2022. 10. 19. 23:40ㆍ강의 내용 정리/데이터베이스
관계 대수와 SQL
1. 관계 대수
1) 관계 데이터 모델에서 지원되는 두 가지 정형적인 언어
(1) 관계 해석
원하는 데이터만 명시하고 질의를 어떻게 수행할 것인가는 명시하지 않는 선언적인 언어로 이는 집합에서의 조건제시법과 유사한 특징을 가진다.
ex) {n | n is even, n in R}, {t[name] | t는 EMP에 포함된다.}
(2) 관계 대수
어떻게 질의를 수행할 것인가를 명시하는 절차적인 언어로 연산을 어떤 순서로 작성할 것인지 명시하는 것을 의미한다. sql을 처리할 때는 질의어를 관계 대수로 전환해서 처리하게 된다.
cf) SQL
DBMS의 사실상 표준 질의어
상용 관계 DBMS들의 사실상의 표준 질의어인 SQL을 이해하고 사용할 수 있는 능력은 매우 중요하다.
2) 관계 대수란?
기존의 릴레이션들로부터 새로운 릴레이션을 생성한다. 하나의 릴레이션에 관계 연산자를 적용하면 새로운 릴레이션이 만들어질 수 있다.
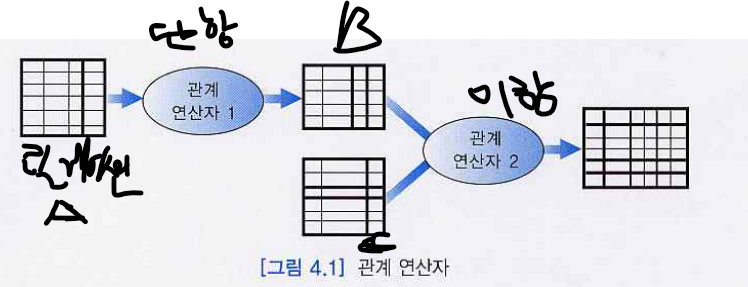
3) 관계 연산자들의 종류와 표기법

(1) 필수적인 연산자
해당 연산자들을 가지고 모든 연산처리를 할 수 있다.
ex) 합집합과 차집합이 이에 해당한다.
(2) 편의를 위해 유도된 연산자
자주 사용되는 연산에 대한 동작은 새로운 연산자로 만들어서 연산처리를 한다.
ex) 교집합이 이에 해당한다.

- 관계 대수의 항이 되는 객체는 릴레이션이기에 박스는 릴레이션에 해당한다.
- 셀렉션은 주어진 조건에 만족하는 튜플을 뽑는 것이다.
- 프로젝션은 특정 어트리뷰트를 뽑는 것이다.
- 합집합은 두 릴레이션의 중복을 제거하여 합친다.
- 교집합은 두 릴레이션의 공통적인 튜플을 뽑는다.
- 차집합은 한 릴레이션에 대해 다른 릴레이션은 없는 것을 뽑아낸다.
- 카티션 곱은 만들어낼 수 있는 모든 가능한 쌍을 만들어낸다.
- 디비전은 곱셈의 반대가 되는 개념이다. 하지만 곱셈의 역은 성립하지 않을 수 있다.
ex) 카티션 곱
R에는 a, b, c 튜플, S에는 x, y 튜플이 있다면 두 릴레이션을 카티션 곱했을 때 다음과 같은 릴레이션이 만들어진다. (a, x), (a, y), (b, x), (b, y), (c, x), (c, y)
4) 관계 연산자
(1) 실렉션 연산자
- 한 릴레이션에서 실렉션 조건을 만족하는 튜플들의 부분 집합을 생성한다.
- 결과 릴레이션의 차수는 입력 릴레이션의 차수와 같다.
- 결과 릴레이션의 카디날리티는 입력 릴레이션의 카디날리티와 같다. 결과 릴레이션 카디날리티는 입력 릴레이션의 카디날리티보다 작거나 같다. 0 <= 결과 릴레이션 카디날리티 <= 입력 릴레이션 카디날리티
- 실렉션 조건을 프레디키트라고 한다.
- <>는 같지 않음을 뜻한다.

(2) 프로젝션 연산자
- 한 릴레이션의 애트리뷰트들의 부분 집합을 구한다.
- 결과로 생성되는 릴레이션은 <애트리뷰트 리스트>에 명시된 애트리뷰트들만 가진다.
- 실렉션의 결과 릴레이션에는 중복 튜플이 존재할 수 없지만, 프로젝션 연산의 결과 릴레이션에는 중복된 튜플들이 존재할 수 있다. 따라서 카디날리티는 줄어들 수도 있다.
- 애트리뷰트의 개수는 최소 1개 이상 존재한다.
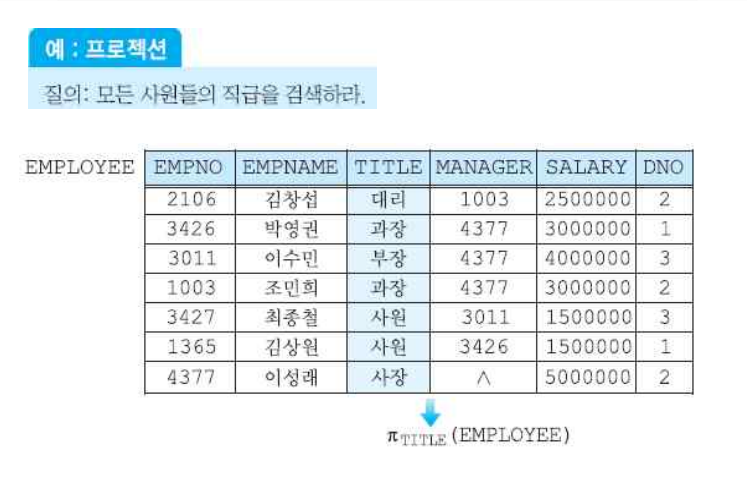

sql에서는 중복집합을 허용하지 않는 집합과 중복 집합을 사용하는 경우를 모두 사용할 수 있다. 중복집합을 사용하는 것이 sql의 디폴트 값이다.
cf) 중복을 허용하는 집합: Multi set(bag)
(3) 집합 연산자
- 릴레이션이 튜플들의 집합이기에 기존이 집합 연산이 릴레이션에 적용된다.
- 세 가지 집합 연산자: 합집합, 교집합, 차집합 연산자
- 집합 연산자의 입력으로 사용되는 두 개의 릴레이션은 합집합 호환이어야한다. 이는 튜플들이 호환가능해야한다는 의미이다. 대표적인 예시로 어트리뷰트의 개수가 같고, 동일한 위치에 있는 어트리뷰트들의 도메인이 같아서 호환이 가능해야한다. 세 가지 집합 연산자에 모두 적용된다. 어트리뷰트의 이름은 달라도 가능하다.

(3-1) 합집합 연산자
- 결과 릴레이션에서 중복된 튜플들은 제외된다.
- 결과 릴레이션의 차수는 각 릴레이션의 차수와 같으며 결과 릴레이션의 애트리뷰트 이름들은 둘 중 하나의 애트리뷰트들의 이름과 같다.
- 카디날리티는 두 집합의 카디날리티 합 - 두 집합의 교집합 카디날리티 합이 된다.
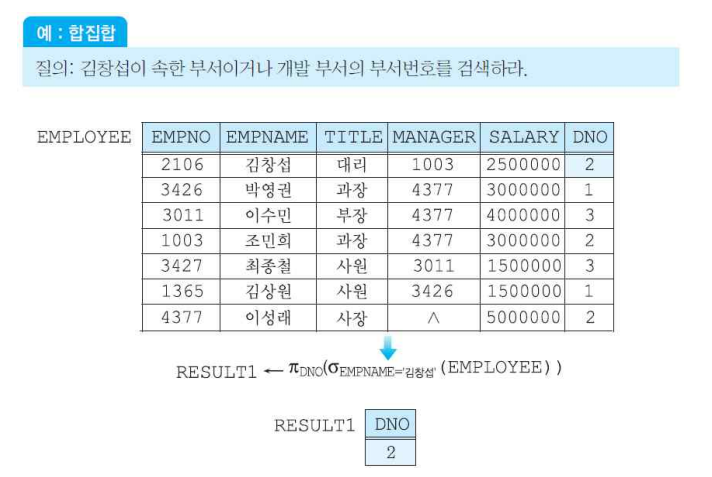
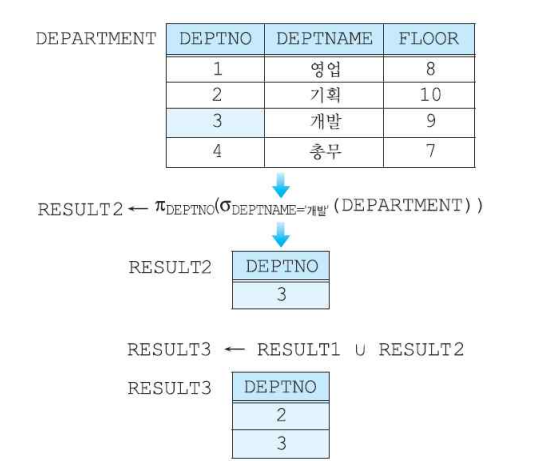
cf) renaming 연산이 있어 결과 릴레이션의 어트리뷰트의 이름을 수정할 수 있는 기능이 있다.
(3-2) 교집합 연산자
- 합집합의 개념과 비슷하다.
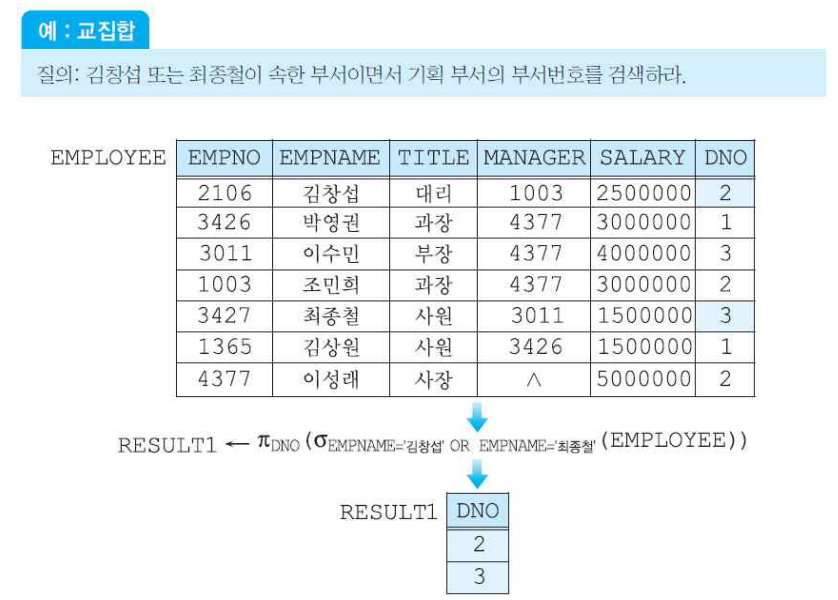

(3-3) 차집합 연산자
- 합집합 연산자의 특징과 유사하다.
- 어떤 집합의 여집합을 구할 때 차집합을 많이 사용된다.
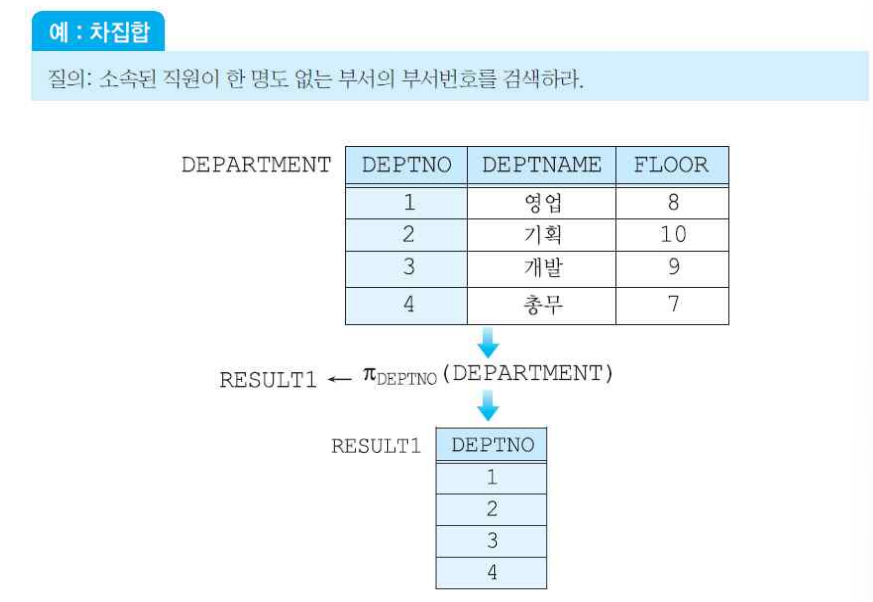
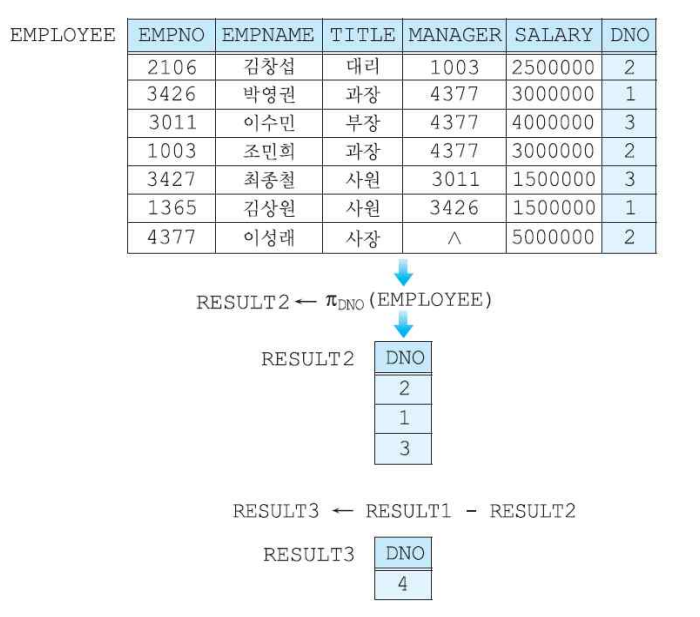
(4) 카티션 곱 연산자
- 차수는 n+m, 카디날리티는 n*m이 된다.
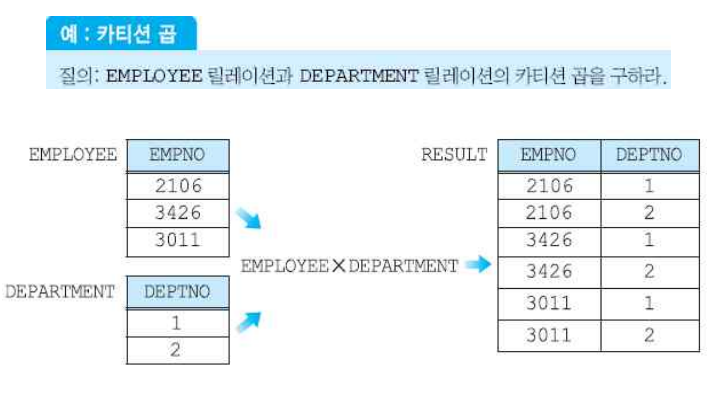
두 릴레이션에 동일한 어트리뷰트가 있는 경우에는 각 릴레이션의 이름을 어트리뷰트 앞에 붙여서 표현한다.
ex) R x S 릴레이션에서 a 어트리뷰트 이름이 동일 => R.a, S.a로 표현한다.
cf) 관계 대수의 완전성
임의의 질의어가 적어도 필수적인 관계 대수 연산자들만큼의 표현력을 갖고 있으면 관계적으로 완전하다고 말한다. sql의 표현력은 관계 대수적으로 완전하다. 즉, 관계 대수에서 표현할 수 있는 것을 sql에서는 모두 표현할 수 있다.
(5) 조인 연산자
- 두 개의 릴레이션으로부터 연관된 튜플들을 결합하는 연산자
- 연관성은 조인 조건을 주어 판단한다.
- 관계 데이터베이스에서 두 개 이상의 릴레이션들의 관계를 다루는데 매우 중요한 연산자이다.
- 세타 조인, 동등조인, 자연 조인, 외부 조인, 세미 조인 등등이 있다.
- 교환법칙과 결합법칙이 성립한다.
(5-1) 세타 조인
- 장구모양의 기호로 표현하고 실렉션 조건으로 사용했던 비교 연산자들 중 하나를 표현하기 위해 세타라는 기호를 사용한다.
- 세타 조인 결과는 두 릴레이션의 카티션 곱에 조인 조건을 실렉션한 결과와 동일하다.
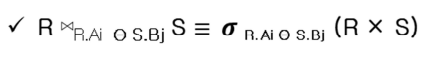
(5-2) 동등 조인
세타 조인 중에서 비교 연산자가 =인 조인이다.
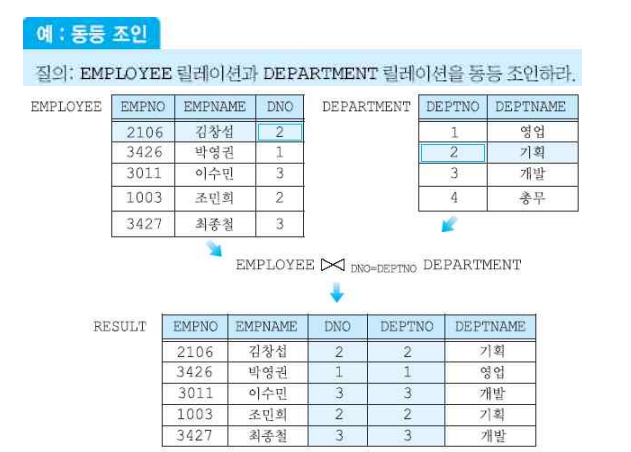
(5-3) 자연 조인
- 두 릴레이션의 공통된 어트리뷰트에 대해 동등 조인을 수행하고 동등 조인의 결과 릴레이션에 있는 두 개의 조인 어트리뷰트 중 하나를 제외한 조인
- 이는 어트리뷰트의 이름이 동일하고, 값이 동일한 값들에 대해 조인을 한다.
- 외래키를 포함한 조인을 많이 사용하기에 가장 자주 사용되는 조인 연산자이다.
- 공통된 어트리뷰트가 두 개 이상 있는 경우에는 공통된 어트리뷰트의 값들이 모두 같아야 조인을 할 수 있다.
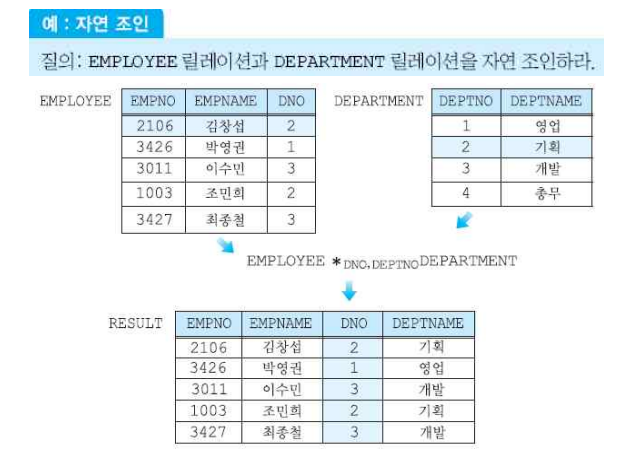
(6) 디비전 연산자
- 오른쪽 릴레이션의 모든 튜플 값과 쌍을 이루는 왼쪽 릴레이션의 튜플의 집합이 결과 릴레이션이 된다.
- 일반적으로 모든 -에 대해 ~하는 식으로 되어있으면 이를 사용하는 경우가 많다.
- SQL로 표현할 때는 동치를 활용하여 문제를 푸는 경우가 많다. ex) ~하지 않는 -가 없다.
- R % S = V일때, V x S = R이 아닐 수 있다. 짝을 이루지 않는 값이 R에 포함이 안되기 때문이다. 만약 디비전되지 않는 것들을 구하기 위해서는 R에서 프로젝션을 한 뒤, 디비전한 값을 차집합으로 구하면 된다.
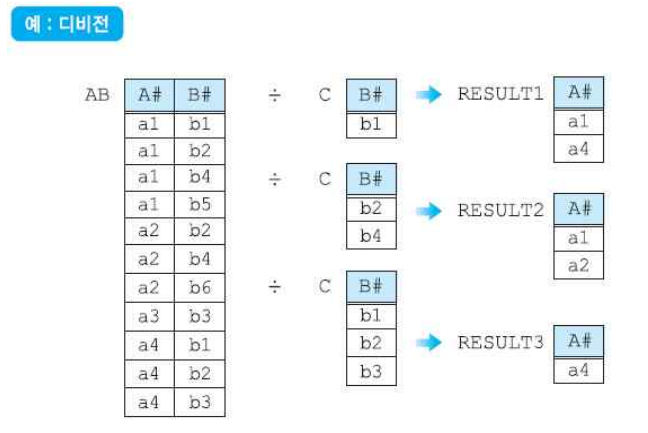
연습 문제
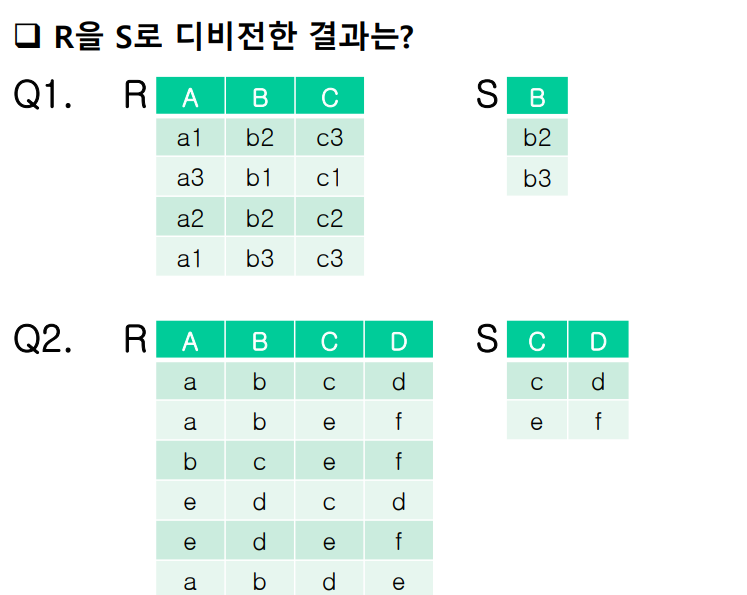
A1
- B1: (A3, C1)
- B2: (A1, C3), (A2, C2)
- B3: (A1, C3)
| A | C |
| A1 | C3 |
A2
- (c, d): (a, b), (e, d)
- (e, f): (a, b), (b, c), (e, d)
- (d, e): (a, b)
| A | B |
| a | b |
| e | d |
관계 대수 질의 예시

단순히 하나의 질의어로 처리하는 것이 아니라 여러 개의 질의어를 조합해서 사용하는 경우가 많다.
- 실렉션과 프로젝션을 사용하는 경우가 제일 많다.
- 릴레이션이 두 개 이상된다면 이를 조인하는 경우가 많다.
- 질의처리를 위해 무슨 릴레이션을 사용해야하는지 먼저 파악해야한다.
- 동일한 질의를 처리하는데 관계대수는 여러 가지 방법이 있다.
- 마지막 예시는 DEPARTMENT 테이블에서 먼저 셀렉션을 하지 않고 조인을 한 뒤 차후에 셀렉션을 해도 된다. 이는 이해하기 쉽지만 카티션 곱을 한 뒤에 셀렉션하는 것이 조인이기에 릴레이션의 크기가 매우 커져서 중간 아웃풋이 커진다. 따라서 이는 수행시간이 길어진다.
- DBMS는 동일한 결과를 내보내는 여러 관계 대수식 중에서 가장 빠른 관계 대수식을 선택해 처리하는 질의 최적화를 지원한다.
5) 관계 대수의 한계
- 관계 대수는 산술 연산을 할 수 없다. 데이터베이스는 산술 연산을 허용하도록 확장했다.
- 집단 함수(aggregate function)를 지원하지 않았다. 데이터의 통계치를 많이 사용하는데 이를 할 수 없었다.
- 관계 대수는 집합이기에 정렬을 나타낼 수 없다.
- 데이터 베이스를 수정할 수 없다.
- 프로젝션 연산의 결과에 중복된 튜플을 나타내는 것이 필요할 때가 있는데 이를 명시하지 못한다.
이를 해결하기 위해 확장된 관계 대수가 등장했다.
6) 추가된 관계 대수 연산자
(1) 집단 함수
AVG, SUM, MIN, MAX, COUNT(튜플 개수)
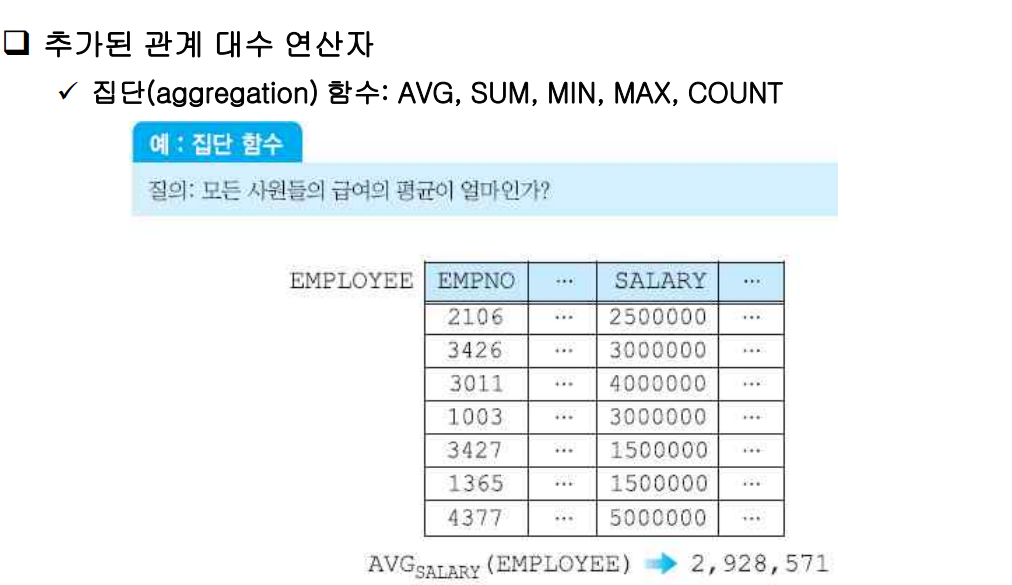
집단 함수의 결과는 릴레이션이 된다.
(2) 그룹화
각 그룹에 대해 집단 함수를 적용
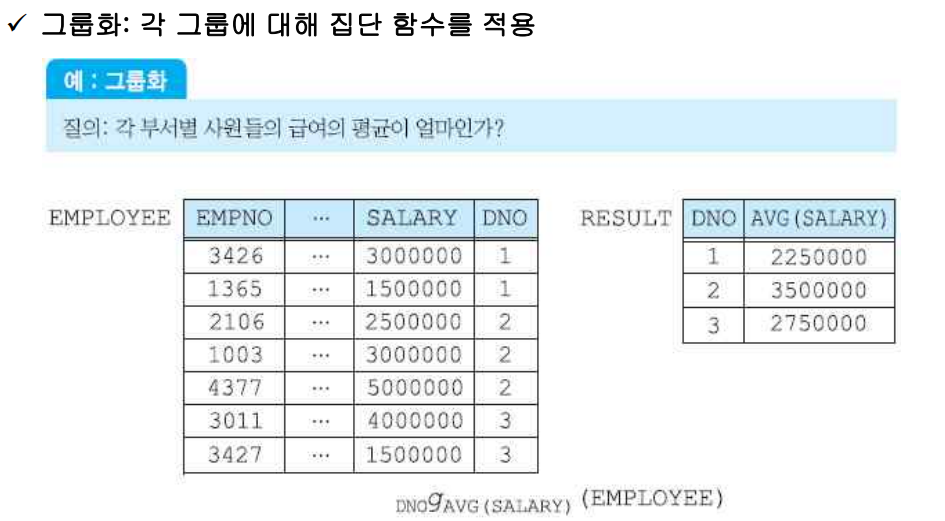
- 그룹핑 애트리뷰트 리스트: DNO가 이에 해당하고, 이는 여러 개의 애트리뷰트가 포함될 수 있다.
- 그룹화 연산은 g로 표현한다.
만약 부서 내 직급별 급여를 알고 싶은 경우에는 다음과 같이 표현할 수 있다.
DNO, TITLE g AVG(SALARY) (EMPLOYEE)
(3) 외부 조인
경우에 따라 조인조건을 만족하지 않는데 출력을 해야하는 경우가 있다. 예를 들어 학생과 지도교수간의 캡스톤 디자인을 위한 컨펌을 받아야하는 경우가 있을 수 있다.
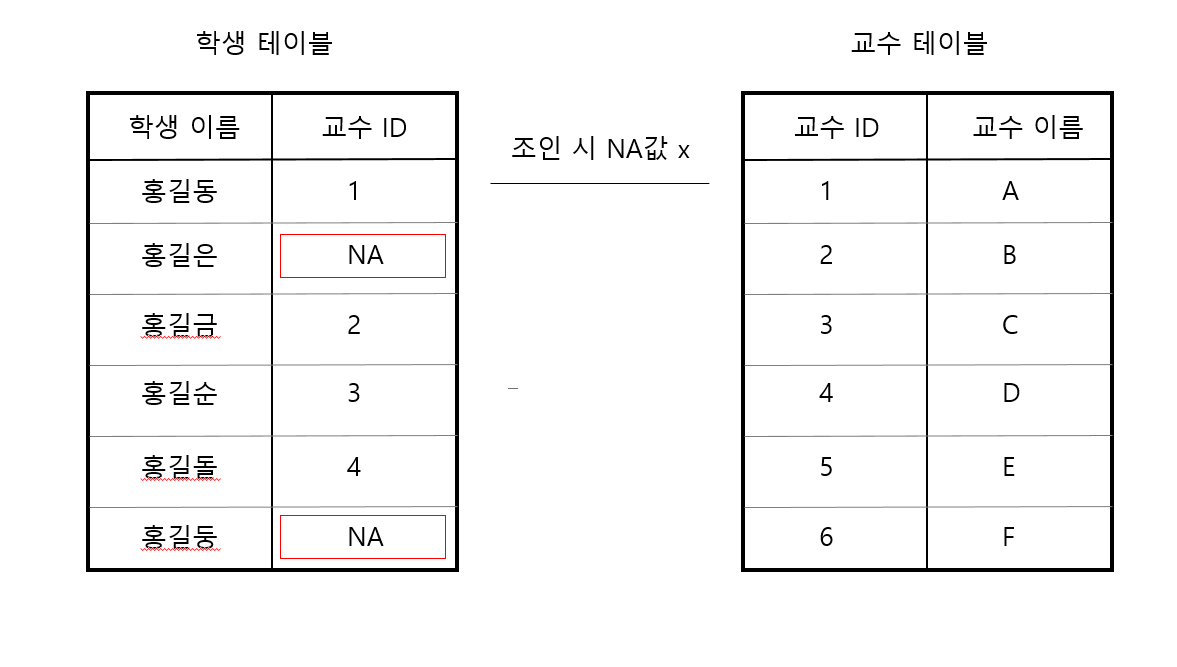
위와 같은 경우에 컨펌을 받지 못한 학생에 대한 정보도 추출해야하는 일이 필요할수도 있다. 이러한 경우에는 외부 조인을 사용한다.
(3-1) 왼쪽 외부 조인
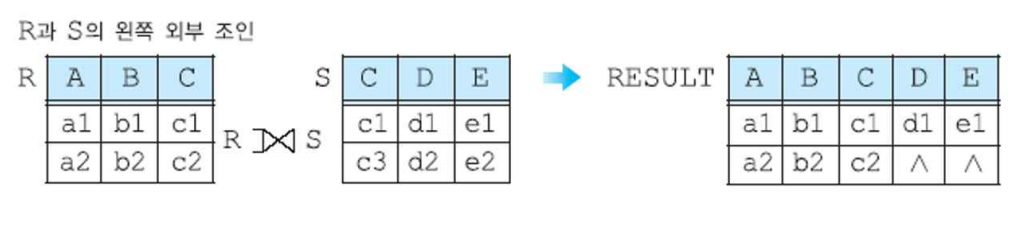
(3-2) 오른쪽 외부 조인

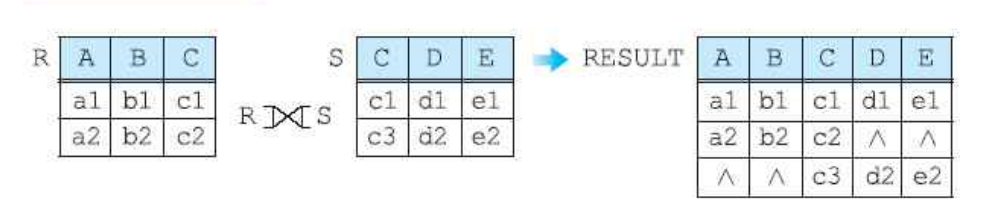
(3-3) 완전 외부조인
이는 합집합을 하는 경우과 동일하다.
연습 문제

a. 셀렉션 title= 반지의 제왕의 프로젝션 GENRE를 하면 된다.
b. 프로젝션 VIDEO_ID
c. 비디오 테이프의 프로젝션에 대해 VIDEO에서 RESERVED를 차집합한다.
d. RESERVED와 VIDEO를 자연조인하여 프로젝션하여 TITLE을 빼온다.
e. CUSTOMER와 RESERVED를 자연조인하여 NAME을 프로젝션하여 뽑는다.
f. 장르가 액션인 비디오 테이프를 셀렉션한 뒤, 그 비디오 테이프의 아이디와 RESERVED의 VIDEO_ID를 자연 조인하고, 그 CUSTOMER_ID와 CUSTMER와의 자연 조인을 한뒤, ADDRESS를 프로젝션한다.
cf) 자연 조인을 하는 경우에는 굳이 예약된 것을 찾을 필요가 없다.
디비전을 사용할 때는 왼쪽에 있는 어트리뷰트는 꼭 필요한 것만 둬야할 수 있다.
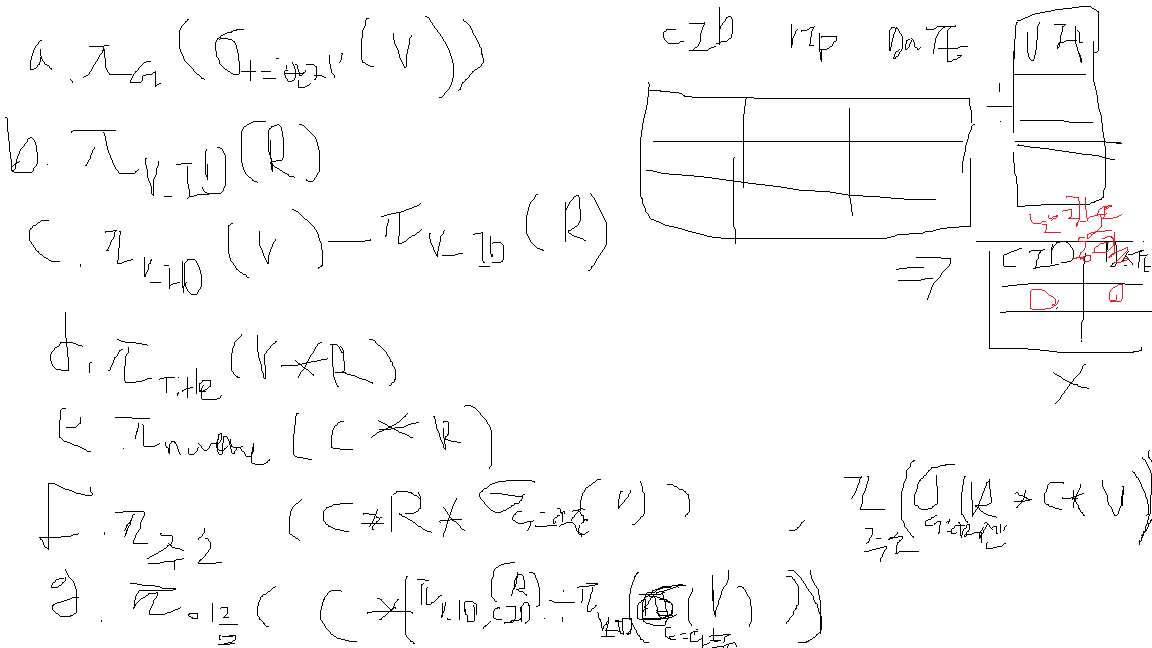
디비전을 필수연산자를 사용해서 바꿔보자! -> 시험 문제 O
'강의 내용 정리 > 데이터베이스' 카테고리의 다른 글
| 데이터 베이스(6), DML, 트리거와 주장 (0) | 2022.10.21 |
|---|---|
| 데이터베이스(5), SELECT문 (0) | 2022.10.21 |
| 데이터 베이스(4), SQL 개요 및 데이터 무결성 (0) | 2022.10.21 |
| 데이터베이스(2), 관계 데이터 모델과 제약조건 (0) | 2022.10.15 |
| 데이터 베이스(1), 데이터베이스 시스템 (2) | 2022.09.19 |