2022. 9. 19. 15:49ㆍ강의 내용 정리/데이터베이스
데이터베이스 시스템
1. 데이터베이스 시스템 개요
1) Relational DBMS(RDBMS)의 종류
- MySQL: 개인이 사용하는 경우가 많았다.
- PostgreSQL: 조직에서 사용하는 경우가 많았다.
- MariaDB: MySQL이 유료화로 되자 이와 유사한 MariaDB가 나왔다.
- MS SQL Server
- IBM DB2
- Tibero: Tmax Soft에서 만들었다.
- Cubrid
- MongoDB: 문서나 파일을 저장관리하기에 좋다.
cf) NoSQL는 Not only SQL의 약자로 SQL과 더불어 다른 기능을 제공하는 제품군을 의미한다.
기존에는 산업계의 표준으로서 RDBMS를 사용했었다. 하지만 컴퓨터 기술이 발달함에 따라 Big data가 대두되며 테이블형태만으로 데이터를 관리하기 어려워졌고, 이에 따라 NoSQL이 등장했다. 이러한 NoSQL의 대표적인 예시는 MongoDB이다.
cf) 빅데이터의 특징으로는 Volume, Velocity, Variety가 있다.
2) 데이터 베이스란?
정보와 데이터는 다르다. 데이터로부터 프로그램 처리를 해서 나온 결과가 정보이다.
데이터 베이스란 조직체의 응용 시스템들이 공유해서 사용하는 운영 데이터들이 구조적으로 통합된 모임이다. 데이터베이스의 구조는 사용되는 데이터 모델에 의해 결정된다.
조직체는 회사나 학교 등이 될 수 있다. 조직체 내부에서는 다양한 부서가 존재하는데, 부서들 간에 일부 데이터는 공통적으로 사용하고, 일부는 따로 따로 사용하는 경우가 존재한다. 만약 각 부서들은 원본 데이터의 사본을 가지고 있을 때, 업데이트가 된다면 잘못된 데이터를 가질 수 있다. 따라서 데이터를 모두 공유해서 사용해서 이러한 문제를 해결한다. RDBMS의 경우 행과 열의 형태로 구조적인 모습으로 데이터를 저장한다.
3) 데이터 베이스의 특징
- 데이터 베이스는 데이터의 대규모 저장소로서, 여러 데이터를 효과적으로 저장할 수 있다.
- 중복을 최소화하며 데이터를 저장한다.
- 데이터를 다루기 위한 데이터(메타 데이터, 데이터베이스 스키마)도 포함된다.
- 프로그램과 데이터 간의 독립성이 제공된다.
- CPU리소스를 적게 사용해 빠르고 효율적으로 접근하고 질의를 할 수 있다.
4) 데이터 베이스 용어

(1) 데이터 베이스 관리 시스템
데이터베이스를 정의하고 관리하는데에 도움을 주는 소프트웨어
(2) 데이터베이스 스키마
전체적인 데이터베이스의 구조를 뜻하는 것으로 자주 변경되지 않는다.
데이터 베이스의 가능한 예상되는 상태를 미리 반영해서 정해 놓는다. 내포(intension)이라 한다.
(3) 데이터베이스 상태
특정 시간의 데이터베이스의 내용을 의미하며, 이는 시간이 지남에 따라 변할 수 있다.
저장되어있는 정보들의 집합이라고 생각하면 된다. 외연(extension)이라 한다.

시스템 카탈로그는 메타데이터에 대한 정보가 들어있다. 사용자가 직접 DBMS를 이용해서 질의를 날리고 결과를 전달받을 수 있다. DBMS에는 데이터 베이스가 포함되어있다. 또는 시스템을 사용해 보고서 같은 것을 받아서 볼 수 있다. DBMS는 따로 있지만 특정한 업무에 맞게 응용프로그램을 만들어서 엔드유저가 사용할 수 있다.
Ex) 수강신청 프로그램 -> 수강 신청 성공 -> DB에 저장
(4) 데이터 베이스

- 시스템 카탈로그와 저장된 데이터 베이스로 구분할 수 있다.
- 시스템 카탈로그는 저장된 데이터베이스의 스키마 정보를 유지한다.
5) 컴퓨터 시스템에서 DBMS의 위치
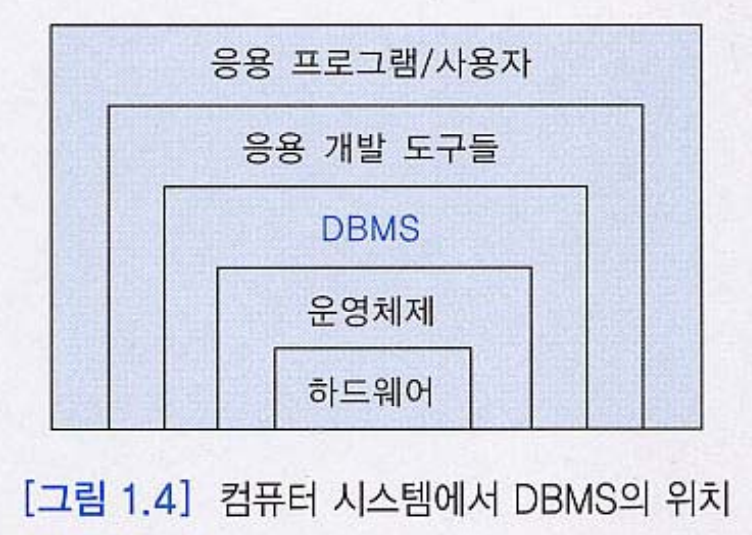
일반적인 사용자는 응용 프로그램을 사용하기에 하드웨어, 운영체제, 응용 프로그램의 순서로 위치해있다.
cf) 시스템 소프트웨어
운영체제나 DBMS, 미들웨어가 이에 해당한다. 운영체제와 운영프로그램 사이에 들어가는 소프트웨어를 의미한다. 응용프로그램을 잘 다룰 수 있게 도와준다.
6) 데이터 베이스 시스템의 요구사항
- 데이터 독립성
- 효율적인(빠른) 데이터 접근
- 데이터에 대한 동시 접근(Concerency): 여러 부서에서 데이터를 동시에 접근할 수 있다.
- 백업과 회복: 트랜잭션 롤백 포스팅 체크, 로그가 영구히 남는 것도 이에 해당한다.
- 중복을 줄이거나 제어하며 일관성 유지
- 데이터 무결성: 데이터에 대한 제약조건을 잘 지키도록 DBMS가 보장하는 것
- 데이터 보안
- 쉬운 질의어
- 다양한 사용자 인터페이스
2. 파일 시스템 vs DBMS
1) 파일 시스템을 사용한 기존의 데이터 관리
DBMS가 없었을 때는 데이터를 관리하기 위해 파일을 만들어서 이를 저장했다. 데이터를 읽을 때도 파일을 열어서 이를 관리했다. 따라서 이를 관리하기 위한 파일 시스템이 있었다. 파일은 기본적으로 레코드를 하나씩 저장했다. 레코드란 개체에 대한 연관된 필드(속성)를 모아놓은 것을 의미한다. 파일을 접근하는 방식이 응용 프로그램 내에서 상세하게 표현된다. 즉, 프로그램을 통해서 파일에 접근을 해야했기에 서로 밀접한 관계를 가지게 된다. 이 방법에 맞춰서 데이터들이 저장되어야하고, 읽을 수 있기에 서로 독립적일 수 없었다.

응용 프로그램에는 각 데이터 파일이 어떤식으로 저장되어있는지 데이터 정의가 있다. 따라서 각 응용프로그램과 데이터 파일은 서로 대응되는 관계를 가진다.

위의 예시는 휴대폰이 대중화되어 파일 구조에 새로운 필드가 들어간 것을 적어주는 예시이다. 만약 하나의 응용 프로그램에서만 필드를 수정하고 파일을 수정하는 경우에는 다른 응용프로그램에서는 구조가 맞지 않아 열 수 없었다. 즉, 독립성이 없기에 필드 갱신에 어려움을 겪는다.
또한 파일시스템의 경우 데이터가 많은 파일에 중복해서 저장된다. Employee 파일에는 address 필드가 있고, enrollment 파일에는 course 필드가 있고, 이는 서로만 가지고 있는 데이터이다. 하지만 그 외의 필드에 대해서는 공통적인 데이터를 따로 각각 저장한다. 스토리지도 낭비가 될 뿐더러 한쪽에서만 데이터를 업데이트하는 경우에는 데이터의 일관성이 깨질 수 있다.
그 외의 단점들이 존재한다. 하지만 이러한 문제를 해결하기위해 DBMS가 등장했고, 이러한 단점들을 해결할 수 있었다.
윈도우 파일시스템 예시: NTFS(NT file system), FAT32(File Allocation Table), FAT16
리눅스 파일시스템 예시: extfs
2) DBMS의 특징
(1) DBMS의 특징
프로그램과 데이터의 독립성이 생긴다. 통합된 데이터베이스를 가지고 데이터를 관리한다. DBMS에서는 질의 처리, 트랜잭션 처리 등을 하며 응용 프로그램과 데이터 간의 독립성을 보장한다. 트랜잭션은 데이터베이스에 접근해 일을 처리하는 것을 의미한다.
(2) DBMS의 단점
- 추가적인 하드웨어 구입 비용이 든다.
- 직원들의 교육 비용도 든다.
- 데이터를 모두 한 곳에서 관리하기에 프라이버시 노출의 단점이 존재할 수 있다.
- 초기 투자 비용이 많이 들 수 있기에 조직 규모가 작다면 파일 시스템을 이용하는 것도 방법이 될 수 있다.
(3) 화일 시스템 방식과 DBMS 방식의 비교

3) DBMS 선정 시 고려 사항
기술적/경제적 요인으로 이를 살펴볼 수 있다.
(1) 기술적인 요인
- DBMS가 사용하는 데이터 모델이 무엇인지, DBMS가 지원하는 사용자 인터페이스(like 버튼을 통해 저장), 프로그래밍 언어나 질의 언어(sql 등), 응용 개발 도구, 저장 구조, 성능, 접근 방법 등등을 고려해 결정한다.
- DBMS는 응용 프로그램을 잘 개발할 수 있도록 도와주는 역할을 하는 것이 중요하다. 혹은 보고서를 얼마나 다양하게 생성하는지 등등을 하는 것도 중요하다.
(2) 경제적 요인
- 소프트웨어와 하드웨어 구입 비용, 유지보수비용, 직원 교육 지원 등등
4) 데이터베이스 시스템
- 데이터를 통합해서 사용한다.
- 데이터를 공유해서 여러 부서에서 함께 사용한다.
- 데이터를 구조적으로 저장한다. -> 이 구조를 데이터 모델이라 한다. 모델에 따라 데이터베이스의 이름이 달라진다.
cf) RDBMS 등등
외연: 데이터 베이스 상태 -> 데이터 베이스에 저장된 튜플의 모임으로 이는 바뀔 수 있다.
내포: 데이터 베이스 스키마
3. DBMS의 발전과정
1) 데이터 모델
데이터 베이스의 구조를 기술하는데 사용되는 개념들의 집합인 구조(데이터 타입과 관계), 이 구조 위에서 동작하는 연산자들, 무결성 제약조건들 등등을 의미한다. 여기에서 데이터 타입이란 튜플을 의미하며 데이터 모델을 통해서 레코드 간의 관계를 표현할 수 있다.
cf) 추상화자료형은 데이터 도메인(데이터 타입에 대한 데이터 집합)과 자료형에 대한 연산자에 대해 포함해야한다.
무결성 제약조건이란?
나이를 입력할 때 어느 범위를 가지는지 등등 저장되는 데이터에 대해 추가적인 제약조건을 데이터 모델에서 표현할 수 있다.
추상적 표현이란?
실세계에 있는 것들 중 의미가 있는 것을 뽑아서 저장하는 것을 의미한다.
2) 데이터 모델의 분류
사람이 이해하기 쉬운 형태인 경우에는 고수준, 기계 입장에서 표현된 것은 저수준으로 표현한다.
(1) 고수준 또는 개념적 데이터 모델
사람이 인식하는 것과 유사하게 데이터 베이스의 전체적인 논리적 구조를 명시한다. 엔티티-관계 데이터 모델이 이에 대한 대표적인 예시이다. UML, 객체지향 데이터 모델도 이의 예시이다.
(2) 표현(구현) 데이터 모델
최종 사용자(사람)가 이해하는 개념이면서 컴퓨터 내에서 데이터가 조작되는 방식과 멀리 떨어져있지는 않다. 계층 데이터 모델, 네트워크 데이터 모델, 관계 데이터 모델이 이에 대한 대표적인 예시이다.
(3) 저수준 또는 물리적인 데이터 모델
데이터베이스에 데이터가 어떻게 저장되는가를 기술한다. 물리적인 데이터 모델을 표현하는 프레임워크가 있다기 보단 저장 방법의 예시를 의미한다. Unifying, ISAM, VSAM 등등이 이의 예시가 된다.
3) DBMS 발전 과정

계층: 트리 구조
네트워크: 그래프 구조
설계 도면을 저장하고 관리하는 경우에는 관계 DBMS가 적합하지 않았다. 따라서 특수한 경우에는 객체 지향 DBMS를 통해 저장하기도 했다. 객체 지향 DBMS는 task oriented를 중심으로 이뤄져있었다. 이에 따라 동시성 제어 및 롤백 등등에 대한 기능이 없었다. 그래서 관계 DBMS와 객체 지향 DBMS를 합쳐서 객체 관계 DBMS로 함께 발전되었다. 최근에는 객체 관계 DBMS이지만 관계 DBMS를 기준으로 하기 때문에 관계 DBMS라고 표현하기도 한다.
(1) 계층 DBMS
트리 구조를 기반으로 하는 계층 데이터 모델을 사용한 DBMS이다. 특정 유형에 대해서는 빠른 속도와 높은 효율성을 제공한다. 예를 들어 트리 구조에 맞는 데이터 모델에서는 매우 빠르게 처리가 가능하다. 하지만 어떻게 데이터에 접근하는 가를 미리 응용프로그램에 명시적으로 정의해야한다. 링크로 연결되어있기에 레코드 구조를 어렵다.

위와 같이 트리 구조인 경우에는 데이터를 찾아 관리하는 것이 매우 효율적이다.
ex) 프로젝트2를 개발한 인원을 출력하시오
하지만 one(parent)-to-many(children) 관계는 잘 처리하나 many-to-many는 처리하지 못한다.(거꾸로 출력하는 것이 어렵다.) -> 반대의 링크가 없어서 이를 관리하기 어렵다. 이는 계층 DBMS와 네트워크 DBMS의 가장 큰 차이점이다.
ex) 데이터 베이스 과목을 수강한 학생의 수를 출력하시오. -> 빠르다.
ex) 홍길동이라는 학생이 수강한 과목을 출력하시오. -> 매우 오래걸린다.
이를 개선하기 위해 네트워크 DBMS가 등장했다.
(2) 네트워크 DBMS
레코드들이 노드로, 레코드들 사이의 관계가 간선으로 표현되는 그래프를 기반으로 하는 네트워크 데이터 모델이다. 여기에서도 레코드들이 링크로 연결되어있기에 레코드 구조를 변경하기 어렵다.

포인터를 통해 명확하게 간선으로 표현할 수 있다. 이 때문에 변경하기 쉽지 않게 된다.
(3) 관계 DBMS
테이블을 통해 데이터를 표현한다.
\모델이 간단하고 이해하기 쉽고, 사용자는 원하는 것만 명시하고 어떻게 구현하는지에 대한 내용은 구체적으로 알 필요가 없다. 데이터가 어디에 있는지나 어떻게 접근하는지 등등에 대한 정보는 DBMS가 가지고 있다.
이전 DBMS와의 가장 큰 차이점은 이전 DBMS는 링크를 통해 연결 구조를 표현했지만 관계 DBMS는 링크를 사용하지 않고 관계를 표현할 수 있다. 관계를 나타낼 때는 '외래키(foreign key)'라는 것을 사용한다.
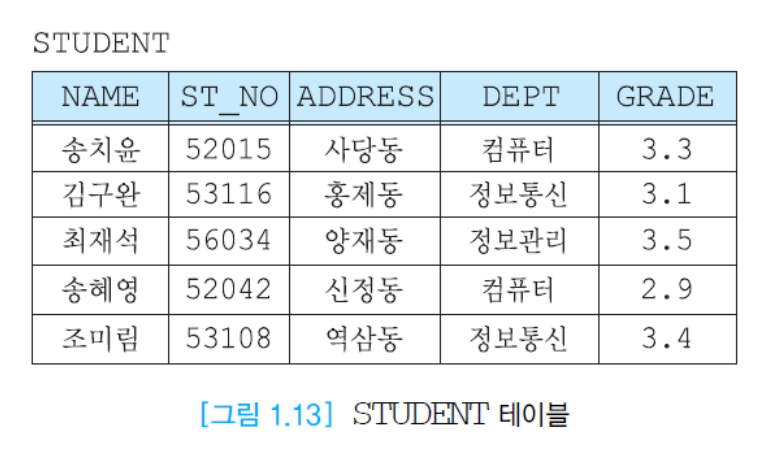
행과 열로 데이터를 표현할 수 있다.
(4) 객체 지향 DBMS
객체 지향 프로그래밍 패러다임을 기반으로 하는 데이터 모델이다. 객체지향 프로그래밍이 갖는 장점을 그대로 받아 데이터와 프로그램을 그룹화하고 복잡한 객체들을 이해하기 쉽고, 유지와 변경이 용이하다.
(5) 객체 관계 DBMS
관계 DBMS에 객체 지향 개념을 통합한 객체 관계 데이터 모델이 제안되었고, 이를 합하게 되었다.
4) 데이터 모델에 따른 프로그래밍 분량

점차 객체 관계 DBMS으로 갈수록 프로그램을 해야하는 분량이 줄어드는 것을 알 수 있다.
5) 현대 관계 DBMS의 기능

- 최근 자연어를 작성하면 이를 sql로 번역해 이에 대한 결과를 출력하는 연구가 진행 중이다.
- 트랜잭션: 데이터베이스를 실행하는 하나의 프로그램
- 긴필드: 바이트 수가 긴 데이터 값을 저장하는 필드
- 데이터 웨어하우스: 축적된 데이터를 분석을 위해 모아놓은 것으로 기본적으로 다루는 데이터의 양이 많아진다.
- OLAP(On-Line Analytical Processing)
- OLTP(On-Line Transactional Processing)
cf) 운영 데이터 베이스와 데이터 웨어 하우스
우리가 기본적으로 배우는 DBMS는 운영(운용) 데이터 베이스(operational database)로 조직을 운영하기 위한 데이터베이스이다. 이를테면 수강신청을하거나 전과를 하거나, 책을 빌리고 반납하는 용도의 데이터베이스를 의미한다. 시간이 오래지나다보면 책반납 기록, 수강신청 기록 등등의 데이터가 축적된다. 이러한 데이터를 분석하기 위해 모아놓는 장소를 데이터 웨어하우스라고 한다.
운영 데이터 베이스는 트랜잭션 데이터베이스(transactional database)라고 표현한다. 데이터 웨어하우스는 애널리티컬 데이터베이스(analytical database)라고 표현하기도 한다. 애널리티컬 데이터베이스는 많은 데이터를 동시에 엑세스하고 이를 홀드하는 과정이 필요하다. 트랜잭션 데이터베이스는 짧은 시간동안 데이터를 액세스하고, 적은 양의 데이터만 다룬다.
최근의 트랜드는 HTAP(hybrid transactional analytical processing) DB를 가지고 활용하는 경우가 많다. 일반적으로는 트랜잭션 데이터베이스에 저장된 데이터를 주기적으로 데이터 웨어하우스에 옮겨주는데 이 주기를 훨씬 줄여주기 위해 HTAP DB가 등장했다.
6) DBMS의 분류

- 사용자 수에 따른 분류는 동시에 사용할 수 있는 사용자의 수가 얼마나 되는지에 따라 분류한다. 따라서 단일 사용자 DBMS는 주로 PC용이 이에 해당한다.
- 접근 방법보단 목적에 따른 분류가 더 적절할 수 있다. 특별한 DBMS는 GIS가 예시가 될 수 있다.
cf) DBMS와 Database System
- DBMS는 소프트웨어를 의미한다.
- Database System은 데이터베이스와 DBMS, 애플리케이션 등등을 모두 합한 것을 의미한다. 조금 더 포괄적인 개념이라고 할 수 있다.
4. DBMS 언어
DBMS를 사용할 때 사용자가 사용할 수 있는 언어로 이는 기능별로 나눌 수 있다.
1) 데이터 정의어(DDL: Data Definition Language)
데이터 베이스 스키마를 정의하기 위해 사용하는 언어를 의미한다. 테이블을 생성하고, 어떤 어트리뷰트가 있고, 각 어트리뷰트는 어떤 속성을 가지고 있는지 정의한다. 이렇게 정의한 스키마에 대한 명세는 시스템 카탈로그 혹은 데이터 사전에 저장한다.

2) 데이터 조작어(DML: Data Manipulation Language)
레코드(튜플)을 삽입, 삭제, 변경하는 등등의 역할을 하는 것을 의미한다. sql 언어가 다른 언어와 차별화된 포인트는 비절차적 언어라는 점이다. 절차적 언어란 각 단계별로 어떤 작업을 할 지 명시하는 것이다. 비절차적인 언어는 구체적인 절차를 명시하지 않고, 원하는 데이터만 명시하는 것을 의미한다. 이는 선언적 언어라고 하기도 한다.
ex) 절차적 언어: 김철수를 찾기위해 테이블을 열고, 이름을 찾고, 이에 해당하는 데이터를 뽑아라
ex) 비절차적 언어: 김철수를 찾아라.
간단한 통계에 대한 내장함수가 존재해 데이터에 대한 통계 내용을 얻을 수 있다. 터미널에서 데이터 조작어를 입력해가며 실시간으로 인터렉션하며 사용할 수 있고, 언어를 미리 적어놓은 다음 이를 돌릴 수 있다.


3) 데이터 제어어(DCL: Data Control Language)
트랜잭션을 명시하고, 권한을 부여하거나 취소하는 등의 역할을 한다.
4) ANSI/SPARC 3 단계 모델의 각 단계에서 사용되는 데이터 정의어와 데이터 조작어

- 데이터베이스를 만들 때의 이런식으로 만들면 좋겠다는 샘플을 나타낸다.
- 응용프로그램에서 사용하는 것과 사용자가 사용하는 것으로 나눌 수 있다.
5. DBMS 사용자
DBMS를 사용하는 여러 부류의 사용자들이 존재한다. 이들은 모두 다른 사람이 아니어도 된다. 극단적인 경우에는 한 사람이 모든 역할을 할 수 있다. 커다란 조직일수록 본인이 맡은 역할의 일만 열심히 한다.

(1) 초보사용자
기작성 트랜잭션(canned transaction)을 사용해 데이터베이스와 인터렉션을 한다. 쉽게 사용할 수 있도록 만들어진 트랜잭션을 사용해 데이터베이스와 인터렉션을 하기에 운용프로그램 등등에 대한 이해가 없어도 사용할 수 있다.
ex) 수강신청자
(2) 캐주얼 사용자
데이터베이스의 터미널을 통해서 sql을 직접 입력해 답을 얻거나해서 사용하는 사용자이다. 필요하면 질의가 제대로 처리되는지 등을 알려주는 유틸리티 등을 사용할 수 있다.
(3) 응용 프로그래머
기작성 트랜잭션을 작성해주는 사람이다.
(4) 데이터베이스 설계자
데이터베이스 구조를 만드는 사람을 의미한다. 예를 들어 데이터베이스 설계자는 대학이라는 구조를 만들 때 학생 테이블, 교과목 테이블, 교감사 테이블 등이 있어야하고, 학생 테이블에는 어떤 어트리뷰트가 있어야하는 지 등등에 대한 스키마를 설계하는 사람이다. 이때 case 도구 등을 사용할 수 있다.
(5) 데이터베이스 관리자, DBA(Data Base administrator)
트랜잭션을 빠르게 처리하기 위해 튜닝을 하며 데이터베이스를 관리하는 사람
(6) 오퍼레이터
데이터베이스를 운영하기 위한 머신, 머신 내에 있는 소프트웨어 등등에 대한 운영환경을 책임지는 사람
6. ANSI/SPARC 아키텍처와 데이터 독립성
ANSI는 미국의 표준을 담당하는 기구이다. 예를 들어 ANSI C인 경우에는 C에 대해 만들어진 표준을 의미한다. 이와 같이 표준 기구에 대해 DBMS에 대한 구조를 참조용으로 발표한 것이 ANSI/SPARC 아키텍쳐이다. 상용 DBMS 구현에서 사용하는 일반적인 아키텍쳐는 이에 해당한다.
1) ANSI/SPARC 아키텍쳐의 단계

ANSI/SPARC 아키텍쳐는 3단계인 물리적, 개념적, 외부 단계로 이뤄진다. 또한 각 단계에서는 이웃한 단계와서의 매핑(사상)이 존재한다. 외부/개념 사상, 개념/내부사 사상이 존재하게 된다.
(1) 외부단계(external level)
각각의 사용자에게 보여지는 뷰를 담당하는 역할을 한다. 즉, 데이터베이스를 전부 보여주는 것이 아니라 각 사용자들에게 일부분의 필요한 데이터들만 보여줄 수 있다.
ex) 재무부서는 영업부서의 데이터를 알 필요가 없거나 혹은 보안상 알려지면 안되는 데이터가 있을 수 있다. 이때 외부 단계에서 이를 처리한다.

예시에서는 EMP_NAME, ASSIGNMENT가 이에 해당한다. 즉, 보여주고자 하는 어트리뷰트를 선택해 여러 테이블 속에서 데이터를 꺼내 보여줄 수 있다.
(2) 개념단계(conceptual level)
조직체 전체에 대한 스키마를 구현하는 단계를 의미한다. 이 단계에서는 어떤 데이터가 저장되어있고, 어떤 관계가 존재하는지, 어떤 무결성 제약조건들이 명시되어있는지 등을 기술한다.
위의 예시에서는 어떤 테이블이 있는지를 명시해놓는 것을 의미한다.
(3) 내부단계(internal level)
데이터베이스가 실질적으로 어떻게 저장되는지에 대해 표현하는 단계를 의미한다. 이 단계에서는 인덱스, 해싱 등과 같은 접근 경로, 데이터 압축 등을 기술한다. 개념 스키마에는 영향을 미치지 않으면서 성능을 향상시키기 위해 내부 스키마를 변경하는 것이 바람직하다. 개념 단계에서는 퍼블릭 인터페이스로 비유할 수 있고, 이를 빠르고 효율적으로 처리하기 위해 프라이빗 내부 함수를 구현하는 것이 내부단계로 비유할 수 있다. 성능향상을 위해 튜닝을 하는 등의 작업이 이 단계에서 이뤄진다.
위의 예시에서는 비순서 화일로 저장하거나 해싱 화일로 저장한다 등에 대해 정하고, 어떤 어트리뷰트 혹은 어떤 조합에 대해 인덱스를 만들 것인지에 대해 말하는 것이 내부 단계에 해당한다.
cf) 인덱스
인덱스가 존재하지 않는다면 데이터를 찾기 위해 순차적으로 검색해야한다. 인덱스 테이블을 만들어서 인덱스 키값을 입력하게 되면 주어진 데이터를 찾는데 바로 찾을 수 있다. 인덱스는 키와 포인터를 가지고 있다. 탐색 구조가 이에 해당한다. BST, Hashing 등등이 탐색 구조 중 하나이다. 인덱싱은 트리구조로 찾게 된다.
(4) 지하철 노선도를 통한 예시

지하철 노선도 전체는 개념 단계에 해당한다. 조직 전체에서 사용하는 구조를 의미한다. 하지만 지하철을 탑승하는 사람들은 본인들이 이용하는 노선만 관심을 가지기에 이에 대해서는 각각의 사용자별로 다른 뷰를 제공한다.
2) 스키마 간의 사상
(1) 외부/개념 사상
개념에 저장되어있지 않은 테이블에 대해서 어떻게 값을 뽑아낼 수 있는지에 대한 변환을 책임지는 단계로 외부단계의 뷰를 사용해서 입력된 사용자의 질의를 개념 단게의 스키마를 사용한 질의로 변환한다.
(2) 개념/내부 사상
다시 내부 단계의 스키마로 변환하여 디스크의 데이터베이스를 접근하는 단계를 의미한다. 예를 들어 데이터를 찾는 방식을 순차적으로 탐색할 것인지, 인덱스를 통해 찾을 건지 등등에 대해 설정할 수 있다.
3) 데이터의 독립성

상위 단계의 스키마 정의에 영향을 주지 않으며 하부 단계의 스키마 정의를 변경할 수 있음을 의미한다.
(1) 논리적인 데이터 독립성
외부/개념 사상에서 발생할 수 있는 데이터 독립성이다. 개념 스키마의 변화로부터 외부 스키마가 영향을 받지 않음을 의미한다. 만일 개념 스키마에서 테이블의 이름을 바꿔주더라도 내부적으로 이름만 바꿔주면 되기에 응용프로그램에서는 영향을 받지 않기에 외부단계에는 영향을 받지 않는다.
만약 저장된 데이터타입을 바꾼다면 외부에 영향을 줄 수 있고, 이러한 경우에는 독립성이 없을 수 있다.
(2) 물리적인 데이터 독립성
개념/내부 사상에서 발생할 수 있는 데이터 독립성이다. 물리적으로 저장하는 방식에 대해 독립성을 보장하는 것이기에 물리적인 데이터 독립성이라 말한다. 예를 들어 내부 스키마에서 인덱스를 지정했다가 삭제한다하더라도 개념 스키마나 외부 스키마에 있는 내용을 바꾸지 않더라도 이를 구현할 수 있다. 개념 스키마에도 영향을 미치지 않기에 외부 스키마에 있는 내용에도 영향을 미치지 않는다.
7. 데이터베이스 시스템 아키텍처
1) 데이터베이스 시스템 아키텍처

- 런타임 데이터베이스 관리기는 실질적으로 질의를 동작시키는 역할을 한다.
- 트랜잭션 관리는 동시성 제어(Concurrency Control)나 회복 등등의 역할을 한다.
- 시스템 카탈로그는 테이블에 들어가는 정보를 테이블 형태로 관리한다. 따라서 데이터의 수정이 발생한다면 데이터베이스 관리기는 데이터베이스와 시스템 관리기에도 데이터가 들어간다.
(1) 데이터베이스 API

ODBC는 마이크로 소프트사가 주도적으로 개발한 데이터베이스 API로서 데이터베이스에 접근하기 위해 표준을 제공해주는 역할을 해서 ODBC만 안다면 각각의 API를 알 필요가 없다. ODBC를 지원하는 DBMS 간에는 서로 상대방의 데이터베이스를 접근할 수 있다. 데이터베이스뿐만이 아니라 엑셀에도 질의를 할 수 있다.
cf) JDBC(Java ...)
자바 프로그래밍 언어를 사용해서 데이터베이스에 접근하기 위해서는 JDBC를 사용할 수 있다. 프로그램을 깔 때 디폴트로 깔리는 것이 아니라 데이터베이스를 설치할 때 JDBC를 드라이버 형태로 추가로 설치를 해야지 자바에서 사용할 수 있도록 인터페이스를 제공해줄 수 있다.
2) 데이터베이스 시스템의 형태
(1) 중앙 집중식 데이터베이스 시스템

하나의 머신에서 데이터베이스를 저장할 때 이에 해당한다. 여러 클라이언트들이 여기에 접속해서 사용할 수 있다. 이러한 형태는 가장 널리 사용되는 형태이다.
(2) 분산 데이터베이스 시스템

네트워크로 연결된 여러 사이트에 데이터베이스 자체가 분산되어있으며, 데이터베이스 시스템도 여러 컴퓨터 시스템에서 운영된다. 위의 그림에서 색칠된 부분은 분산 데이터베이스 시스템이고, 외부의 컴퓨터는 클라이언트가 된다. 예를 들어 프랜차이즈 마트가 있을 때 각각의 데이터베이스는 각 지점에서 판매되는 재고를 저장하는 데이터가 될 수 있다. 사용자는 각 지점에 데이터베이스에 직접 엑세스하는 것이 아니라 하나의 분산 데이터베이스 시스템에 엑세스해서 데이터를 전달받을 수 있다.
3) 클라이언트 서버 데이터베이스 시스템
초기 데이터베이스는 PC가격이 비쌌기에 더미 터미널을 통해 입력을 하고 중앙 서버에서 내용을 처리하는 식으로 이뤄졌다. 더미 터미널은 디스플레이하는 기능밖에 없고, 프로세싱을 할 수 없는 터미널을 의미한다. 모니터와 키보드만 존재해 중앙 서버에 연결이 되어있어서, 서버에서 내용을 처리한뒤, 화면에 출력을 해주는 과정으로 이를 처리한다.
(1) 2층 모델(2-tier model)

클라이언트를 통해 데이터베이스 서버에 접근하는 식으로 되어서, 데이터베이스 시스템의 기능이 서버와 클라이언트에 분산되었다. 서버는 데이터베이스를 저장하고, DBMS를 운영하며 여러 클라이언트에서 온 질의를 최적화하고, 권한 검사를 수행하고, 동시성 제어와 회복 기능을 수행하며, 데이터베이스의 무결성을 유지하고 데이터베이스 접근을 관리한다. 클라이언트는 문자로서 질의를 보내는 것이 아니라 사용자 인터페이스 등을 통해 데이터베이스에 접근할 수 있게된다. 이는 2층 모델이라 한다.
(2) 3층 모델(3-tier model)

클라이언트와 데이터베이스 서버 사이에 응용 서버가 추가된다. 응용의 논리는 비즈니스 로직을 의미한다. 서비스를 제공하기 위해 필요한 로직을 의미한다. 2층 모델에서는 클라이언트와 서버가 모두 이를 관리했지만 3층 모델에서는 응용 서버에서 이를 담당한다. 역할을 분리하여 각 단계에 대해 초점을 맞추는 부분을 나누는 것을 의미한다. 2층 모델에 비해 클라이언트 측에서 해야할 일의 크기가 작아질 수 있고, 응용 서버를 사용하기에 데이터 처리는 응용 서버에서 이뤄지고, 통신의 오버헤드가 줄어들 수 있다.
'강의 내용 정리 > 데이터베이스' 카테고리의 다른 글
| 데이터 베이스(6), DML, 트리거와 주장 (0) | 2022.10.21 |
|---|---|
| 데이터베이스(5), SELECT문 (0) | 2022.10.21 |
| 데이터 베이스(4), SQL 개요 및 데이터 무결성 (0) | 2022.10.21 |
| 데이터 베이스(3), 관계 대수와 SQL (0) | 2022.10.19 |
| 데이터베이스(2), 관계 데이터 모델과 제약조건 (0) | 2022.10.15 |