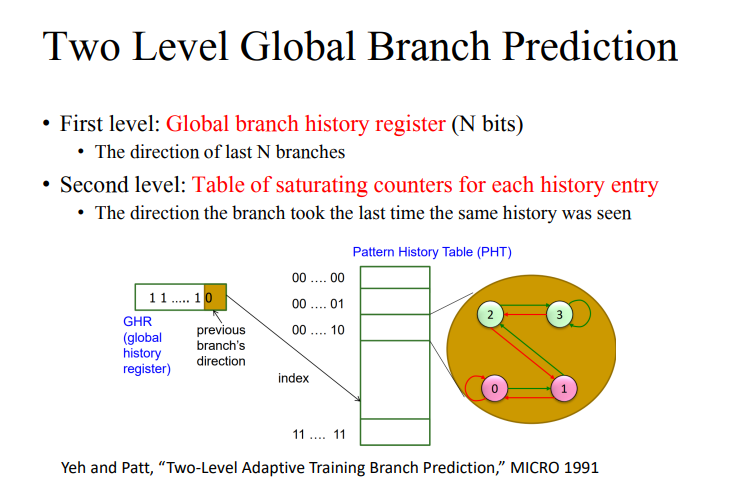
1. GHR에 이전에 브랜치 정보를 저장한다.
2. 어떤 패턴이 등장했을 때 taken, not taken이 어떻게 발생하는지 이를 저장해서 테이블에 인덱싱을 한 뒤 이를 예측한다. 이때 2의 n승만큼 테이블이 존재하게 된다.
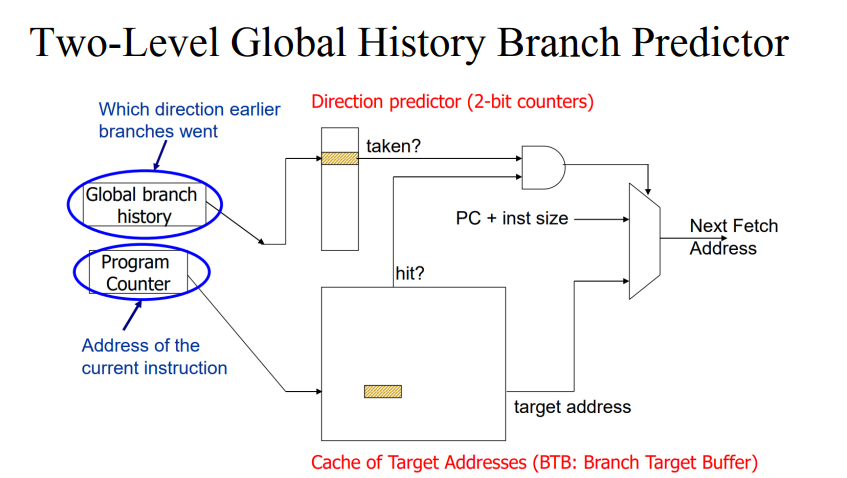
- 이에 따라 위의 GBH를 하나 더 만들어야한다.
- 이는 인텔 팬티엄에서 사용되었다.

발생할 수 있는 이슈
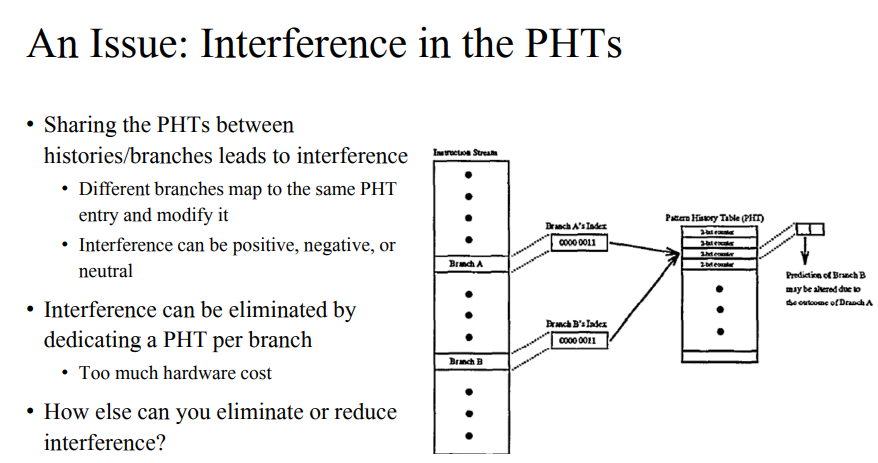
- 2의 n승만큼 PHT가 생기기에 이를 적절한 수로 조절해서 사용해야하는데 이때 위와 같이 branch A와 B의 상태가 서로 다를 때 간섭이 일어나서 다 틀리게 될 수 있다.
- 다른 브랜치가 같은 패턴을 가지고 있을 수 있고, 이의 경우에는 상충이 되어 이슈가 발생할 수 있다. 이러한 이슈를 줄이기 위해서는 globally가 아닌 매 브랜치마다 다 할당해주면된다. 하지만 이 경우에는 하드웨어가 너무 비싸진다.
위의 이슈를 줄이기 위한 방법

1. PHT의 사이즈를 증가시킨다. GHR에서 사용하는 비트수를 늘린다. 하지만 돈이 더 많이 든다. 1비트당 2배씩 늘어난다.
2. Branch filtering: 문제가 되고 매우 Biased된 문제는 PHT 테이블을 업데이트하는데 사용하지 않고, 특별히 관리한다.
3. Hashing/index-randomization: 일반화된 문제 해결 방법

- 많은 브랜치가 하나의 디랙션으로 biased되어있다. 이 경우엔 PHT를 업데이트하지 않고 따로 관리하면 된다. 하지만 이 경우는 문제가 되는 것을 미리 알아야한다.
Global predictor Accuracy의 개선
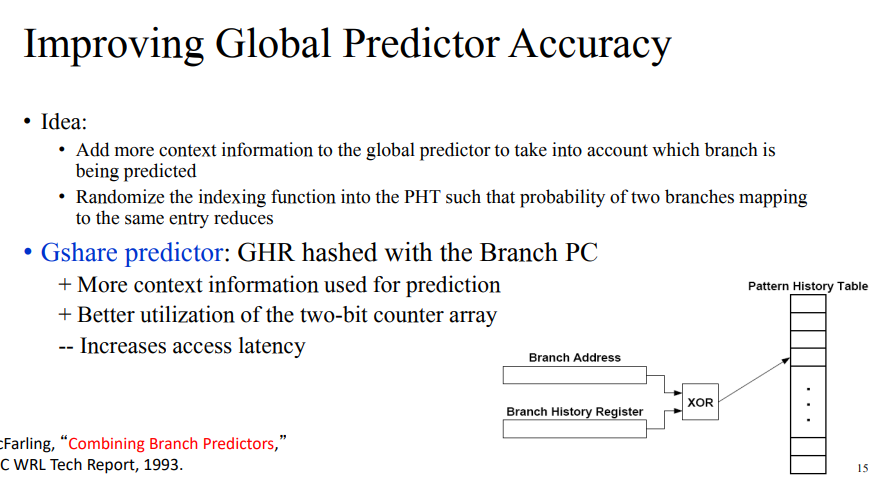
- 어떤 브랜치인지에 대한 정보를 더해서 인덱싱을 한다.
- PHT의 내용을 모두 골고루 사용하지 않는다. 그렇기에 인덱스는 randomize해준다. 그리고 서로 다른 브랜치가 같은 앤트리로 가는 확률을 줄이는 기법이 도입된다. 이를 위해 Branch Address와 Branch History Register를 xor로 사용해서 이를 랜덤하게 뿌린다. 이때 latency가 조금 생길수는 있지만 two-bit counter array를 더 잘 쓰기 위한 방법이다.
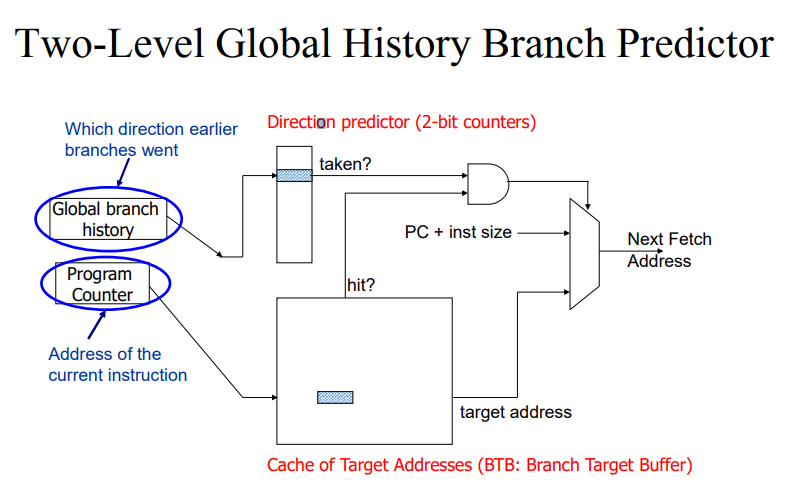
- 위의 내용을 아래와 같이 바꿀 수 있다.
- 위와 같이 사용하면 다른 엔트리를 사용할 수 있게된다.
Gskew
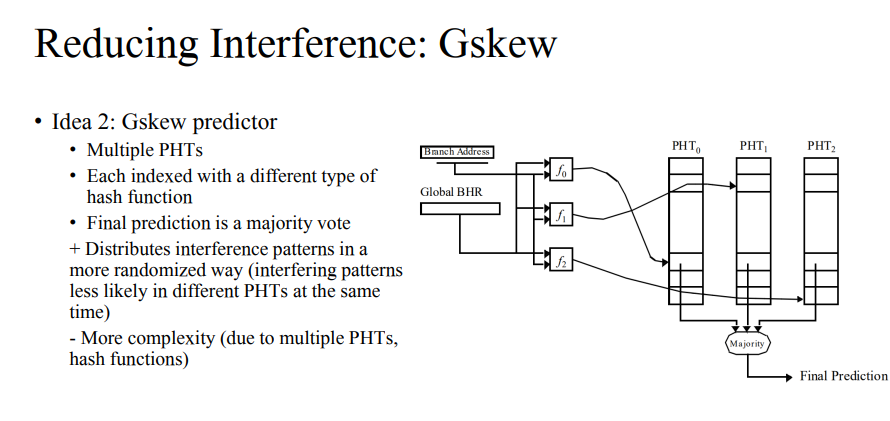
- xor를 하더라도 겹칠 수 있기에 이를 랜덤하게 더 많이 만들어준다.
- PHT를 여러 개로 만든 뒤, 여러 해쉬 함수를 통해 각각의 PHT에 대응되게한다. 이후 다수결을 통해 이를 일반화해서 예측이 더 잘되도록 한다. 단점은 complexity가 늘어나고 하드웨어가 더 많이 소모된다는 점이다.
Local branch correlation을 활용해 더 좋은 예측을 하고자 한다.

예시)

- 위와 같은 반복문이 있다면 0111이 나온 뒤면 이후에는 0, 1110이 나온다면 1이라는 것을 예측할 수 있다.
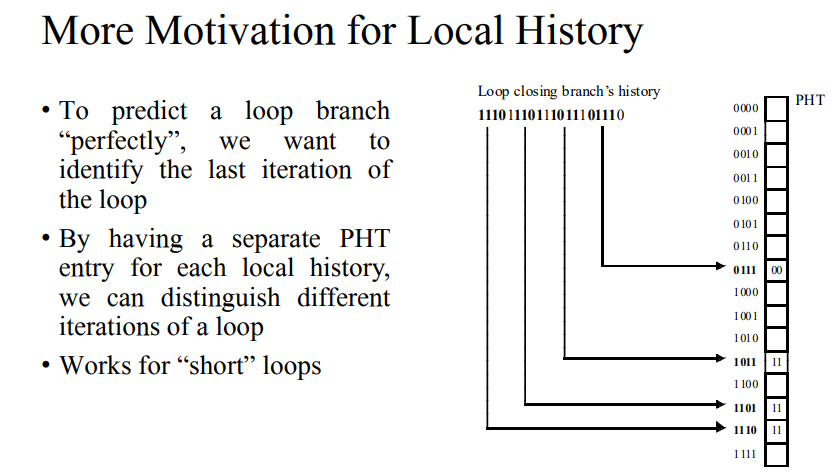
- 브랜치마다 이를 한다면 매우 높은 정확도를 가질 수 있게된다. 하지만 값이 매우 많이 나간다.
per-branch history register

- 브랜치마다 히스토리를 두면 좋기에 해당하는 브랜치의 패턴을 가지고 예측을 한다는 것이 포인트이다. 비용이 매우 많이 든다.
- two level을 하면 정확도를 높일 수 있다.
- 정말 맞추기 어려운 브랜치는 위와 같이 사용할 수 있다.
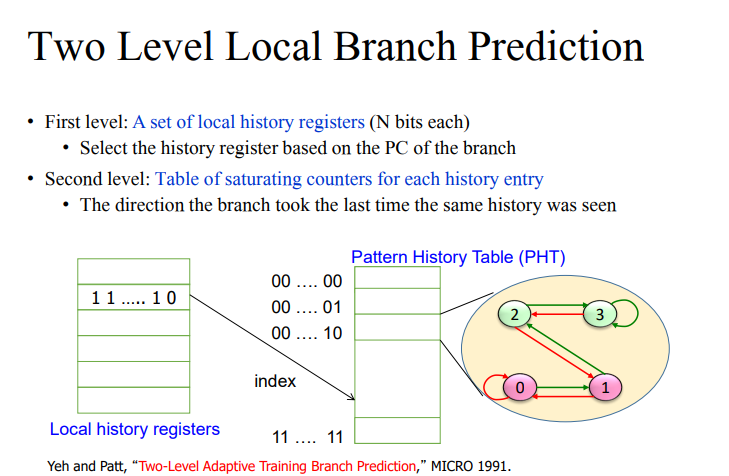
- PC값에 따라 branch history가 각각 다르게 관리되고, PHT는 모두 공유한다.
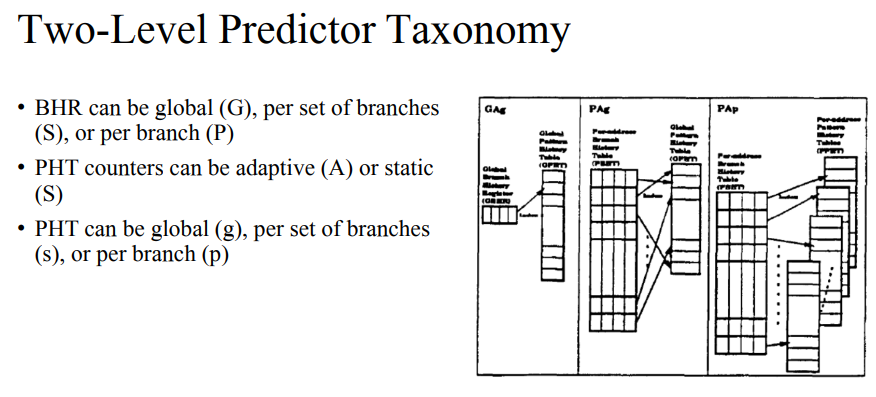
- 각각 가능한 것들에 대해 위와 같이 일반화해서 설명할 수 있다.

- 몇몇 브랜치는 local이, 몇몇 브랜치는 globally한 게 예측이 잘될 수 있다. 각 브랜치마다 어떤 패턴을 사용해야지 더 잘 맞출 수 있는지는 다르다. 그러다보니 heterogeneity가 있다. 이에 따라 하나의 방법을 사용해 다 맞추고자 하는 것도 어렵고, 모든 브랜치에 대해 다 할수도 없기에 heterogeneity를 적용해서 사용하기도 한다.
Hybrid branch predictors

- 예측이 더 잘되는 것들에 따라 predictor를 골라서 사용한다.
- 동적으로 예상하는 것 중에 잘되는 것을 골라서 사용하기에 정확도를 더 높일 수 있다.
- warmup time: 처음 예측할 때 히스토리가 없기에 이를 쌓는 시간으로 하이브리드를 사용하면 이를 줄일 수 있다.
- 메타 프레딕터: 어떤 프레딕터를 사용해야하는지 선택하는 것으로 이것을 새로 만들어야한다.

- 위와 같이 하이브리드를 사용하는 경우에는 성능이 매우 좋아진다.
- spec에 있는 gcc의 경우에는 이상적으로는 35개를 맞추지만 제일 잘한 것을 보니 9개를 예측할 수 있다.
'강의 내용 정리 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터 구조(10), Super Scalar (0) | 2022.06.12 |
|---|---|
| 컴퓨터 구조(9), Control Dependence Handling: Predicated Execution and Loop Unrolling (0) | 2022.06.11 |
| 컴퓨터 구조 (7), Pipelining (0) | 2022.05.23 |
| 컴퓨터 구조 (6), Single-cycle MIPS processor (0) | 2022.04.28 |
| 컴퓨터 구조 (5), Instruction Set Architecture 02 (0) | 2022.04.21 |