2022. 10. 21. 18:59ㆍ강의 내용 정리/데이터베이스
SELECT 문
1. SELECT 문
1) SELECT 문은?
관계 대수의 실렉션, 프로젝션, 조인, 카티션 곱 등을 결합한 것을 의미한다.
관계 데이터베이스에서 가장 자주 사용된다.

- SELECT 절과 FROM 절은 필수적인 절이며 나머지는 선택적으로 사용할 수 있다.
- SELECT 절 뒤에 어트리뷰트가 들어가서 이는 관계 대수의 프로젝션을 의미한다.
- WHERE 절 뒤에 조건이 들어가는데 이는 관계 대수의 셀렉션에 의미한다. 이는 튜플에 대한 조건이다.
- 조건을 작성할 때 중첩 질의를 사용할 수도 있다.
- GROUPBY는 그룹화를 위해 사용한다.
- HAVING 절은 그룹이 만족시켜야하는 조건을 명시한다. 이는 그룹에 대한 조건이다.
- ORDER BY 절은 정렬하기 위해 사용된다.
ex) SELECT 3 x 3;을 하면 에러가 나올 수도 있고, 일부 DB에선 9의 값이 나오기도 한다.
cf) HAVING 절은 aggregation에 대한 조건을 의미하는 것으로 생각하면 된다.
2) alias(별칭)

셀렉션에서 서로 다른 릴레이션에 동일한 이름을 가진 애트리뷰트가 속해있을 때 애트리뷰트의 이름을 구분하는 방법이다. 동일한 어트리뷰트 이름이 없다면 테이블의 이름을 굳이 붙이지 않아도 된다.
예시)
FROM EMPLOYEE As E, Department As D;를 하는 경우
EMPLOYEE.DNO -> E.DNO로 표현 가능
3) 모든 애트리뷰트나 일부 애트리뷰트들을 검색

*을 사용한다.

혹은 원하는 어트리뷰트들의 이름을 열거해서 어트리뷰트를 검색할 수 있다.
4) 상이한 값들을 검색
DISTINCT
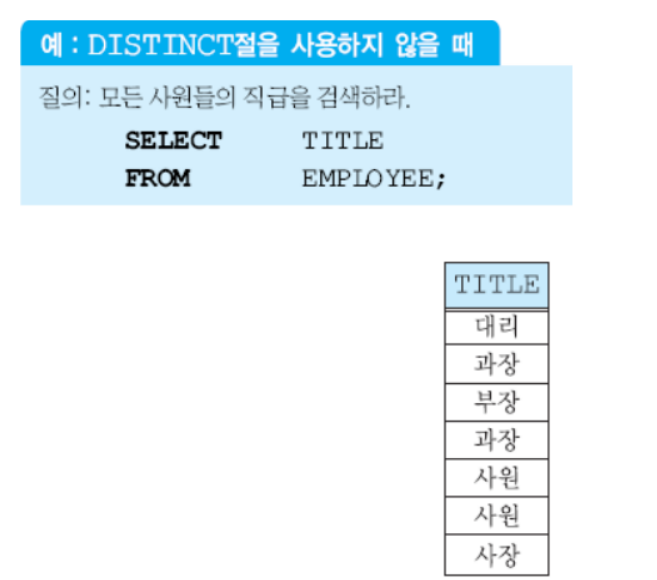
관계 대수에서는 중복을 허용하지 않지만 SQL의 테이블은 중복을 허용한다. 관계 대수의 릴레이션처럼 튜플의 중복을 허용하지 않기 위해 DISTINCT 키워드를 사용할 수 있다.

중복된 값이 없이, 유니크한 값을 확인할 수 있다.이때 DISTINCT는 튜플에 적용되기에 튜플의 쌍이 중복되는 값이 있는지를 찾는다. (이는 디비전과 비슷하다.)
5) 특정한 튜플들의 검색
WHERE 절을 사용하여 검색 조건을 명시
LIKE 비교 연산자

문자열 타입에서 값들을 비교할 때 사용할 수 있다. 이는 와일드 문자와 함께 사용된다.
- %: 0개 이상의 임의의 문자와 매칭(임의 길이의 문자와 매칭)
- _: 하나의 임의의 문자와 매칭(임의의 하나의 문자와 매칭)
SQL에서 문자열은 '로 묶어서 사용된다.
예시
- 학번이 9로 끝나는 학번인 경우: LIKE '%9'
- 20학번 중 학번이 9로 끝나는 학번인 경우: LIKE '2020%9'
- 이씨 성을 가진 사람 중 이름이 외자인 사람: LIKE '이_'
- 이씨 성을 가진 사람 중 이름이 두자인 사람: LIKE '이__'
6) 다수의 검색 조건

아래의 SELECT 문은 문법적으로는 맞지만 논리적으로는 맞지 않다. 위의 예시는 무조건 불가능하게 된다.
연산자의 우선순위를 고려하는 것도 중요하다.

<>: 부정 검색 조건은 같지 않다는 의미인 <>를 사용해 표현한다.
7) 범위를 사용한 검색
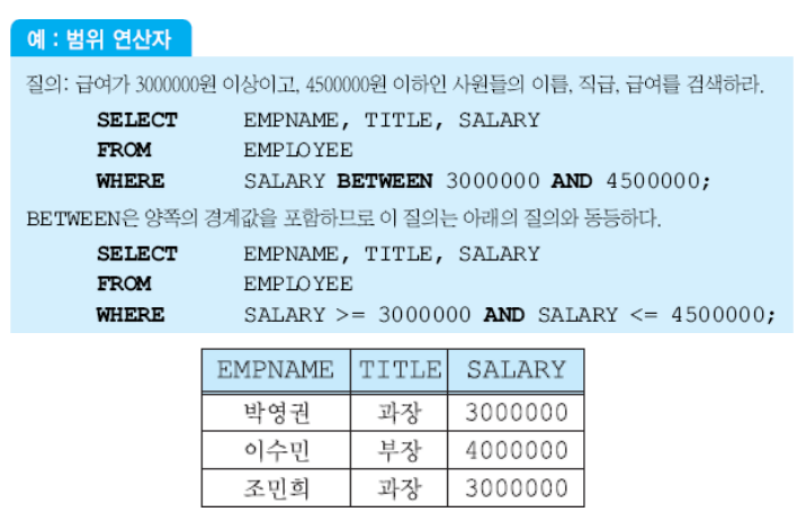
BETWEEN ~ AND ~를 사용하여 이를 표현할 수 있다. 가독성이 더 좋은 표현이다.
BETWEEN을 작성할 때는 왼쪽에 작은 값, 오른쪽에는 큰 값이 들어가야한다. 또한 이는 끝 값이 포함된다.
8) 리스트를 사용한 검색
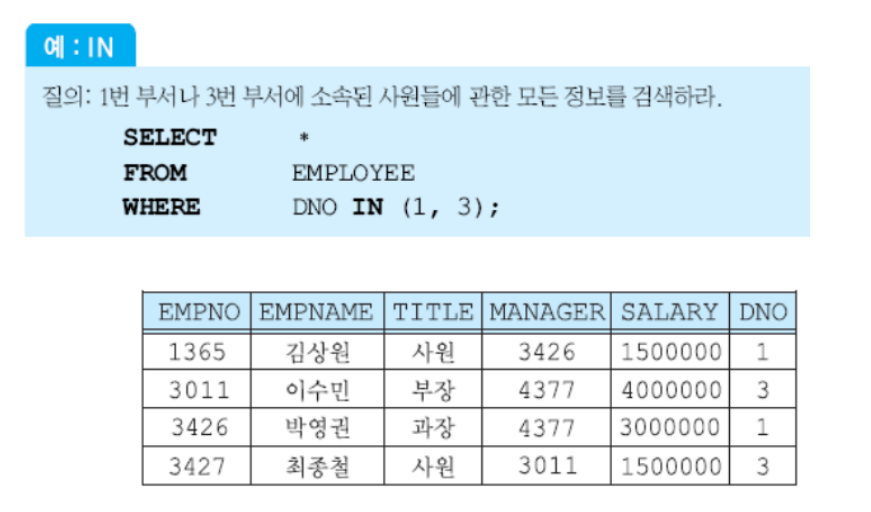
IN을 사용해서 이를 사용할 수 있다. 리스트는 ,로 연결된 것을 괄호로 묶어 표현할 수 있다.
(DNO = 1 OR DNO = 3)와 같다.
9) 산술 연산자 사용

어트리뷰트 이름이 아닌 산술연산자를 어트리뷰트의 위치에 사용할 수 있다. 데이터베이스에 있는 값에 산술 연산을 해서 구할 수 있다.
AS NEWSALARY의 별칭을 사용하지 않으면 결과 테이블 내에서 산술식이 어트리뷰트 이름이 된다.
10) 널값


널값을 포함한 연산식을 사용한다면 그 결과는 널이 된다.
집단 함수는 널값을 제외하지만 COUNT(*)를 하는 경우에는 널값도 포함한다. COUNT함수는 릴레이션 내의 튜플 개수를 반환하는 특수한 집단 함수이다.
어떤 어트리뷰트의 값이 NULL인가를 비교하기 위해 DNO=NULL과 같이 표현하는 것은 불가능하다.
이는 IS NULL과 같이 표현해야한다.
정확한 표현으로는 위에 대한 결과는 false가 아니라 세가지 값 논리에 의해 결과가 나온다.
11) 세가지 값의 논리
true/false/unknown이 있다.
unknown에 대한 not 연산은 unknown이다.

논리 값을 숫자와 산술연산자를 사용해 표현할 수 있다.
12) Order by절
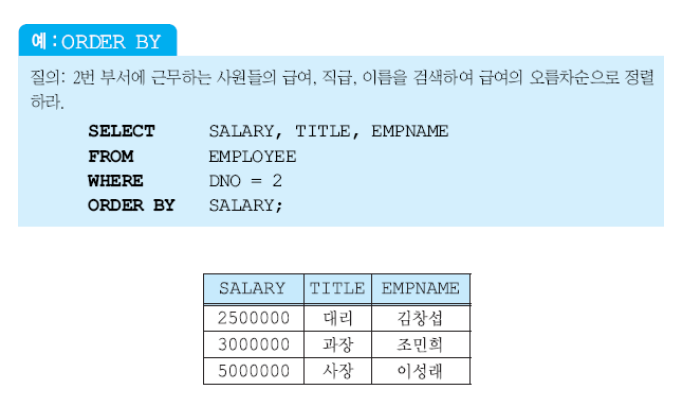
사용자가 select문에서 질의 결과의 순서를 명시하지 않으면 사용자에게 제시되는 순서가 정해져있지 않음
디폴트값은 오름차순이다.
만약 두 가지 이상의 정렬조건을 입력할 때는 ,로 구분해 어트리뷰트를 작성할 수 있다.
ex) ORDER BY SALARY, TITLE <=> ORDER BY SALARY ASC, TITLE ASC
ex) ORDER BY SALARY ASC, TITLE DESC
13) 집단함수
sql에서 사용하기 위해 GROUPBY 절을 사용할 수 있다. 혹은 MIN, MAX, AVERAGE, SUM, COUNT를 사용할 수 있다.
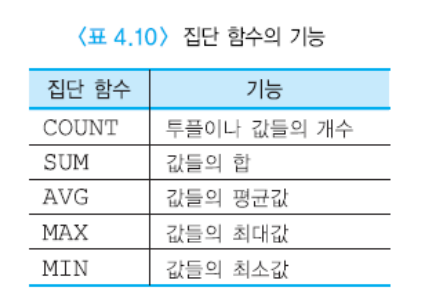

만약 AVG(SALARY)만 사용할 경우에는 컬럼의 이름도 AVG(SALARY)가 된다. 이에 따라 별칭을 사용할 수 있다.
COUNT(*): 튜플의 개수를 센다.
ex) SELECT COUNT(*) FROM EMPLOYEE; -> 사원의 튜플 개수를 센다.
COUNT 함수 같은 경우에는 다른 함수와는 다르게 널값을 포함하여 계산한다. 다른 함수는 널값을 빼고 계산한다.
* 오퍼레이터는 COUNT에서만 사용될 수 있다. *인 경우에는 NULL 값을 포함한다.
ex) 튜플 중 NULL이 있다면 COUNT(A): 3, COUNT(*): 4가 될 수 있다.
ex) SUM(*)는 불가능하다. SUM에는 어트리뷰트 하나만 사용될 수 있다.
ex) COUNT(DISTINCT A): A 컬럼에서 DISTINCT한 값을 제거한 뒤, 이를 포함한다.
A
---
50
25
NULL
25
일 때
COUNT(*): 4;
COUNT(A): 3;
COUNT(DISTINCT A): 2;
14) 그룹화
GROUP BY절
GROUPBY를 사용하면 그룹별로 튜플이 하나씩 등장한다. 그룹에 대한 이름이 결과 릴레이션에 포함되어야한다.

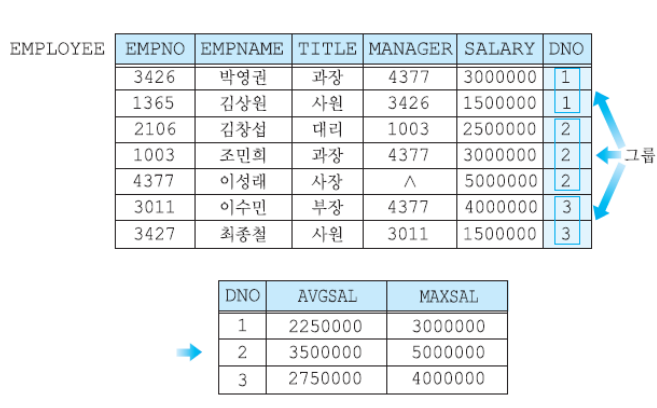
HAVING 절
그룹 중 어떤 조건만 만족하는 경우만 출력하고자 할 수 있다.
이때 집단 함수에서만 사용되는 조건일 때 HAVING절을 사용할 수 있다.


WHERE 절은 그룹화를 하기 전에 튜플을 선택하기 위한 조건절이다. 그 이후 GROUPBY, HAVING 절이 있다면 GROUPBY 절이 처리된 후 HAVING절이 처리된다.
ex) TITLE이 과장인 사원들에 대해 부서별 평균 급여를 계산하시오.
SELECT DNO, AVG(SALARY)
FROM EMPLOYEE
WHERE TITLE == '과장'
GROUPY BY DNO;
ex) TITLE이 과장인 사원들에 대해 부서 평균 급여가 5,000,000 이상인 부서와 평균 급여를 출력하시오.
SELECT DNO, AVG(SALARY) AS AVGSAL
FROM EMPLOYEE
WHERE TITLE == '과장'
GROUP BY DNO
HAVING AVGSAL >= 5000000;
- 별칭도 사용할 수 있다.
15) 집합 연산
합집합 호환성이 적용되어야지 해당 연산을 할 수 있다.
ALL이 있는 경우에는 중복을 허용하는 집합, ALL이 없는 경우에는 중복을 허용하지 않는 집합이다.


cf) 합집합 호환: 두 집합의 차수가 같아야하고, 각각의 도메인이 같아야한다.
cf) SELECT는 가로로 묶어서 표현이 되는데 이는 서브쿼리, 중첩 질의라고 한다.
ex)
R 릴레이션
A
---
3
5
7
S 릴레이션
B
---
5
9
R UNION S
A
---
3
5
7
9
컬럼 이름은 앞에 있는 것을 따르는 경우가 일반적이다.
R UNION ALL S
A
---
3
5
5
7
9
UNION을 해서 중복 튜플을 삭제하는 것이 오버헤드가 크기 때문에 이를 사용하는 것보단 최종적으로 결과 테이블을 출력할 때는 UNION ALL을 하는 것이 좋을 수도 있다.
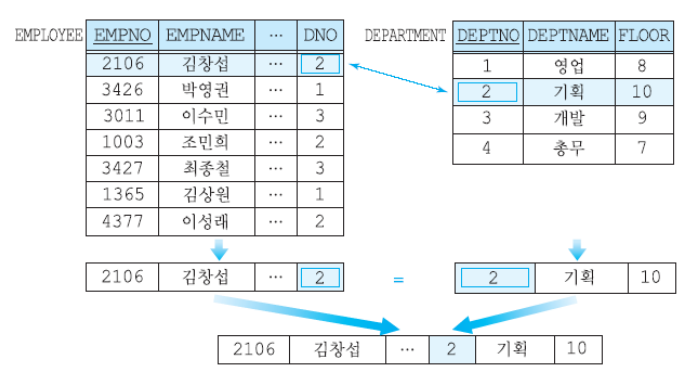
16) 조인
카디션 곱은 모든 결합에 대해 곱하는 것이고, 조인은 주어진 조건에 맞는 튜플들만 조합된다.
이에 따라 어떤 튜플들이 연관이 있는지 조인 조건에 명시해줄 수 있다.
가장 많이 사용되는 것은 동등조인이다. <비교 연산자>가 되어있는 것은 세타 조인이 된다.
자연 조인은 FROM 절에 명시할 수 있다.
조인 조건을 잘못 주게되면 카티션 곱이 될 수 있다.
두 릴레이션의 동일한 이름을 갖는 어트리뷰트가 있다면 이를 혼동하지 않도록 어트리뷰트 앞에 릴레이션이나 튜플 변수의 이름을 붙여 혼동을 피할 수 있다.
cf) 튜플 변수: 릴레이션에 대한 별칭
ex)
SELECT ENAME, SALARY
FROM EMP E # E: 튜블 변수(tuple, variable)
WHERE E.TITLE = '과장';
WHERE에선 각 튜플마다 모두 조건에 해당되는지 탐색한다. 이에 따라 E는 튜플 변수라고 표현한다.


자체 조인
왼쪽 릴레이션과 오른쪽 릴레이션이 동일한 경우에 조인하는 것을 의미한다.
이러한 경우에는 릴레이션이 두 개 있다고 가정한 뒤 이를 전개한다. 이를 위해 별칭을 두 개 사용해야한다.



조인과 ORDER BY의 결합
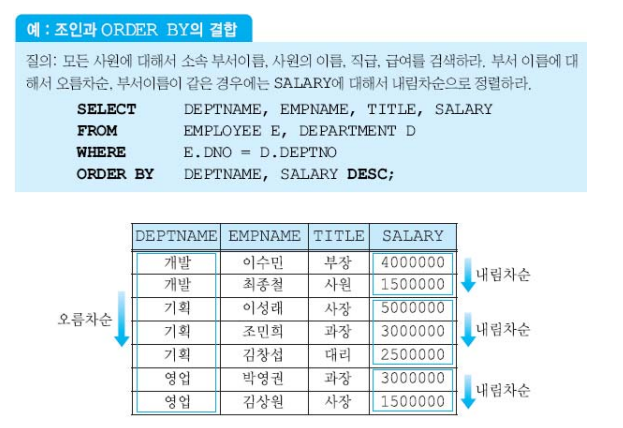
ORDER BY는 가장 나중에 처리된다.
SQL 실습
extract를 사용하면 DATE에서 특정한 연월을 끄집어낼 수 있다.
REGEXP를 사용하면 특정한 문자에 대한 정규표현식을 사용해서 끄집어낼 수 있다. ex) 'a|e'를 하면 a나 e가 있는 튜플을 뽑을 수 있다.
DUAL은 정보를 찾기 위한 더미 테이블이다. DESC를 하면 나오지 않는다. 관련 릴레이션이 없지만 릴레이션의 이름을 FROM을 통해 채우기 위해 사용할 때 쓴다.
SELECT SYSDATE AS "DATA"
FROM DUAL;
정규 식에서 ^을 사용하는 경우에는 가장 처음에 있는 문자를 의미한다.
SUBSTR(LAST_NAME, 1, 1) IN ('J', 'A', 'M')을 사용해도 해결할 수 있다.
17) 중첩 질의
WHERE 절이나 FROM 절에 다시 (SELECT ... FROM ... WHERE ...)의 형태로 포함된 SELECT 문
중첩 질의의 결과는 세 가지 경우가 있다.
- 한 개의 스칼라 값(단일 값) -> 싱글 튜플
- A
- --
- 3
- 한 개의 어트리뷰트로 이뤄진 릴레이션 -> 멀티플 튜플
- A
- --
- 3
- ...
- 여러 어트리뷰트로 이뤄진 릴레이션 -> 멀티플 어트리뷰트?
- A | B
- ------
- 3 Q
- X W

(1) 한 개의 스칼라 값이 반환되는 경우

박영권의 직급을 알아내기 위해 중첩 질의를 사용한다.
해당 중첩 질의의 결과는 문자열 하나가 나올 것을 기대한다. 따라서 이는 스칼라 값으로 변환이 되어 이를 사용할 수 있게 된다.
만약 스칼라 값이 두 개 이상이 나온다면 에러가 발생한다.
EX) 박영권이 두 명 이상인 경우에는 에러가 발생한다.
(2) 한 개의 어트리뷰트로 이뤄진 릴레이션이 반환되는 경우
한 개의 어트리뷰트로 이뤄진 릴레이션이 반환된다면 이를 리스트로 변환시켜 사용할 수 있다.
또한 결과값이 한개의 스칼라 값이 나오는 경우에도 이를 사용할 수 있다.

IN


영업 부서나 개발 부서의 부서 번호를 알기 위해 중첩 질의(부질의)를 사용한다.

중첩 질의는 중첩 질의를 사용하지 않고 표현이 가능할 때가 있다. 물론 불가능한 경우도 존재한다.
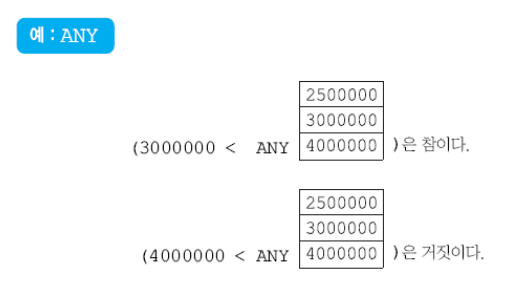
ANY
ANY, ALL은 조건(Predicate)과 같이 사용한다.
원소 중 하나라도 만족시키면 참이다.
ALL
모든 원소에 대해 만족시키면 참이다.

EXISTS
튜플이 하나라도 존재하면 TRUE, EMPTY인 경우에는 FALSE이다.

외부 질의에 있는 튜플 변수와 내부 질의에 있는 튜플 변수와 비교를 해서 판단도 가능하다.
(3) 여러 어트리뷰트들로 이뤄진 릴레이션이 반환되는 경우
(2)와 마찬가지로 IN, ANY, ALL, EXISTS를 사용해 Predicate을 사용할 수 있다. 이 경우에는 튜플의 리스트로 변환된다.
EX) 중첩 질의의 결과가 다음과 같다면 아래와 같은 리스트로 변환된다.
TITLE DNO
------------------
'가' 3
'나' 4
=> (('가', 3), ('나', 4))
2-tuple로 변환된다. (2는 원소의 개수를 의미한다.)
따라서 비교하는 개수는 위와 같이 개수를 맞춰야한다.

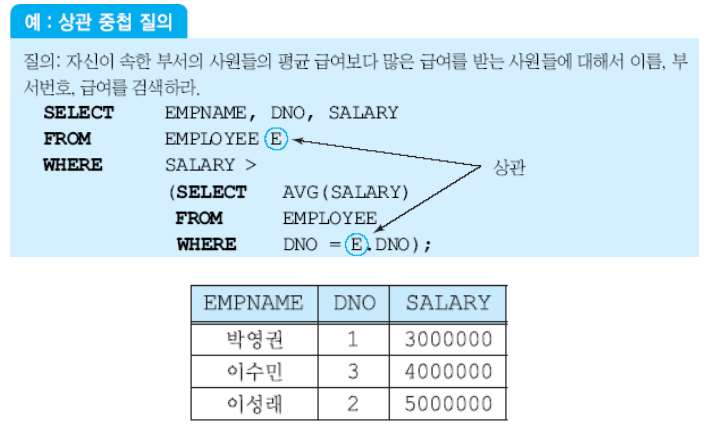
18) 상관 중첩 질의
상관 중첩 질의가 아닌 경우에는 외부 질의에서 사용한 릴레이션과 상관 없이 사용이 된다. 외부 질의에서 사용한 WHERE 절은 외부 질의의 튜플 개수만큼 수행하게 된다. 상관 중첩 질의가 아니라면 부질의는 한번만 값을 구하고, 이미 구한 값을 기준으로 계속 체크하게 된다.
상관 중첩 질의인 경우에는 매 WHERE절마다 연산의 결과값이 달라지기에 이를 사용해야한다.
FROM 절에서 사용된 중첩 질의
해당 질의를 사용할 때에는 이름을 붙여서 사용해야한다.

'강의 내용 정리 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스(7), 내포된 SQL (0) | 2022.10.25 |
|---|---|
| 데이터 베이스(6), DML, 트리거와 주장 (0) | 2022.10.21 |
| 데이터 베이스(4), SQL 개요 및 데이터 무결성 (0) | 2022.10.21 |
| 데이터 베이스(3), 관계 대수와 SQL (0) | 2022.10.19 |
| 데이터베이스(2), 관계 데이터 모델과 제약조건 (0) | 2022.10.15 |