2022. 12. 18. 01:40ㆍ강의 내용 정리/운영체제
CPU Scheduling
복습
context switching을 할 때는 실제 프로세스보다 작은 단위인 쓰레드가 선택된다.
Process Execution
프로세스를 실행하는 것은 명령어를 실행하는 것이다. 명령어를 수행하다가 read from file이나 write from file이 등장하면 실제 해당 작업은 I/O 장치가 수행된다. 이때 명령어들의 집합을 수행하는 구간을 CPU burst, I/O가 끝나기를 기다리는 구간이 I/O burst이다.
CPU burst vs I/O burst

CPU-bound process
CPU burst가 길고 I/O burst가 짧은 구간
일반적으로 사용자와 인터렉티브하지 않은 프로세스 ex) 딥러닝, 과학 계산, 시뮬레이션 프로그램 등등
일반 사용자들이 쉽게 사용하는 프로그램은 아니다.
I/O-bound process
CPU burst가 짧고 I/O burst가 긴 구간
일반적으로 사용자와 인터렉티브한 프로세스
ex) HWP는 I/O-bound process이다.
웹브라우저는 I/O-bound process이다. 네트워킹을 하거나 파일을 읽든 모니터로 출력을 하는 등의 과정은 I/O이기 때문이다.
MP3는 I/O-bound-process이다. MP3를 읽은 뒤(I/O), 디코딩(cpu)을 하고, 스피커로 나가는(I/O) 동작을 반복하기에 I/O-bound process이다.
웹크롤링은 I/O 작업을 하는 것이지만 중간중간 눈으로 확인하지 않는 것일 뿐이기에 I/O-bound process이다.
게임은 키보드나 마우스의 인풋, 모니터 출력 등등을 많이하기에 I/O-bound process일 가능성이 높지만 cpu가 더 많은 연산을 하는 게임이라면 CPU-bound process가 될 수 있다.
Histrogram of CPU-burst Times
현재 많이 사용되는 프로그램은 cpu-burst process의 크기가 작은 프로그램들이 실행된 것이다. cpu burst는 많이 나오지 않는다.
Dispatcher
PCB를 바꿀 때 스케줄링이 이뤄지고, 선택된 프로세스를 상태를 바꾸는 과정만 디스패치라고 얘기하기도 하고, 더 넓은 의미에서 P0가 실행되다가 P1가 실행되는 것을 디스패치라고 얘기하기도 한다. 그때 상황에 따라서 용어가 다르게 사용될 수 있다.
Preemptive vs Non-preemptive
Preemptive
A 프로세스를 실행하다 B 프로세스가 A 프로세스를 중단시키고 CPU를 선점해서 B 프로세스를 실행시키는 것이 가능한 상태의 프로세스
모든 운영체제가 이 방식을 지원하기 때문에 컴퓨터에서는 이러한 상황이 일반적이다.
Non-Preemptive
다른 프로세스가 한 프로세스를 중단시키고 본인 프로세스가 실행되는 것이 불가능한 상태의 프로세스
일상에서는 이러한 상황이 일반적이다.
Scheduling Criteria
CPU utilization
CPU 이용
최대한 100% 이용하도록 해야한다.
Throughput
단위 시간 당 처리량
CPU의 Throughput: MIPS(밀리언 인스트럭션 퍼 세컨드) 초당 몇 백만 명령어를 실행하는가
네트워크의 Throughput: 단위 시간 당 전송량
Turnaround time
프로그램을 실행했을 때부터 끝났을 때까지의 시간
Waiting time
레디큐에서 기다리는 시간(waiting에서 기다리는 것 x)
어쩔 수 없이 프로그램의 특성 상 기다린다.
이를 최소화하는 것이 좋다.
Response time
사용자가 작업을 요청하고 그 작업에 대한 결과가 진행되는지 눈으로 확인할 때까지의 시간
즉, 어떤 작업을 시작한 뒤, 그 결과를 응답받는 시간을 의미한다.
예를 들어 progress bar가 이에 해당한다.
CPU utilization, Throughtput은 높이고 나머지는 낮추도록 노력해야한다.
Scheduling Goals
All systems

Fairness: 모든 프로세스를 공평하게 스케줄링해야한다.
Balance: 시스템의 모든 부분을 동일하게 사용하며 스케줄링한다.
Batch systems

현재 배치 시스템은 없다. 배치 시스템은 프로그램을 하나씩 동기적으로 실행시키는 시스템이다.
주요 요소
Interactive systems

사용자와의 대화형 시스템
Proportionality: 유저의 기대를 만족시킨다.
10명의 사용자에 대해서 돈을 많이 낸 사용자들에 대해 더 많은 서비스를 제공해야하기에 이를 고려해서 시간을 할당한다.
Real-time systems

주어진 데드라인 내에 일을 수행해야하는 시스템(소프트: 동영상 플레이어, 하드: 원자로 등등)
time이라는 제한 조건이 붙어서 무조건 빨리 실행하는 것이 아니라 데드라인을 만족하는 시스템이다.
Meeting deadlines
Predictability: 어떤 일이 수행될 때 허용 가능한 바운더리를 정해 그 안에서 동작하는지
cf) 덩치가 큰 운영체제는 어플리케이션이 수행되다가 커널에 서비스를 요청하면 커널이 수행된다. 하지만 운영체제가 할 일이 많은 경우에는 매우 짧게 수행되고 넘어가거나 어떤 경우에는 매우 길게 수행되고 넘어간다. 이러한 경우는 예측가능하지 않게 된다. 리얼 타임 시스템에서 사용하는 OS가 RTOS이다. 이는 Predictability가 중요하다. 마이크로 커널 운영체제가 이에 해당한다.
Scheduling Non-goals

Starvation (Indefinite blocking)
프로세스가 레디큐에서 너무 오랜시간동안 머물고 수행되지 않는 현상
Scheduling Algorithms
1) FCFS(First Come First Served)
스케줄링 알고리즘에서의 FIFO

모든 스케줄링 알고리즘에서 가장 처음으로 나온다. 이는 공정함(Fairness)의 원칙을 지키기 때문이다. 이는 일상 생활에서 널리 쓰이는 알고리즘이다. 따라서 이는 Non-Preemptive 방식이다.
장점
Fairness를 잘 지킬 수 있다. 이에 따라 Starvation이 없게 된다.
단점
Waiting time이 길어진다. 왜냐하면 앞에서 수행해야하는 시간이 길어지면 레디큐에서 프로세스들이 기다리는 시간이 길어지기 때문이다. 이를 보완하기 위해 SJF가 등장했다.
FCFS Scheduling
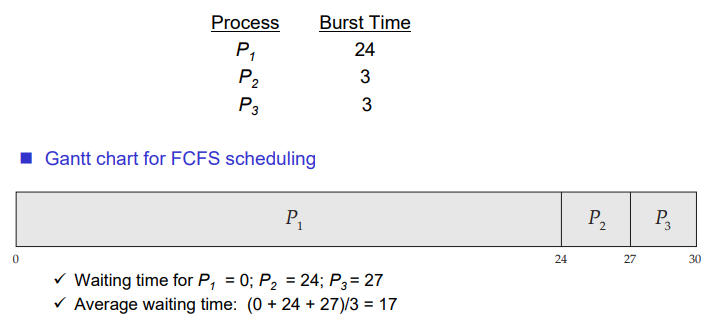
P1이 24만큼의 시간이 소요되고, P2, P3가 각각 3만큼의 시간이 소요된다면 Waiting time이 각각 0, 24, 27이 된다. 평균적인 Waiting time은 17이 된다.
만약 실행 시간이 짧은 프로세스로 순서를 바꾸는 경우 waiting time을 많이 줄일 수 있다. 따라서 FCFS가 등장했다.

cf) Convoy effect
실행 시간이 긴 프로세스 뒤에 실행 시간이 짧은 프로세스가 위치해서 늦게 동작하는 것
2) SJF (Shortest Job First)

Waiting time이 긴 FCFS의 단점을 해결하기 위한 Non-Preemptive 방식
평균 waiting time을 최소화한다.(optimal -> SJF보다 더 좋은 waiting time을 가지는 스케줄링 알고리즘은 없다.)
평균 waiting time을 줄이는 경우에는 고객의 만족도를 더 높일 수 있다.
일상 생활에서는 job에 대한 실행시간을 예측할 수 있다. 그러나 컴퓨터에서 프로세스를 실행시킬 때 CPU burst는 실행해야 알 수 있고, 이를 미리 알 수 없다. 따라서 이는 컴퓨터에서 적용할 수 없다.
cf) optimal
optimal은 그것보다 더 좋은 것은 없지만 그것과 동일한 효율인 것이 있을 수 있는 것을 의미한다.
ex) 힙소트, 머지소트 등등은 optimal이다. 시간복잡도가 O(nlogn)이기 때문이다.

cf) Gantt chart
시간별로 job을 그리는 것
평균 waiting time이 optimal하다.
3) SRTF(Shortest Remaining Time First)
Waiting time이 긴 FCFS의 단점을 해결하기 위한 Preemptive 방식

실행 중간에 그만두게하고 다른 프로세스를 동작시킬 수 있다.
P1 이후에 P2가 도착하기까지 1만큼의 시간이 소요되는데 P1(7)보다 더 적은 시간이 걸리는 P2(4)를 바로 실행한다.
즉, 프로세스가 도착한 시간에 대한 remaining time들을 비교해 프로세스를 실행한다.
Prediction of the length of the next CPU burst
CPU burst를 예측하는 것이 매우 어렵기 때문에 이를 사용할 수 없다.
4) Priority
우선순위에 따라 프로세스를 처리한다.

Priority를 어떻게 둘 것인가가 이슈가 된다.
SJF는 실행시간이 작은 순서로 우선순위를 두는 것이고, FCFS는 먼저 온 순서로 우선순위를 두는 것이기에 제너럴한 스킴으로 인식할 수 있다.
우선순위를 잘못 할당하면 Starvation이 발생할 수 있다. 이를 해결하기 위한 방법으로 Aging이 있다. 이는 우선순위를 나이로 두기에 다른 프로세스가 앞으로 끼어들 때마다 나이를 하나씩 증가시켜 언젠가는 처리가 되는 것을 의미한다.
Priority Scheduling
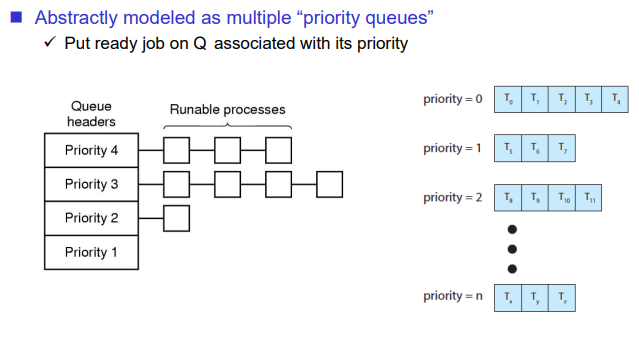
우선순위별로 Queue가 존재해서 우선순위가 높은 큐를 먼저 가져온다.
우선순위가 같은 프로세스들에 대해서는 일반적으로 Round Robin 방식을 사용한다. 왜냐하면 Non-Preemptive 방식은 컴퓨터에서는 많이 사용하지 않기 때문이다. 이 방식이 현재 운영체제의 스케줄링 방식이다.
Waiting time은 큰 고려사항이 아니게 된다.
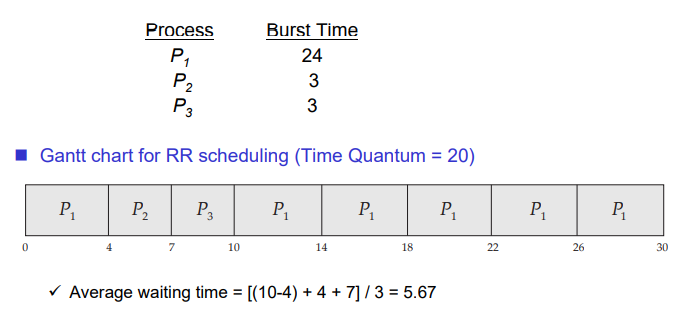
5) Round Robin(RR)

Preemptive 방식으로 프로세스를 조금씩 번갈아가며 실행시키는 방식이다.
타임 퀀텀을 주고, 이를 돌아가면서 스케줄링하는 방식이다.
FCFS처럼 Fair하면서 waiting time을 줄일 수 있는 방식이다.
지금 운영체제가 사용하는 방식은 Priority 방식과 Round Robin 방식이다.
이는 타임퀀텀을 얼마나 주느냐에 따라 trade off가 발생한다. 타임퀀텀의 크기를 크게 주는 경우에는 context switch가 발생하지 않을 수 있지만 타임퀀텀의 크기를 적게 주는 경우에는 context switch가 많이 발생한다. context switch가 많이 발생하는 경우에는 오버헤드가 발생할 수 있다. 또한 context switch를 너무 하지 않으면 response time이 커지기 때문에 이를 조절하기 위한 타임퀀텀을 잘 정하는 것이 주요한 이슈가 된다.
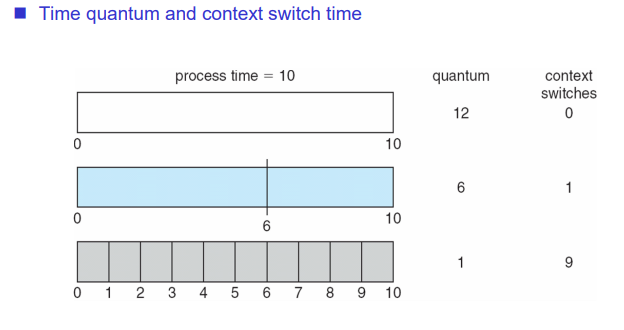
퀀텀의 크기를 무한대로 설정하면 FIFO가 된다. 퀀텀의 크기가 매우 작으면 프로세서를 공유하는 것이다. rule of thumb에 의해(경험의 법칙) cpu burst의 80%보다 작게 타임 퀀텀을 설정하는 것이 좋다고 나온다. 대략 60ms만큼 주어진다.
Combining Algorithms
6) Multi-Level Queue

위의 알고리즘을 섞어서 만든 방식
레벨을 여러개 둔 뒤, 큐별로 스케줄링 알고리즘을 다르게 설정한다.
ex) foreground, background
interactive한 프로세스는 foreground 큐에 두고, batch 프로세스(계산을 많이하는 프로세스)는 background 프로세스에 둔다. 예를 들어 interactive한 프로세스는 Round Robin을 사용하는 것이 좋다. background 프로세스는 FCFS로 돌린다.
큐 내부에서 스케줄될 때 사용하는 알고리즘

Fixed Priority scheduling
큐를 여러 개를 두고 우선순위가 높은 순서대로 먼저 동작시킨다. 같은 우선순위에서는 RR을 사용할 수 있다. 일반적으로 해당 스케줄링 알고리즘을 사용한다.
예를 들어
foreground의 우선순위가 높은 경우에 그것을 먼저 다 실행한 뒤, background를 실행하는 방법이 해당된다.
하지만 이는 Starvation 문제가 발생할 수 있다.
Time Slice(타임 퀀텀과 비슷)
starvation을 방지하기 위해서 큐별로 스케줄링에 대한 시간을 다르게 배분하는 방법이다.
Multilevel Queue Scheduling
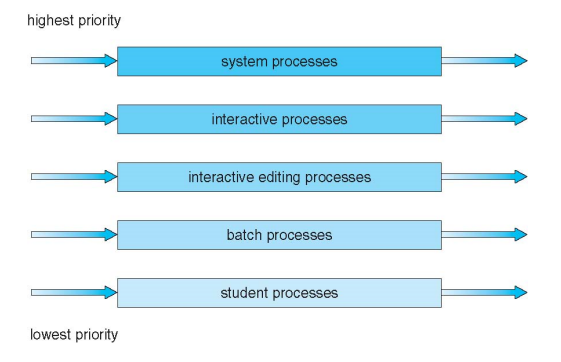
큐 내부에서는 본인이 원하는대로 스케줄링을 둘 수 있다. 일반적으론 RR을 사용한다.
프로세스가 생성되었을 때 프로세스에 대해 구분하기가 어렵다. ex) interactive한지, batch인지 알기 어렵다. 이를 위해 Multilevel Feedback Queue Sheduling을 사용한다.
7) Multi-Level Feedback Queue (MLFQ)
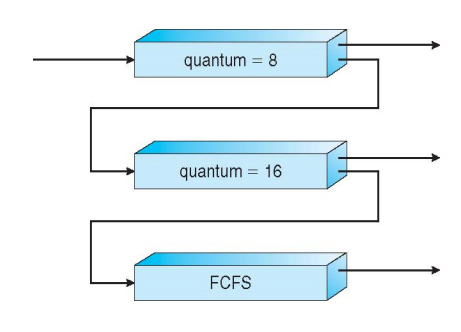
위의 알고리즘을 섞어서 만든 방식(1~5)
큐 간에 피드백을 전달한다. 전통적으로 유닉스에서 사용해온 알고리즘이다.
일단 동일한 큐인 time quantum=8인 곳으로 들어와서 RR을 수행한다. 이후 타임 퀀텀을 다 소비하고 타임퀀텀을 다 소비하기 전에 CPU를 나왔는지 타임퀀텀을 다 소비하고도 아직 남아있는지를 확인한다. 전자의 경우에는 CPU burst보다 I/O burst가 더 크게 된다. 따라서 이는 I/O bound process, interactive process가 된다. 후자의 경우에는 CPU burst가 크기 때문에 CPU bound process, batch process일 가능성이 높다. 타임퀀텀을 다 쓴 경우에는 큐에서 나온 뒤, 다시 quantum이 8인 큐로 들어간다. 따라서 타임퀀텀을 다 못쓴 프로세스는 아래쪽의 quantum = 18에서 대기하도록 한다. 만약 해당 타임 퀀텀을 다 소비하지 않으면 FCFS 큐로 들어가고 그게 아니라면 quantum = 8인 큐로 들어간다.
지금은 발전되었기 때문에 3~4개의 클래스를 거쳐서 170개의 우선순위를 가지게 된다.
큐별로 priority 스케줄링이고, 큐 내부에서는 RR을 돌린다.
Motivation
interactive인지 batch인지 모르기 때문에 interactive에 우선순위를 주기 위해서 해당 방법을 사용했다.
멀티코어에 대한 스케줄링 이슈
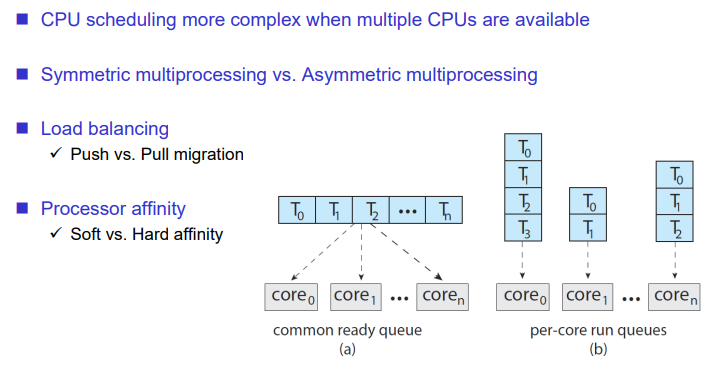
Symmetric multiprocessing vs Asymmetric multiprocessing
Asymmetric은 현재 없다. 이는 main 프로세스가 있고, 그 밑에 slave 프로세스가 존재한다. CPU 성능이 쎈 것과 작은 것들이 있다. main cpu에서 slave cpu를 관장한다.
Load balancing
멀티코어에서는 N개의 코어에 대해 로드를 밸런싱하는 것이 중요한 개념이다.
프로세스가 core0에서 core1로 옮기면 이를 migration이라 한다.
예를 들어 Core0에서 수행되는 프로세스가 많아서 다른 코어로 프로세스를 옮기는 작업을 push migration이라 한다. 반면 한 core가 놀고 있기에 다른 core에게서 프로세스를 가져오는 것이 pull migration이다.
멀티 코어 스케줄링에서는 Processor affinity를 고려해야한다. 여러 코어에서 돌아가며 쓰레드를 스케줄링 하는 것과 각각 코어마다 쓰레드를 할당해서 처리하도록 하는 경우가 있다. 전자는 a, 후자는 b에 대한 내용이다. 후자와 같이 하나의 쓰레드는 하나의 코어에서 실행시키는 경우에는 코어별로, 혹은 cpu별로 캐쉬메모리가 존재하기 때문에 이를 사용할 수 있어서 효율적이다.
성능이 중요한 프로세스이거나 쓰레드의 경우에는 CPU 하나에만 넣어서 실행시키도록 하는 것이 Processor Affinity이다.
Soft affinity는 할 수 있으면 하도록 요청하는 것, Hard는 강하게 요청하는 것을 의미한다.
cf) context switch 횟수는 동일하다.
Realtime Scheduling
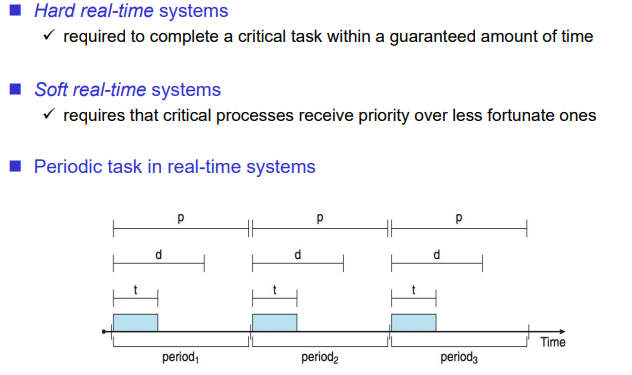
deadline을 만족시키지 못하면 안되는 시스템의 스케줄링
Static vs Dynamic Priority Scheduling
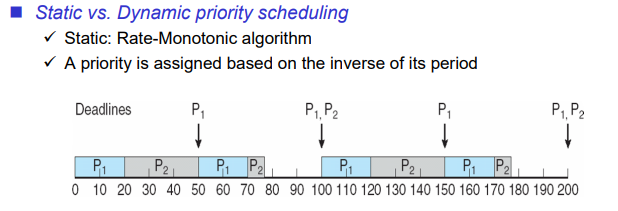
Static Priority Scheduling
우선순위가 프로세스별로 고정되어서 우선순위가 바뀌지 않는 스케줄링 방법
Rate-Monotonic algorithm
Static Priority Scheduling에서 가장 많이 사용되는 알고리즘이다. 자주 실행되는 것에 우선순위를 먼저 주는 방법이다.
rate은 주기를 의미한다. rate이 작으면 자주 실행되고 rate이 크면 띄엄띄엄 실행된다. realtime system은 대부분 임베디드 시스템이다. 전원이 켜지면 일반적으로는 이미 만들어진 프로세스를 전원이 꺼지기 전까지 계속 실행하게 된다. 즉, 프로세스가 주기적으로 실행된다. 주기가 크면 가끔 실행이되는 것이고, 주기가 작으면 자주 실행된다. rate에 비례해서 Priority를 주는 방법을 의미한다. 자주 실행되는 것에 우선순위를 먼저 주는 방법이다.
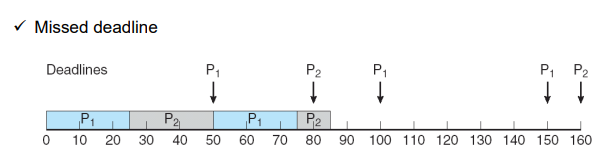
위의 방법과 같이 설계하면 잘못 설계가 된 것을 의미한다.
Dynamic Priority Scheduling

우선순위가 실행될 때마다 바뀌어서 실행되는 스케줄링 방법
EDF(Earliest Deadline First)
데드라인이 가장 가까운 것에 우선순위를 더 많이 준다. EDF는 optimal한 스케줄링이기도 하다.
해당 방법은 Miss가 나지 않는다. 하지만 이는 데드라인을 계속 확인해야하기에 오버헤드가 크다. 따라서 실제로는 이를 사용하지 않고, Rate-Monotonic algorithm을 사용하는 경우가 많다.
운영체제 Examples
기본적으로 우선순위가 높은 프로세스가 스케줄링되고, 동일한 큐에서는 RR로 실행된다.
Linux scheduling

Static한 Priority Feedback queue에서 동작한다.
Priority가 140개가 있다. 0~99까지는 정말 급하게 수행해야하는 프로세스, normal은 사용자가 실행시킨 프로세스이다. real time은 시스템이 생성한 프로세스이거나 리얼 타임 프로세스일 수 있다.
0이 우선순위가 높은 것이다.
리눅스에서 무한루프도는 프로세스가 존재한다면 처음에는 100이라는 우선순위를 가지고 실행되다가 타임 퀀텀을 다 쓰면 우선순위가 계속 낮아지게 된다. 0~99의 우선순위는 한번 우선순위를 가지면 바뀌지 않는다. 또한 100~130에서는 프로세스가 수행되면서 CPU를 많이 사용하면 우선순위가 낮아지고, CPU를 조금 사용하면 우선순위를 높이는 식으로 계속 우선순위가 바뀐다. 이를 nice value라고 한다. 이는 CFS라는 알고리즘을 사용했다.
CFS(Completely Fair Scheduling)

프로세스별로 vruntime을 가지고 관리한다. vruntime은 실행한 시간을 virtual하게 가지고 있는 변수이기에 이 값이 작을 수록 우선순위가 높게 책정되도록 하는 방식이 있다. 각 프로세스에 대해서는 레드블랙트리로 이를 관리해서 balance 이진트리로 만들어서 가장 왼쪽에 있는 값이 제일 작은 값이 되도록 유지한다. 이는 O(n)의 시간복잡도를 가지는 알고리즘이 된다.
따라서 리눅스 스케줄링은 real time 클래스의 프로세스는 Fixed priority scheduling을 하고, normal 클래스의 프로세스는 CFS로 스케줄링한다.
Windows scheduling
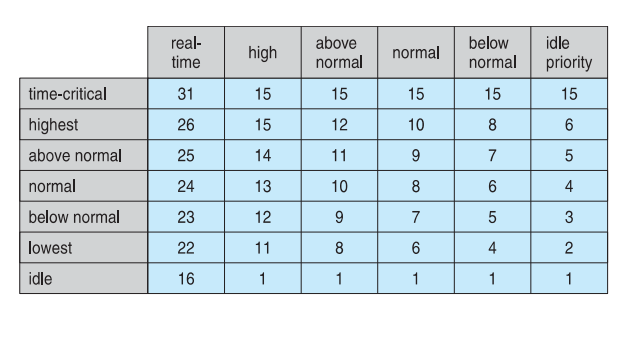
숫자가 클수록 우선순위가 높다. 클래스가 여러개가 있다. 프로세스가 생기면 우선순위를 가지고, 동일한 우선순위에서는 RR, 우선순위가 다르면 Fixed priority scheduling을 한다.
Solaris scheduling
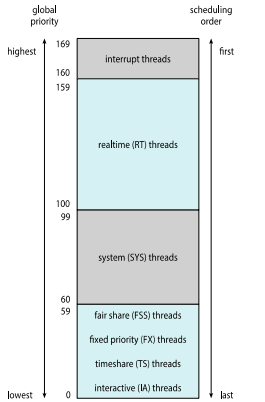
솔라리스에서는 클래스를 네 개 정도로 나눠서 우선순위를 준다. 이 또한 마찬가지로 우선순위가 높은 것부터 실행된다. 이는 리눅스와는 다르게 closed system이다. 따라서 깊이 살펴보는 데에는 어려움이 있을 수 있다.
알고리즘 평가

어떤 알고리즘이 좋은가? 윈도우즈와 같이 PC에서 사용하는 운영체제와 서버에서 사용하는 운영체제 등등 다른 환경에서 어떤 알고리즘이 좋은가?
구현하는 것이 제일 좋지만 구현이 어려운 경우가 있을 수 있다. 예를 들어 라우팅 알고리즘을 평가하기 위해서 구현하는 것은 불가능하다. 이러한 경우에는 시물레이션을 한다.
Deterministic modeling
Queueing models
두 방법 모두 수학적인 방법으로 알고리즘을 평가한다. 따라서 clear하게 평가가 가능하다. 하지만 수식을 인풋으로 해야하고, real world data로 평가할 수 없기에 똑같은 결과가 나오기는 어렵다.
Simulation
어떤 환경을 가정하고, 동일한 인풋에 대해 성능을 비교한다. 현실적으로 이를 많이 사용한다.
인풋을 real world data로 하는 경우에는 정확도가 더 높아진다. 이는 trace tape(trace data)라고 한다.
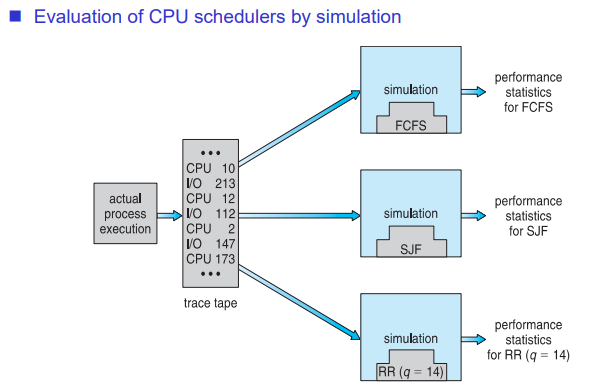
cf) Emulation
에뮬레이션과 시뮬레이션 모두 컴퓨터에서 프로그램으로 동작하게끔하는 것이다. 하지만 에뮬레이션은 하드웨어의 동작을 100% 똑같게 소프트웨어로 만든 것, 시뮬레이션은 실제 세계에 있는 것을 대충 구현한 것을 의미한다. 예를 들어 앱 인벤터와 같이 안드로이드 폰을 개발할 때에서는 안드로이드 에뮬레이터에서 스마트폰과 100% 호환되게끔 개발하고, 이를 앱으로 만든다.
implementation
제일 좋은 방법이지만 시간과 노력이 많이 투입되기 때문에 현실적으로 이를 하기 어렵다.
퀴즈 리뷰
쓰레드에서는 Shared memory가 일반적인 방법이기에 전역변수를 공유하는 data segemnt, 코드를 공유하는 code segment는 공유한다. 각 쓰레드는 함수에 하나씩 가지고 있기에 스택과 CPU register는 공유하지 않는다.
NUMA는 CPU 아키텍처이지만 프로그래밍은 아니기에 parallel programming은 아니다.
window에서는 one-to-one 으로 프로그램과 쓰레드를 매칭한다.
'강의 내용 정리 > 운영체제' 카테고리의 다른 글
| 운영체제(7), Synchronization Examples (1) | 2022.12.18 |
|---|---|
| 운영체제(6), Synchronization Tools (0) | 2022.12.18 |
| 운영체제(4), Threads & Concurrency (1) | 2022.12.18 |
| 운영체제(3), Processes (1) | 2022.12.18 |
| 운영체제(2), Operating System Structures (0) | 2022.12.18 |