2022. 12. 18. 23:33ㆍ강의 내용 정리/운영체제
Virtual memory
피지컬 메모리가 무한대인 것처럼 지원하기 위해 세컨더리 스토리지를 사용해서 피지컬 메모리에서 잘 안쓰이는 것은 세컨더리 스토리지에 저장해서 필요할 때 가져온다.

Demand paging

Paging을 요구할 때 Paging을 한다.
페이지가 세컨더리 메모리에 있다가 피지컬 메모리에 왔다갔다하는 것을 swapping이라 한다.
페이지 단위의 swapping이 demand paging이 된다.
Swapping은 전체 프로세스를 세컨더리 스토리지에 올리고, 내리는 것을 의미하기도 한다. 여기서의 swapping은 page 단위로 하는 것을 의미한다.
TLB라는 캐시가 높은 성능을 보장하는 것은 로컬리티의 특징 때문이다. 디맨드 페이징 또한 로컬리티의 특징을 가지기에 이는 좋은 성능을 보장한다. 파일 시스템을 얘기할 때 버퍼 캐시를 또 다시 얘기가 나오는데 이 또한 로컬리티 때문에 좋아진다.
Locality in a memory reference pattern

Temporal locality: 지금 참조하는 영억이 또 다시 참조될 가능성이 높다. X축
Spatal locality: 하나가 참조되면 그 부근에 있는 것이 참조될 가능성이 높다. Y축
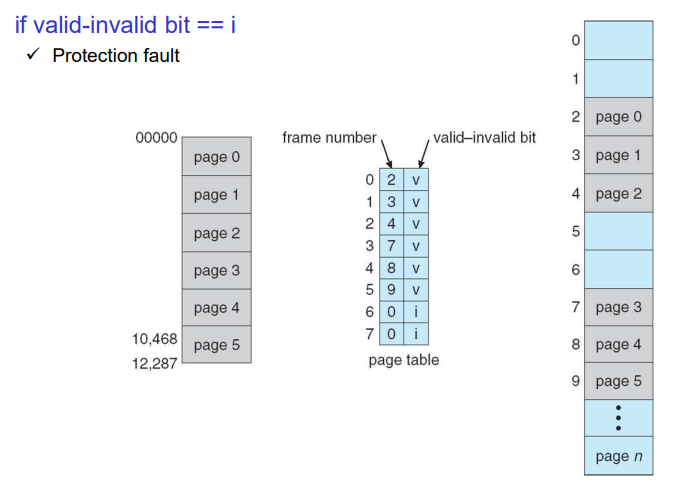
valid, invalid를 통해 protection fault를 했는데, 이를 다른 용도로 사용할 수 있다. valid이면 참조가능하고, 피지컬 메모리에 있다는 것을 의미한다. invalid면 protection fault이거나 피지컬 메모리에 없는 경우(page fault)를 의미하며, 세컨더리 메모리에 있다는 것을 의미하게 된다.
초기에는 메모리를 하나도 올리지 않고 시작하고, 페이지를 참조한 시점에 이를 올린다. 따라서 이는 디맨드 페이징이라 한다.


invalid bit의 의미
참조할 수 없는 영역인 경우 protection fault라고 부른다.
참조할 수 있는 영역인데 메모리에 없고, 세컨더리 메모리에 있는 경우 page fault라고 부른다.
page table에 세개는 있지만 나머지는 세컨더리 메모리에 있다. 0, 2, 5번이 참조되어서 이는 page table에 올라와있는 상태이다. 또한 로컬리티가 우수한 페이지는 0, 2, 5번 페이지가 된다.
초기에 모두 invalid인데, 이후에 참조된 0, 2, 5번 페이지는 참조되었기에 page table에 올라온다. 이러한 경우에는 디맨드 페이징을 의미한다. 또한 이는 locality를 설명하는 그림일 수 있는데 이러한 경우에는 자주 참조되는 페이지가 0, 2, 5인 경우에 page table에 올라온 것을 의미하기도 한다.
위에서 페이지 폴트가 발생하는 경우에는 invalid인 페이지를 참조하는 것을 의미한다. cpu가 명령어를 실행하는 시점에 (load, store) 버추어 어드레스를 피지컬 어드레스로 변환한다. invalid 비트를 마주친다면 자기자신에게 fault를 걸게 된다. 따라서 이는 page fault가 된다.
Page fault

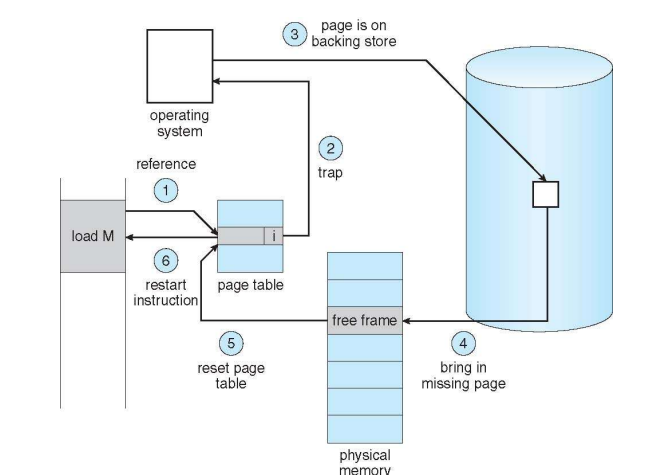
invalid이다. 참조할 수 없는 메모리이거나 세컨더리 메모리에 있는 경우가 이에 해당된다. 이러한 경우에는 fault가 걸리게 된다. 교재에서는 trap으로 표현된다. 이에 따라 운영체제가 동작하고, 이는 세컨더리 스토리지를 봐야하는지, 참조할 수 없는 메모리를 참조한지 확인한다. 세컨더리에 있는 것은 backing store에 있는 것을 의미한다. 이후 free frame에 이를 넣는다. 그 이후 명령어를 재시작한다.
디맨드 페이징은 초기 시점에 모두 invalid이고 backing store에 있는 것을 올리는 작업을 한다. 이를 page fault라고 한다.
Memory Reference
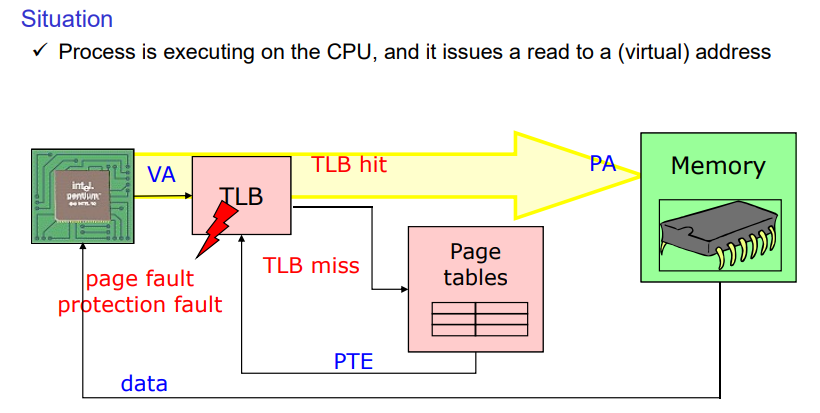
cpu 명령어를 실행할 때 메모리를 참조하는 명령어라면 버추어 어드레스를 피지컬 어드레스로 변환해야한다.
1. virtual address -> physical address를 변환할 때 tlb를 확인하고 hit가 되어 바로 변환한다. (99%)

2. tlb miss가 난다. -> 이후에는 페이지 테이블을 참조한다. 이때 cpu의 mmu가 주체가 되어서 이를 참조한다. 이는 하드웨어적으로 이뤄진다. 이후 valid가 된다. 그러면 변환이 되어서 참조한다.

mmu가 처리하거나 os가 처리한다. os가 처리하는 경우에는 느려서 잘 사용하지 않는다.
3. tlb 미스가 났는데 page table이 invalid이다. 이는 page fault, protection fault이기에 cpu가 fault를 건다.

위의 경우에는 protection fault가 발생한 것을 의미한다. 아주 흔하게 발생하는 에러이다. 이후 운영체제는 해당 프로세스를 종료시킨다.

이는 page fault가 발생한다.
Copy on Write
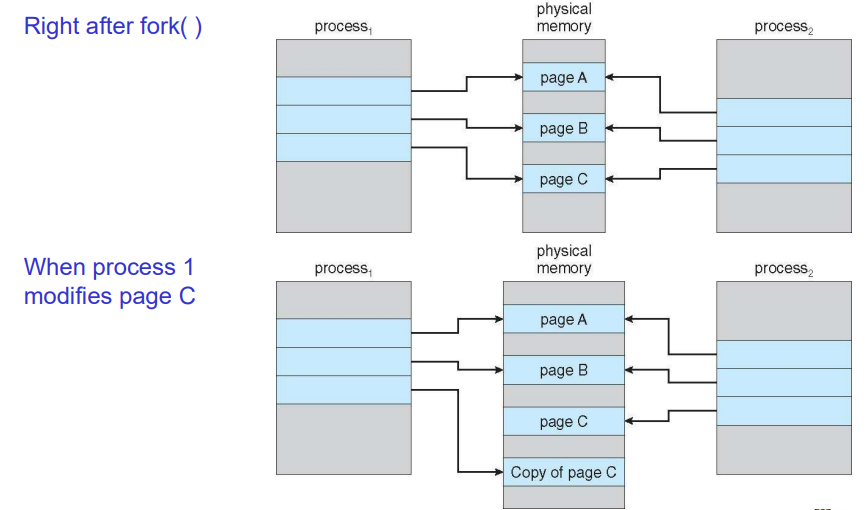
디맨드 페이징과 관련이 있는 내용이다.
이 방법을 통해 디맨드 페이징이 구현된다.
invalid로 우선 처리한다. 이후 page fault가 발생한 뒤, free frame에 이를 처리한다.
fork 시스템 콜이 발생한다면 동일한 프로세스를 만들게 된다. 이때 카피를 하게 되는데 write를 할 때 copy를 하게 된다. 하지만 개념적으로 맞지만 모든 단위를 한번에 copy하면 성능상의 문제가 발생할 수 있다. 따라서 처음에는 동일한 메모리 주소를 가리키고 있다가 이후 page 단위로 write를 할 때면 한 시점에 이를 카피해서 다른 곳을 가리키게끔한다. 이를 통해 성능을 높일 수 있었다.
Page replacement
no free frame인 경우
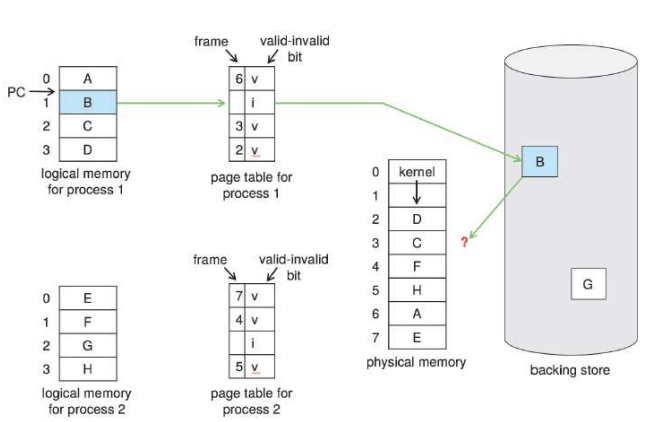
한 페이지가 참조되었는데, invalid라면 page fault가 발생한다. 이후 이를 램에 올려서 처리한다. 하지만 free frame이 없는 경우에는 메인 메모리의 모든 메모리가 사용된다는 것을 의미한다. 하지만 page fault를 처리하기 위해서 피지컬 메모리에 있는 것을 하나 내려야한다. 그 이후에 새롭게 처리한 것을 넣어야한다. 페이지가 교체된 것을 page replacement라고 한다. 이때 어떤 것을 내릴 것인지 정해야한다. 이는 page replacement algorithm이라 한다.
오래 사용되지 않은 것을 내리면 좋을 수 있다. 왜냐하면 최근에 사용되지 않은 것을 내리는 경우에는 앞으로도 사용되지 않을 가능성이 높다는 로컬리티의 특징 때문이다.

로컬리티를 사용해서 알고리즘을 선정해야한다.

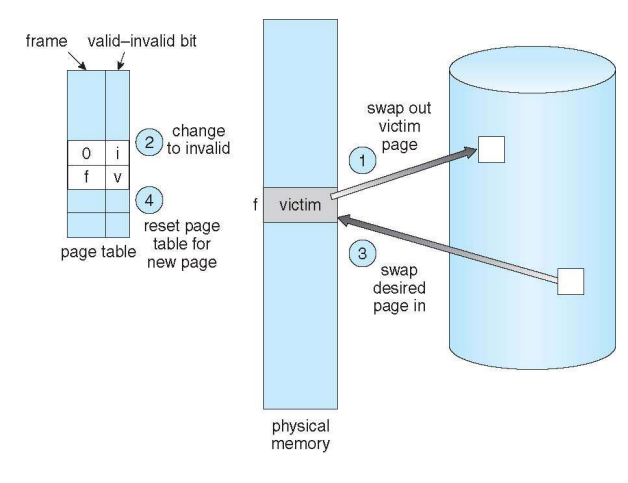
victim을 내려서 새로운 page를 올려야한다. 이를 page replacement가 된다.

계산 식
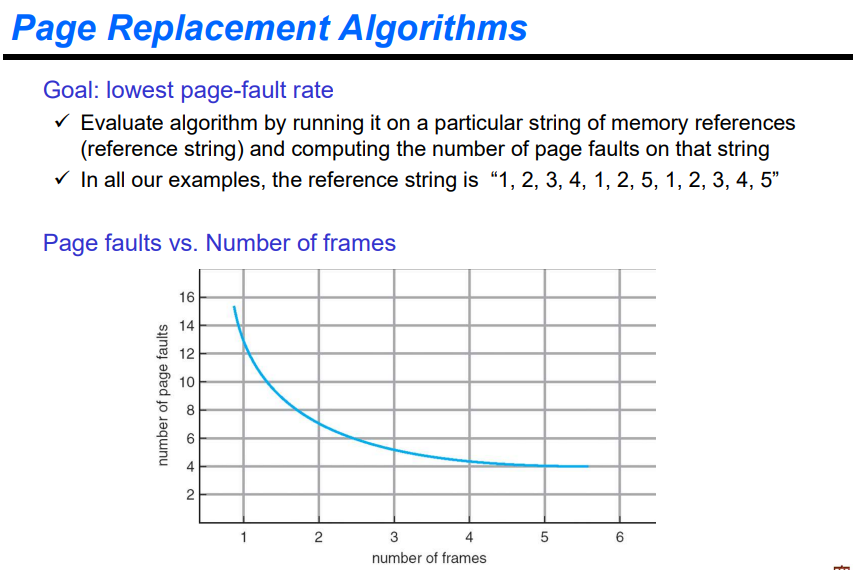
page fault에 따른 replace를 줄이는 것이 가장 큰 목표가 된다. free frame 수가 많으면 page fault가 줄어든다,.
알고리즘
FIFO

가장 fair하다. 하지만 로컬리티의 특징을 이용하지 못하기에 성능이 좋지는 않다. 실제 데이터를 가지고 분석하더라도 별로 좋지 않게 된다.
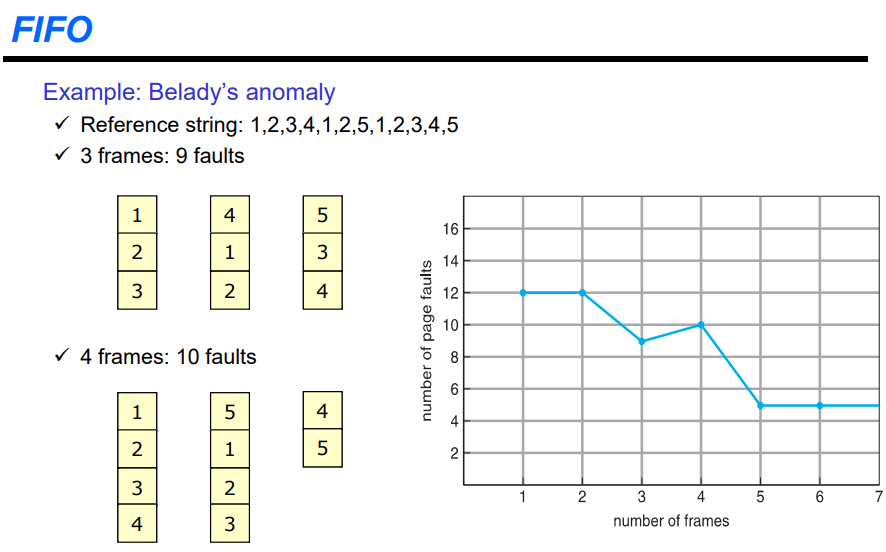
위와같이 페이지를 참조한다고 가정한다.(1,2,3,4,1,2,5,1,2,3,4,5)
메모리가 4기가 바이트인 경우에는 프레임의 크기가 4kb라고 한다면 1메가 개만큼 있게 된다. 프로세스의 개수가 만개라면 프로세스 하나 당 프레임을 100개씩 둘 수 있다.
하지만 위의 가정은 프로세스가 프레임을 세개 할당 받은 것을 가정한 것이다. 가장 처음에는 메인메모리에 하나도 안올라 있다. 이에 따라 1, 2, 3을 참조할 때 모두 page fault가 발생한다. 이후 4를 참조하면 FIFO이기에 1번 자리에 4를 넣게 된다. 이후 1, 2를 모두 참조하게 된다. 매번 page fault가 발생하게된다. 이후 5도 page fault가 발생하는데 1, 2는 page fault가 발생하지 않는다. 이에 따라 page fault가 총 9번 발생한다.
프레임이 4개일 때도 위와 동일하게 처리할 수 있다. 이러한 경우에는 frame을 하나 더 주었는데 fault가 10번 발생하게 된다. 이는 fifo가 적합하지 않은 알고리즘이기도 하고, 이러한 상황을 Belady's anomaly라고 한다.
Belady's anomaly
페이지가 늘어나면 fault가 줄어야하지만 늘어나 것을 의미한다.
Optimal algorithm
동일한 성능을 가지는 알고리즘은 있을 수 있지만 더 좋은 알고리즘은 없다.
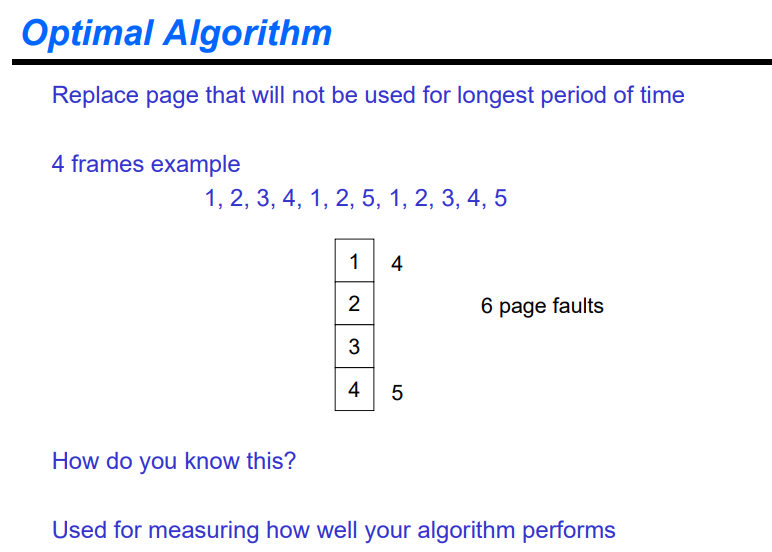
5번이 있는 경우에는 제일 늦게 참조되는 4에 올려서 이를 참조하게 된다.
하지만 위와 같이 구성을 하기 위해서는 뒤에 어떤 순서로 데이터를 참조할 수 있는지 알아야지 이를 구성할 수 있다. 따라서 이는 확실하게 구현할 수 없다. 따라서 이는 과거의 데이터를 가지고 예측해야하는데, 로컬리티의 특징을 가지고 활용하면 아래와 같은 알고리즘을 만들 수 있다.

가장 오래전에 사용된 것을 찾게 된다.
로컬리티의 특징 덕분에 생각해낸 알고리즘이다. 이는 실제로 optimal에 근접한 성능을 보인다.
따라서 5를 처음 참조할 때 오래동안 사용되지 않은 3번 자리에 5번을 넣는다.
8번 page fault가 발생했다. 이는 optimal에 근사하는 성능을 보인다.
LRU 알고리즘의 구현

한 시점에서 어떤 것을 참조했는지 알아야한다. 이를 위해 페이지 별로 어느 시점에 어떤 것을 참조했는지 알아야한다. 이를 구현할 때 두 가지 방법을 사용할 수 있다.
timestamp(현재 시간을 기록하는 자료를 의미한다.)
페이지별로 time stamp를 기록해서 제일 예전에 참조된 것을 내린다. 하지만 메모리 공간 상의 부담이 크게 된다.
stack 구현
참조됐을 때 새롭게 참조되면 최근에 참조된 순서로 이를 바꾼다. 하지만 새롭게 참조될 때마다 이를 바꾸면 오버헤드가 커서 이를 사용하기 어렵다.
Approximation
timestamp의 오버헤드가 크기 때문에 이를 근사해서 사용한다. 제일 많이 줄이면 한비트까지 줄일 수 있다. 이를 reference bit로 표현한다.

1이면 최근에 참조된 적이 있고, 0이면 최근에 참조된 적이 없는 것을 의미한다. 주기적으로 레퍼런스 비트를 0으로 클리어하고, 참조될 때 1로 바꾸는 방식으로 처리할 수 있다. 이후 page replacement를 할 때 0인 것을 내리게 된다.
second chance (LRU clock)
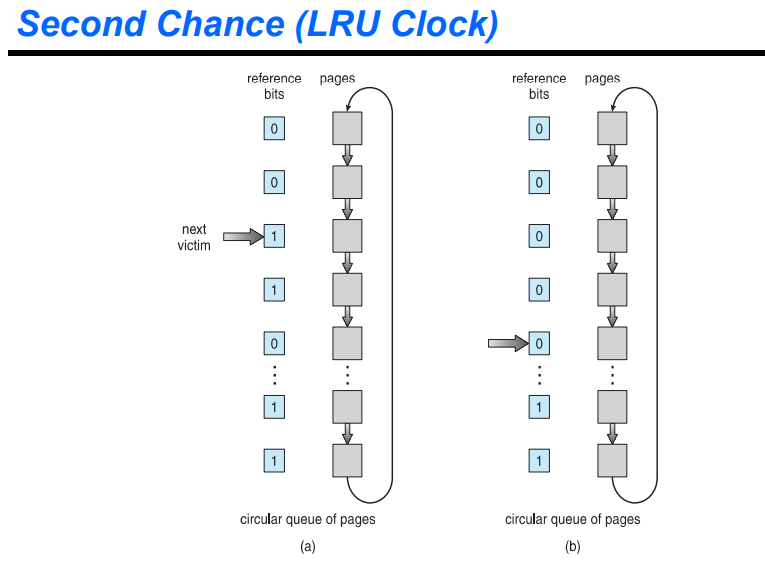
서큘러 큐 형태로 포인터를 움직이는데, next bit가 1이면 반복적으로 1을 0으로 만든다. 이후 0이 나온다면 이를 내리고 replacement를 한다.
현재 우리가 사용하는 방법은 아래와 같이 1비트를 더 주게 된다.
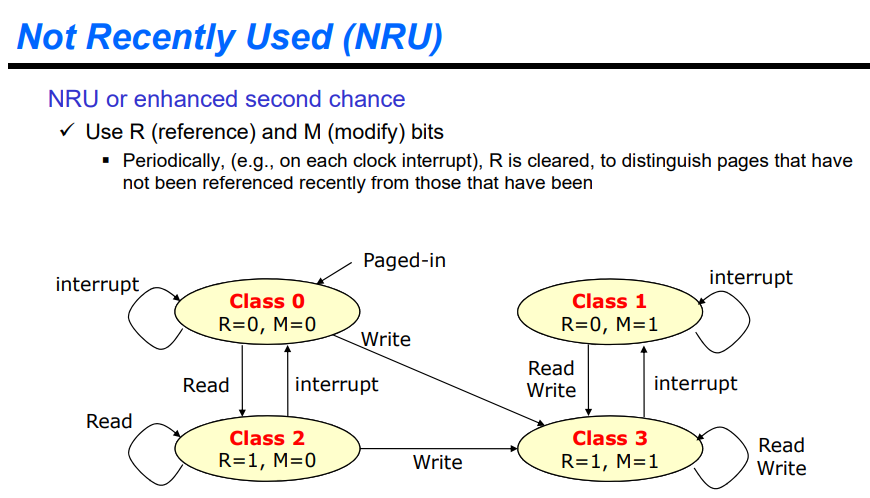
M: Write가 되어서 내용이 바뀐 것을 의미한다. 캐시에서 액세스가 된 뒤, 이후 쫒겨난다면 read라면 바로 버리면 되지만 write를 한 경우에는 메인 메모리에 반영해야하기에 M와 R 2비트를 이용해서 page replacement 알고리즘을 사용한다. 따라서 이를 고려해서 처리할 수 있다.
Reference는 됐지만 Modify가 되지 않은 경우와 반대인 경우를 고려해보자. R을 한번 이상 하면 반복적으로 할 가능성이 높기에 R이 안됐지만 M이 된 경우를 먼저 내린다. 즉, 위의 class 0 ~ 3 순서로 victim으로 선정한다.
타임스탬프를 모두 처리할 수 없으니 위의 두 비트를 가지고 처리하는 방법이 NRU가 된다. 이는 현재 CPU가 사용하는 방법이 된다.

캐시 메모리, tlb까지 해당 PTE가 올라가게 된다.

이전까지는 시간 기준으로 얘기했지만 이는 횟수를 기준으로 체크한다.
참조된 횟수에 기반한 방법을 LFU라고 한다. LFU나 LRU는 모두 비슷하게 optimal에 근접하게 된다. 하지만 이 또한 카운터를 관리해야한다. 따라서 오버헤드가 크게 된다. 그래서 이 또한 한비트로 줄일 수 있게 된다. 실제로 approximation을 하면 LRU와 비슷한 성능을 보이게 된다.
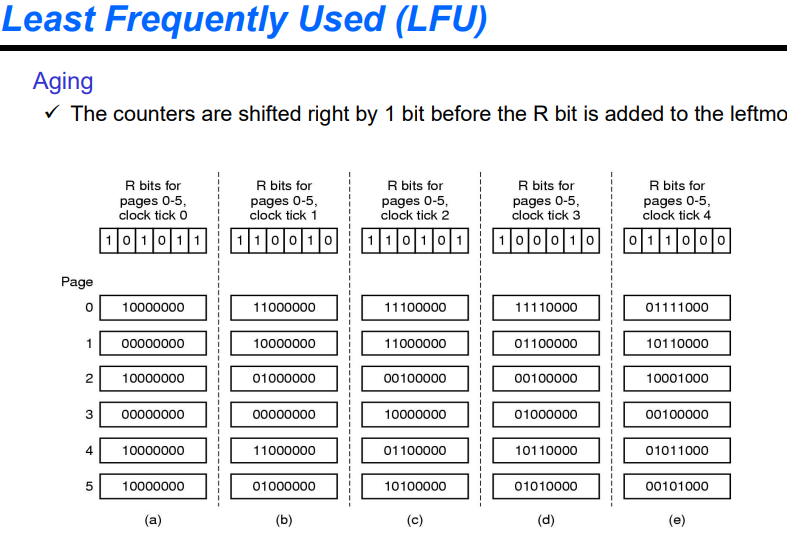
6비트로 이를 관리할 수 있다. 하지만 오버헤드가 크기에 한비트를 가지고 처리해야한다.
이는 LRU와 같이 서큘러 큐를 돌리는 것은 아니고, 클래스 내에서 랜덤하게 victim을 선정한다.
요약 LRU나 LFU가 optimal하지만 오버헤드를 고려해서 NRU를 사용한다.
Allocation of Frames

프로세스에 allocation하는 것이다. 사용하지 않는 free frame을 얼만큼 할당할 것인지를 정한다. 동일하게 처리할 것인지 프로세스의 크기나 우선순위에 따라 frame을 할당하게 된다.
프레임을 할당하는 초기에는 proportional allocation이 제일 합리적이다. 이후 프로세스가 수행되며 메모리가 필요한 정도를 page fault를 보고 판단한 뒤, 프로세스에 할당하는 프레임의 개수를 다이나믹하게 조정할 수 있게 된다.
프로세스에 비어있는 프레임을 얼마나 할당할 것인지가 여기서 고려되는 얘기이다.
page replacement를 할 때 해당 프로세스 내에서 replacement를 할지, 전체 프레임에 대해 replacement를 할지를 정해야한다. 하지만 지금 os에서는 local replacement로 page replacement를 한다.
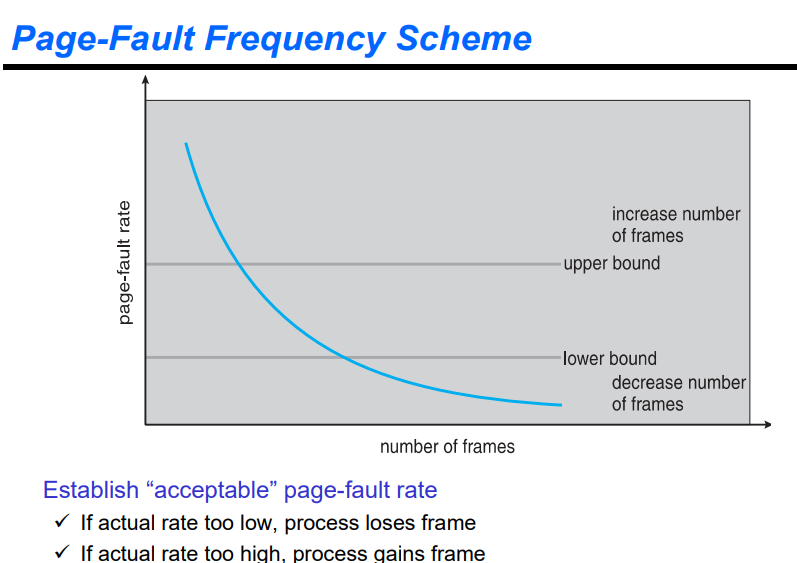
초기에 allocation을 한 뒤, 프로세스의 크기를 고려해서 프레임을 할당했다. 이후 lower bound보다 작은 페이지 폴트가 발생하면 프레임을 조금 덜 할당해줄 수 있다. 반대로 upper bound보다 크면 frame을 조금 더 할당한다.
이러한 방법을 운영체제에서 사용한다. 메모리의 여유가 있다면 페이지 폴트가 발생하지 않는다면 그냥 사용해도 된다.
Thrashing
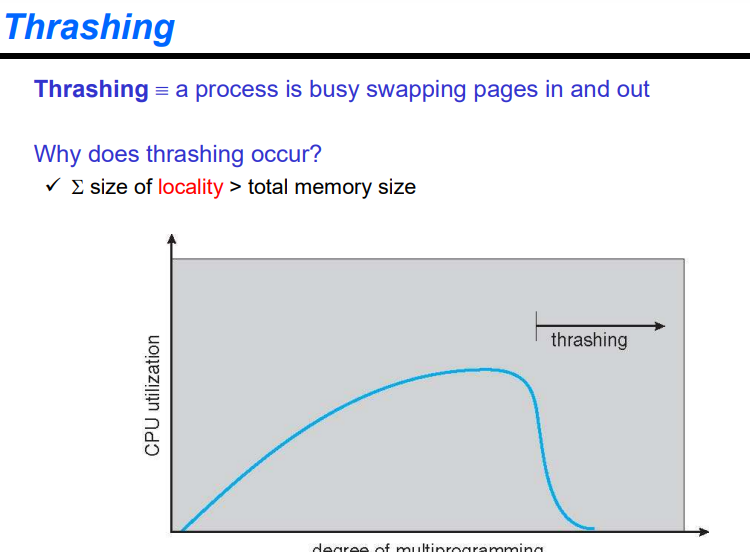
프로세스가 page in, page out하느라 해야할 일을 하지 못하고 swapping만 한다. page fault가 많이 발생할 때 이러한 현상이 발생한다.
프로세스의 수가 많아지면 cpu 사용률이 늘어나다가 어느 순간 메모리 크기에 비해 프로세스가 너무 많아져서 사용률이 확 떨어져서 i/o 작업만 하게 된다. (size of locality > total memory size)
이를 해결하기 위해 메모리를 더 달아야한다. 혹은 프로세스의 수를 줄여야한다.
디도스: 동시에 어느 서버에 접속하면 프로세스가 너무 많이 생겨서 thrashing이 발생해서 서버가 다운되는 것처럼 보인다.
working-set model

프로세스가 자주 사용하는 페이지의 크기를 working set이라 부른다. 델타 시간동안 참조된 페이지의 크기가 된다.
워킹 셋의 크기가 작으면 프로세스의 로컬리티가 우수한 것이고, 크다면 로컬리티가 우수하진 않다.
프로세스가 델타 시간 동안 사용한 페이지의 집합을 working set이라 한다. 모든 프로세스의 워킹 셋 사이즈의 합이 토탈 디맨드 프레임이 된다. 이는 피지컬 메모리보다 크면 쓰레싱이 발생한다.

prepaging
미리 페이징을 하는 것
0번이 페이지가 폴트나면 인접한 페이지도 참조될 가능성이 높기에(spatial locality) 이를 미리 페이징한다.
Page size selection
인터널 프레그멘테이션 차원에서는 페이지 사이즈가 크면 인터널 프레그맨테이션이 커진다. 따라서 페이지 사이즈가 작은 것이 좋다.
페이지의 크기가 커지면 페이지 테이블 사이즈는 작아지게 된다. 따라서 페이지 테이블 사이즈 측면에서는 페이지 사이즈가 크면 좋다.
페이지 사이즈가 크면 I/O 오버헤드가 줄어들게 된다.
페이지 사이즈가 작으면 로컬리티가 작아진다.
-> 페이지 사이즈가 크면 인터널 프레그멘테이션을 제외하고 나머지 측면에서는 모두 좋다. 이런 측면에서 페이지 사이즈는 현재 4kb이지만 멀티플로 구성하기도 한다.
TLB Reach
TLB가 커버하는 메모리 영역으로 TLB size 와 page size를 곱한 것이 된다. 페이지 사이즈가 크면 클수록 좋다.

프로그램 1과 2는 페이지 폴트의 발생 빈도가 다르게 된다. C, C++을 가정하여 이를 고려한다.
프로그램2
A[0][0]
A[0][1]
A[0][2]
...
A[0][1023]
A[1][0]
...
매 순간마다 페이지 폴트가 발생한다. 페이지 테이블을 매번 초기화해야하기에 그러하다.
A[0][0] -> A[1][0] -> A[2][0] 순서로 매번 페이지 폴트가 발생하기 때문이다.
cf) 맷랩은 a[0][0], a[1][0] 순서로 처리한다.
프로그램2
순차적으로 이를 처리하기에 페이지 폴트가 1024만 발생한다.
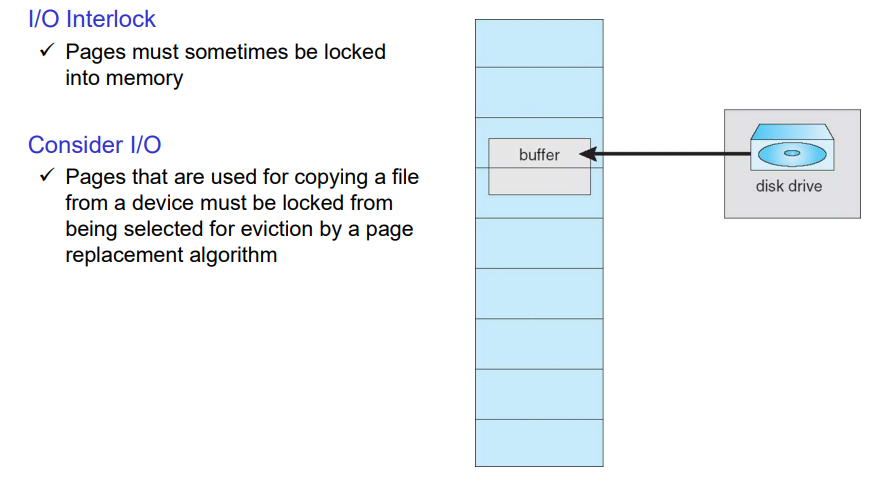
피지컬 메모리가 있고, 디스크 드라이브를 읽어서 메모리에 넣을 때 cpu가 메인메모리를 자주 쓴다. I/O장치가 컴퓨터 메모리에 직접 데이터를 쓰는 것은 DMA(direct memory access)라고 한다.
DMA를 할 때에는 버추어 메모리 관리를 고려하지 않는다. DMA를 사용하는 피지컬 영역은 락을 걸어서 I/O만 사용하도록 하고, 이를 다른 프로세스가 사용하지 않도록 해야한다. 따라서 연속적인 메모리 공간을 피지컬 메모리에서 사용해야한다.
'강의 내용 정리 > 운영체제' 카테고리의 다른 글
| 운영체제(12), I/O Systems (1) | 2022.12.19 |
|---|---|
| 운영체제(11), Mass-Storage Structure (0) | 2022.12.18 |
| 운영체체(9), Main Memory (0) | 2022.12.18 |
| 운영체제(8), Deadlocks (1) | 2022.12.18 |
| 운영체제(7), Synchronization Examples (1) | 2022.12.18 |