2022. 12. 18. 23:47ㆍ강의 내용 정리/운영체제
Mass-Storage Structure
I/O 장치 관리
제일 중요한 I/O 장치는 세컨더리 스토리지이다. 이게 있어야지 저장하고 관리할 수 있다.
세컨더리 스토리지
HDD
오른쪽 위에 있는 것이 디스크, 디스크 arm과 헤드가 존재해 원하는 위치로 이동해서 데이터를 읽는다.
SSD
오른쪽 아래에 있는 것은 SSD이다.
ARM CPU가 있어서 플래시 메모리를 읽는다.
RAM disk
운영체제의 파일시스템이 존재하는데 HDD나 SSD에 이를 저장한다. 하지만 어떤 경우에는 Ram disk가 존재해서 이 곳에 저장을 하기도 한다. 이를 사용하면 전원을 껐다가 켜면 메모리가 초기화된다. IP time은 리눅스 파일시스템의 원본을 압축해서 플래시 메모리에 가지고 있다가 전원을 켜면 메인 메모리에 램 디스크를 만들고, 플래시 메모리에 압축되어서 저장된 것을 램 디스크에 카피하고 램 디스크에서 동작한다. 여기서 꺼지고 켜지면 이를 다시 지운다.
Magnetic tape
아래에 있는 것은 마그네틱 테이프이다.
백업용도로 주로 사용된다.
Disk Attachment
컴퓨터와 연결되는 방법
Host attached
I/O 포트를 사용해서 연결한다. PC에서 사용하는 방식이다.
Network attached
네트워크로 연결해서 사용한다. NAS와 같은 연구실에서 사용하는 장비는 네트워크로 연결해서 사용한다.
NAS(Network Attached Storage)
IP 네트워크를 통해서 연결하고 클라이언트가 우리가 사용하는 PC라고 생각하면 된다. 여러 사용자가 공유 데이터를 사용할 수 있게끔 지원하는 방식이다. 그룹별로 공동의 작업을 할 때 이를 많이 사용한다.
SAN(Storage Area Network)
사진에서 달려있는 것들이 모두 디스크이다.
데이터 센터의 서버라고 생각하면 된다. 디스크는 네트워크로 연결되어있다. Network attached 방식이다.
NAS와 SAN의 가장 큰 차이는 NAS는 파일 단위로 액세스를 한다. 반면 SAN은 블럭 단위로 액세스를 진행한다. 즉, 그림의 전체를 하나의 커다란 디스크로 고려하고, 컴퓨터들이 디스크 블럭 단위로 이를 액세스한다. 큰 대용량의 데이터를 블럭 단위로 액세스한다.
Fibre channel이라고 하는 별도의 연결을 통해 SAN과 컴퓨터가 연결된다.
Storage Architecture
블럭 단위, 파일 단위로 액세스하냐 / IP 네트워크냐 Non IP 네트워크냐로 구분할 수 있다.
IDE, SCSI는 host attached 방식이다. SAN은 Fibre channel이라는 별도의 네트워크를 통해 연결하는데 블럭 단위로 이를 액세스한다.
여기에 NAS까지만 자주 사용하는 방식이다.
HDD
하나의 판을 platter, 판의 윗면/뒷면을 surface, 서피스 내의 동심원을 트랙이라 부르고, 트랙 내의 작은 단위를 섹터라고 부르고, 이는 스핀들에 의해 계속 돌게 된다. 이때 arm 어셈블리가 읽을 트랙으로 이동해서 트랙이 헤드에 돌아오게 된다. 이후 정보를 읽는 것이 transfer가 된다.
디스크의 성능은 seek, rotation, transfer에 따라 결정된다. Seek의 오버헤드가 가장 크다. 따라서 seek time을 줄이기 위해 노력해야한다. 디스크 read, write에 대해 성능을 높이기 위해서 Disk Scheduling을 할 수 있다. 운영체제가 사용하는 디스크 스케줄링 알고리즘을 앞으로 살펴볼 것이다.
연속적인 데이터를 저장할 때 헤더를 움직이지 않고 저장하는 것이 가장 효율적이다. 이에 따라 성능을 개선하기 위해선 동심원의 트랙의 집합이 중요해지고, 이를 실린더라고 한다. 따라서 실린더는 중요한 개념이다.
요즘 디스크는 디스크 블럭 단위로 데이터를 read write한다. 요즘은 블럭 단위로 인터페이스를 하기에 효율이 좋고 빨라진다.
FCFS
fair하다.
요청이 들어왔을 때 이를 요청이 들어온대로 처리한다. 위쪽의 번호는 실린더 넘버이다. seek를 고려하지 않았기에 성능은 낮다.
SSTF
헤드의 위치에서 가장 가까운 실린더부터 먼저 처리한다. 이때 성능이 가장 좋아진다. 일종의 SJF와 유사한 형태이다. 디스크의 경우에는 얼마의 시간이 걸릴지 미리 알 수 있다. 따라서 충분히 계산해서 처리할 수 있다.
SCAN
헤드를 한쪽 방향으로 움직이면서 요청을 처리하고, 반대 방향으로 이동한다. 이는 공평하면서도 적당히 빠르다. 이는 엘리베이터 알고리즘이라고 하기도 한다. elevator alogrithm.
일반적으로 SSTF와 SCAN이 많이 사용된다. 단, 디스크 요청이 많은 경우에는 SCAN이, 그렇지 않은 경우에는 SSTF가 많이 사용된다. 예를 들어 영화를 계속 트는 경우에는 파일을 계속 읽기에 한쪽 방향으로 쭉 왔다갔다하는 SCAN을 많이 사용한다.
C-SCAN
양 끝에 있는 얘들의 우선순위가 낮아지기에 한쪽 방향으로 가면서 처리하고, 다른 쪽 방향으로 가는게 아니라 반대쪽 끝으로 간 뒤 다시 한번 더 같은 방향으로 스캔하는 circular scan 방식이다. 그런데 쓸데없는 오버헤드가 발생하기에 그냥 scan이 더 많이 사용된다.
C-Look
요청이 끝까지 있지 않으면 중간에 멈추고 반대방향으로 간다.
selecting a disk scheduling algorithm
SSTF가 일반적으로 사용된다. 일반적인 웹서버도 이를 사용한다.
디스크 요청이 많으면 SCAN을 더 많이 사용한다. 뭐가 가장 짧은지 판단하지 않고 이를 처리한다.
Disk controller
I/O 디바이스 중 디스크를 컨트롤한다. 예전에는 운영체제가 하던 작업을 컨트롤러가 작업한다. 이에 따라 운영체제가 더 빨라진다. 이는 작은 컴퓨터이다.
- read ahead
- caching
- reordering(스케줄링)
- retry
- bad block 찾기
- bad block에 있는 것을 다른 스페어 블락에 연동하는 것
위의 작업을 OS가 하다가 컨트롤러가 작업한다.
Swap-Space management
VMM를 할 때 세컨더리 스토리지에 피지컬 메모리를 저장한다. 이를 스왑이라 한다. 스왑 스페이스를 관리하는 것도 OS가 해야한다. 윈도우즈는 파일로 저장하고, 리눅스는 별도의 파티션을 만들어서 스왑 스페이스를 관리한다. 메인메모리의 두배를 스왑스페이스로 잡고 리눅스는 설치된다. 윈도우즈는 별도의 스페이스를 잡지 않는다.
RAID(redundant Array of Inexpensive Disks)
NAS에서 많이 쓰인다. Network attached storage

비싸지 않은 디스크(예를 들어 하드디스크)를 중복해서 두어서 신뢰도(reliability)를 높인다. 두번째로 병렬, 동시성을 이용해서 성능을 높인다.
신뢰도를 높이기 위해서 미러링, 쉐도잉과 같은 방법으로, 동일한 내용을 저장하는 방법이 있다. 따라서 하나가 고장나더라도 다른 하나가 남아있게 된다. 하지만 이는 용량이 많이 소모되기에 패리티를 사용하거나 에러 검출 코드를 사용할수도 있다.
성능을 높일 수도 있다. 데이터를 저장할 때 디스크 블럭 n번을 나눠서 여러 디스크에 저장할 수 있다. 데이터를 저장하거나 읽을 때 줄처럼 여러 디스크에 나눠서 저장한다고 해서 이를 스트라이핑이라 한다. 하나의 블럭을 여러 디스크에 저장해서 동시에 읽는 방법을 bit-level data striping이라 한다.만약 각각 하나의 블럭을 단위로 여러 디스크에 각각 저장하는 경우에는 block-level data striping이라 한다.
하드디스크인 경우에는 일반적으로 비트레벨보다 block-level data striping의 성능이 더 우수하다. seek를 한번 할 때 더 많이 읽을 수 있기 때문이다. 따라서 비트레벨은 거의 사용하지 않는다.
비트레벨은 병렬(Parallelism)을 이용해 성능을 높이고, 블럭 레벨은 동시성(concurrency)을 사용해 성능을 높였다. 비트레벨인 경우에는 하나의 요청을 여러 디스크가 나눠서 서비스를 하기 때문에 병렬이다. 블럭 레벨은 여러 요청을 각 디스크가 읽어서 처리한다.
멀티플 디스크와 레이드
멀티플 디스크는 모두 독립적으로 존재한다. 하지만 레이드는 레이드 컨트롤러가 버스에 연결되어있다. 이때 디스크가 하나만 있다고 간주되면서 동작한다.
요즘에는 하드디스크보다 SSD를 더 많이 사용한다. 그렇기 때문에 RAID를 사용하지 않는 경우도 많다. 앞으로도 점점 사용되지 않을 가능성이 있다. 하지만 여기에 해당하는 개념은 앞으로도 적용될 수 있다.
RAID Levels
RAID 0

신뢰도를 고려하지 않고, striping만 한다. 블럭 레벨 스트라이핑만 한다. 데이터가 날라가도 큰 문제는 없고, 성능이 중요한 경우에는 이를 사용한다. 주로 VOD 서버가 이를 사용하는 경우가 많다. 백업이 있기 때문이다.
RAID 1

성능은 중요하지 않지만 신뢰도가 중요한 경우에 이를 사용한다.
똑같이 미러링해서 값을 저장한다.
RAID 2
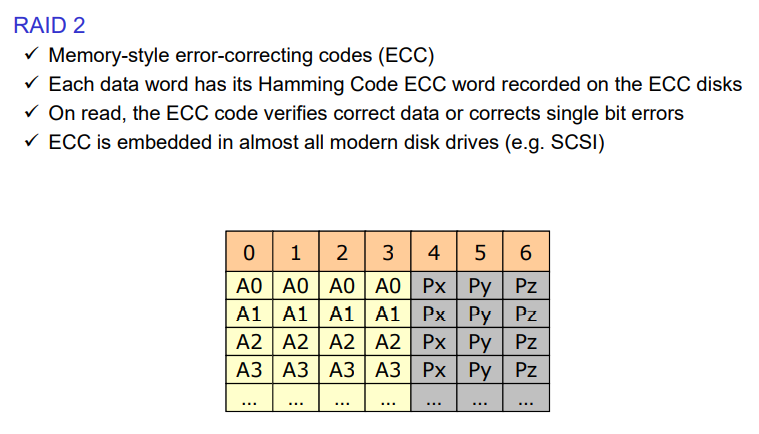
이는 잘 사용하지 않는다.
하나의 디스크 블럭을 네개의 디스크 블럭으로 나눠서 저장한다. 비트레벨 스트라이핑을 한다.
에러 검출 코드를 사용해서 신뢰도를 높이고자 한다. 따라서 최대 세개의 디스크가 고장나더라도 내용을 복구시킬 수 있다. 이를 위해 해밍 코드를 많이 사용한다. 하지만 네개가 고장나면 미러링을 하지 않는다면 내용을 복구할 수 없다.
RAID 3

이는 잘 사용하지 않는다.
에러 검출 코드를 하나만 둬서 이를 확인한다. 이는 패리티가 된다. 비트 0, 1, 2, 3 중에 하나가 고장나면 패리티를 이용해서 원래 것을 복구하고자 한다. 만약 두 개가 고장나면 복구할 수 없다.
RAID4

블럭 레벨 스트라이핑을 했다.
패리티 비트 하나만 써서 네개 중 하나가 고장나더라도 이를 복구시키도록 한다.
read 시에는 성능 상의 문제가 없다. 하지만 write을 할 때에는 블럭과 패리티를 모두 업데이트해야한다. 따라서 패리티 디스크가 매우 바쁘게 된다. 따라서 RAID 5에서는 디스크를 분산시킨다.
RAID5

RAID4와 마찬가지로 패리티 비트가 하나이지만 업데이트하는 디스크가 달라진다. 디스크 하나가 고장나더라도 복구가 가능하고, 비트 레벨보다 좋기에 이는 일반적으로 많이 쓰이는 컨피규레이션이다.
RAID6

에러 검출 코드를 사용한다. 이는 RAID 5보다 조금 더 신뢰도를 높이는 방법이다.
RAID 0+1
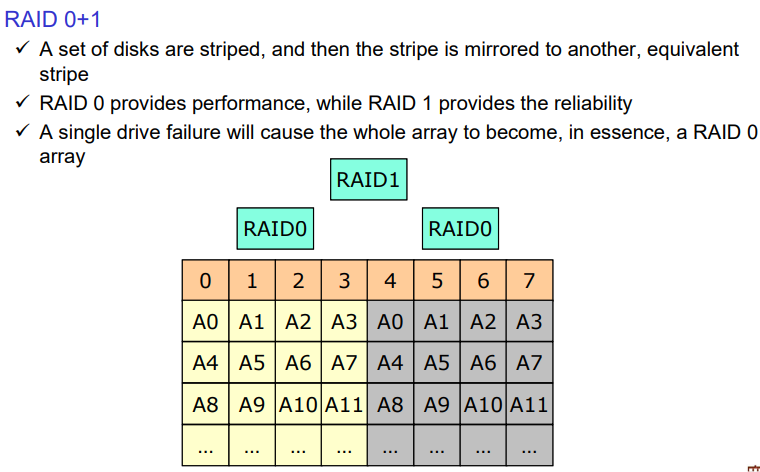
블럭레벨 스트라이핑한것을 미러링한다.
예를 들어 디스크 2가 고장나면 왼쪽의 RAID0을 못쓴다. 따라서 0, 1, 3도 모두 쓰지 못하게 된다.
RAID 10(or RAID 1+0)

미러링한 것을 블럭레벨 스트라이핑을 한다.
2번 디스크가 동작하지 않는 경우에는 두번째의 R1만 동작하지 않게 된다. 그 외의 디스크는 동작하게 된다. 따라서 이는 성능이 RAID 0+1보다 더 우수하게 된다.
'강의 내용 정리 > 운영체제' 카테고리의 다른 글
| 운영체제(12), I/O Systems (1) | 2022.12.19 |
|---|---|
| 운영체제(10), Virtual memory (0) | 2022.12.18 |
| 운영체체(9), Main Memory (0) | 2022.12.18 |
| 운영체제(8), Deadlocks (1) | 2022.12.18 |
| 운영체제(7), Synchronization Examples (1) | 2022.12.18 |