2022. 12. 18. 04:06ㆍ강의 내용 정리/운영체제
Synchronization Tools
CPU sheduling을 할 때에는 Fair하면서 response time을 최소화 하는 것이 중요했다.
이번 챕터에서는 프로세스 동기화에 대해 배울 예정이다.
프로세스 생성, 종료, 협력(Inter process communication) 등에 대해 얘기했고, 이는 쓰레드도 마찬가지이다. 예를 들어 크롬 브라우저는 플러그인 프로세스, 탭 별로 렌더링 프로세스, 브라우저 프로세스 등등이 있었다. 사용자의 입력이나 디스크를 읽거나 리모트 웹을 읽는 역할의 브라우저 프로세스이 수행되고, 어떤 시점에서 렌더링 프로세스와 동기화가 되어야지 데이터를 주고 받을 수 있다.
어떤 시스템 콜을 사용해서 동기화를 이뤄낼 것인가, 혹은 동기화를 커널이 알아서 하거나, 어플리케이션 프로세스나 쓰레드에게 커널이 사용하는 툴을 제공하기도 한다.
IPC의 두 가지 모델
Kernel은 시스템콜의 형태로 이를 지원한다.
1. Message passing
커널에 메세지 큐를 만들고, 한 프로세스가 메세지 큐에 메시지를 집어넣고, 다른 프로세스가 큐에서 메세지를 꺼내가는 형태이다.
메세지 큐에 데이터를 보내는 시스템콜, 꺼내는 시스템콜이 있다.
Message passing의 장단점
한 프로세스가 커널에 메시지를 쓰고, 다른 프로세스가 커널에서 메시지를 읽고 쓰기 때문에 상대적으로 느리고 복사에 의한 오버헤드가 발생한다. 하지만 동기화를 커널이 알아서 한다는 장점이 있다. 데이터를 읽고자 했지만 없다면 데이터를 요청한 프로세스를 waiting 상태로 만들어서 레디 큐에서 제외한다. 따라서 해당 프로세스는 blocking된다. 이후 다른 프로세스가 메세지를 넣으면 waiting을 마무리한다.
동기화를 커널이 알아서 해준다는 장점 때문에 Message passing을 많이 사용한다.
2. Shared memory
서로 다른 두 프로세스가 모두 접근 가능한 새로운 공유 메모리를 생성한다.
공유 메모리를 생성하는 것은 운영체제가 한다.
하지만 한 프로세스가 데이터를 썼는지 알 수 있도록 동기화 매커니즘을 커널이 제공해야한다.
Shared Memory의 장단점
메모리에 직접 데이터를 쓰기에 메모리 공간을 적게 사용한다. 하지만 운영체제는 공유 메모리를 만드는 데에만 관여를 하고, 그 이후에는 어플리케이션 프로세스끼리 동기화를 해야한다. 이때 툴을 이용해서 직접 프로그래밍을 해야한다. 하지만 멀티 쓰레드 모델에서는 일반적으로 세마포나 뮤텍스 락을 사용한다.
Synchronization
멀티 쓰레드 프로그램에서 쓰레드들 간에 서로 협력하는 환경일 때 쓰레드들이 리소스를 공유하거나 Shared data structure에 접근한다던지 등등에 대해 실행 순서를 조정하는 것을 의미한다. 멀티 쓰레드를 작성할 때는 동기화에 대해 고려하지 않으면 Synchronization Problem이 발생할 수 있다.
cf) 이는 쓰레드 뿐만 아니라 프로세스도 해당된다.
Example

남자친구와 여자친구가 은행 계좌를 공유하고 있고, 100만원이 있다. 신용카드는 남자와 여자가 모두 가지고 있고, 이를 통해 돈을 인출할 수 있다.
남자친구는 강남에서, 여자친구는 학교에서 돈을 인출할 때 우연히 동일한 시간에 돈을 인출하라는 요청을 보냈다. 이때 트랜잭션이 발생한 것을 처리하기 위해 각 프로세스나 쓰레드를 만들어서 서비스를 하게 된다. 이떄 쓰레드 바디에서 가장 중요한 함수가 아래에 해당한다. 이는 현재 동시에 실행되는 함수가 된다.
get_balance를 통해 잔고를 가져오고 계산을 한 시점에서 interrupt가 발생할 수 있다. (timer도 발생 가능) 현재 해당 쓰레드는 실행을 어느 정도 했으니 인출을 요청한 다른 쓰레드가 요청될 수 있다. 그렇게 되면 아직 이전 쓰레드에서 put_balance가 되지 않았기 때문에 100만원을 그대로 가져오고 이를 계산하게 된다. 결국 은행의 잔액은 90만원이지만 20만원을 인출한 상황이 발생할 수 있다. 이 예시가 Synchronization problem이 된다.
결국 Shared하는 프로그램을 만들 때에는 위의 문제를 인식하고 만들어야한다.
일반적으로 멀티 프로세스보다 멀티 쓰레드가 더 Synchronization problem을 고려해야한다. 왜냐하면 IPC 모델에서 쓰레드는 Shared memory model을 사용하는 경우가 일반적이고, 프로세스는 Message passing 모델을 사용하는 경우가 일반적이기 때문에 쓰레드는 이를 더욱 많이 고려해야한다. 왜냐하면 멀티 쓰레드에서 전역변수가 Shared memory이기 때문이다. 따라서 쓰레드는 동기화 문제를 더욱 고려해야한다.
다른 예시로 프로듀서와 컨슈머 프라블럼이 발생할 수 있다.
Bounded buffer(Producer-Consumer)
Producer Process와 Consumer process가 있을 때 shared memory로 Circular queue를 가지고 있다. Producer는 데이터를 넣는 프로세스, Consumer는 Circular queue에 있는 데이터를 가져오는 프로세스이다. Producer는 데이터가 꽉차지 않으면 데이터를 집어넣는 구조이다. Consumer는 데이터가 없으면 반복해서 가져오지 않다가 데이터가 생기면 이를 가져오는 역할을 하는 구조를 가진다.
자료구조에서 봤을 때에는 하나의 쓰레드를 가지고 사용하기에 문제가 발생하지 않았다. 하지만 멀티 쓰레드 환경에서 동시에 데이터를 삽입하고, 데이터를 빼내는 경우에는 count에 문제가 발생할 수 있다. 디버깅 단계에서는 문제가 발생하지 않을 수 있지만 현실에서는 맞지 않을 수 있게 된다. 즉, 특정한 타이밍에서만 문제가 발생하고 일반적으로는 발생하지 않는다.
위의 코드에는 두 가지 문제가 있다. 데이터를 삽입하거나 삭제할 때 동기화작업을 하지 않았다. count라는 전역변수를 가지고 사용하기에 아래와 같은 문제가 발생할 수 있다. 컴파일된 코드를 확인해보면 각자 다르게 설정하는 것을 볼 수 있다.
또한 Producer에서는 count가 N이 되면 무한루프를 돌고, Consumer에서는 count가 0이 되면 무한루프를 돌게 된다. 이는 count가 전역변수로 설정되었기 때문에 멀티 쓰레드에서 가능한 코드이다. 이는 각 프로세스의 타임퀀텀을 interrupt할 때까지 이를 계속 돌리고, 레디큐에 들어간 뒤, 다른 프로세스의 우선순위가 더 높아지기에 다른 프로세스를 실행시키게 된다. 하지만 해당 코드는 CPU를 낭비하는 방법이기에 문제로 볼 수 있다.
Problem
Synchronization problem (= Critical section problem)
두 개 이상의 프로세스가 계좌, linked-list 뿐만 아니라 전역변수 하나 등등과 같은 Shared memory를 엑세스할 때 발생할 수 있는 문제를 의미한다. 이는 race condition이라 한다.
race condition
두 개 이상의 concurrent한 쓰레드가 shared resource를 사용하기 위해 서로 경쟁하는 상황이나 조건을 의미한다. 이러한 상황 하에서는 Synchronization problem이 발생할 수 있다. 즉, race condition을 만족한다면 Synchronization problem이 발생할 수도 있다. (항상 발생하는 것은 아니다.)
cf) 위처럼 항상 발생하는 것은 아니다는 의미는 결정적이지 않다.(Non-deterministic)
위와 같은 상황에서는 Synchronization 메가니즘이나 툴을 사용해서 문제를 해결한다.
Requirements for synchronization tools
동기화 툴이 갖춰야할 요구사항 3가지
(1) Mutual Exclusion (Mutually exclusive access)
가장 중요한 요구사항으로 shared memory는 한번에 하나씩만 사용할 수 있도록 한다.
위의 예시에선 남자친구가 인출을 할 때에는 여자친구가 인출/입금하지 못하도록 한다.
Critical section에는 하나의 쓰레드만 들어가도록 해야한다.
(2) Progress
shared memory를 사용하고자 할 때 아무도 안쓰면 바로 사용할 수 있도록 한다.
(3) Bounded Waiting
누군가가 Shared memory를 사용한다면 기다리기는 하지만 언젠가는 사용할 수 있어야한다는 요구사항이다.
Synchronization Tools

1. Locks(low level mechanism)
lock(): lock을 건다.
unlock(): lock을 해제한다.
기본적으로는 lock이 풀려있는 상태가 된다. 누군가가 shared data를 사용할 때에는 lock을 건 뒤, 이를 사용한다. 이에 따라 다른 프로세스가 사용하지 못하도록 막는다. shared data를 다 사용한 뒤에는 unlock을 해서 다른 프로세스가 사용할 수 있도록 한다. 이에 따라 최대 한개의 프로세스만 접근할 수 있도록 한다.
lock의 종류
spinlock
락이 걸려있는 경우 무한 루프를 돌도록 설정해 CPU를 사용하며 락을 거는 방법
mutex
Using Locks
코드를 작성할 때 account의 잔액을 가져오고 변경하는 부분이 shared data를 사용하는 코드 부분이기에 이러한 부분을 critical section이라 한다. critical section은 race condition을 유발하는 코드/데이터 세그먼트 영역(shared data를 사용하는 세그먼트 영역)이다. lock을 걸고 해제하는 부분은 이러한 부분을 포함해야한다.
shared data를 사용하기 전에 lock을 걸고, 다 사용한 뒤에는 lock을 푼다.
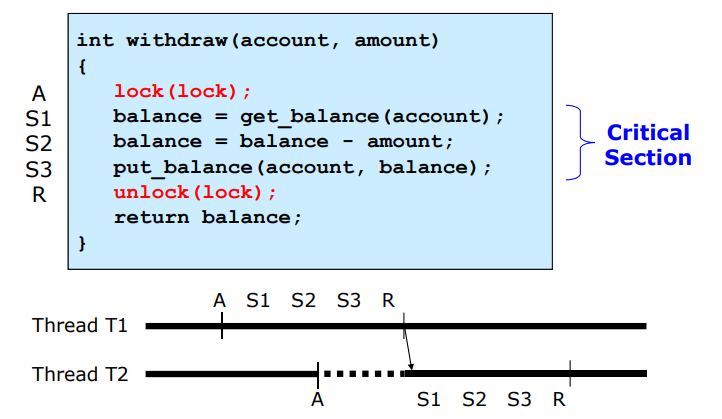
위의 코드는 아무도 사용하지 않을 때 들어가기에 progress를 만족한다. 중간에 T2는 interrupt를 걸게 된다. 그렇게 되면 T1은 ready로 돌아간다. 하지만 Critical section은 lock이 이미 걸려있기에 waiting 상태로 기다리다가 T1이 다시 실행된다. T1이 unlock을 하게되면 T2가 lock을 걸면서 실행한다. 따라서 bounded waiting도 만족했다. 또한 Critical section을 Mutual Exclusion을 했다. 따라서 위의 세 가지 특징을 모두 갖추는 메카니즘이 되고 Synchronization problem을 해결할 수 있게 된다.
T1은 ready로 돌아가기에 unblock을 안한다. 즉, blocking 되어서 waiting되어야한다.
lock의 구현
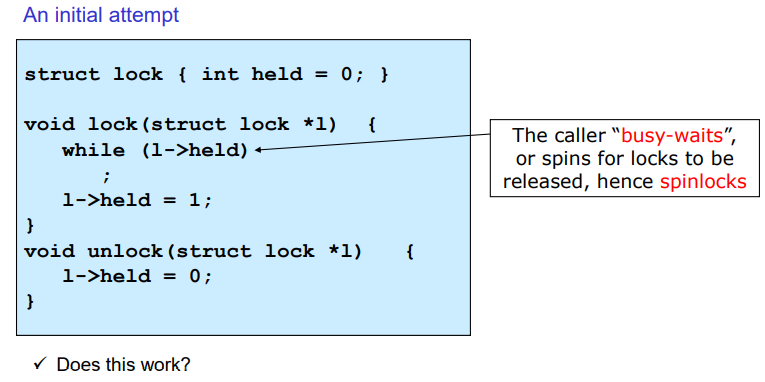
초기에는 락이 안걸려있는 상태이다. held가 1이면 락이 걸려있는 상태이기에 이때 무한루프를 돌도록 한다. 하지만 이는 CPU를 사용하면서 wait을 하는 중이다. 이를 busy-waits라고 이야기한다. 이렇게 루프를 돌면서 lock을 거는 형태를 spinlock이라 한다. busy-waits는 바람직하지 않는 방법이다.
해당 방법은 제대로 동작하지 않을 수 있다. 예를 들어 남자친구가 lock을 걸고자해서 들어왔을 때 held가 0이 기에 while문을 빠져나오고 held에 1을 넣기 전에 인터럽트가 걸릴 수 있다. 이후 여자친구 쓰레드가 동작할 때에는 lock을 걸고자해서 들어왔을 때도 held가 0이기에 while문을 빠져나오게 된다. 따라서 Critical Section에 두 개의 쓰레드가 들어오게 된다.
결국 lock 함수에서도 held가 shared data가 되기에 문제가 발생할 여지가 있는 것이다. 결국 critical section은 context switching이 되지 않게 수행되어야한다. 이를 Atomic operation되도록 설정해야한다.
해결방안

Software-only algorithms
베이커리 알고리즘 등등 알고리즘으로서는 의미가 있지만 성능에는 문제가 있을 수 있다. 따라서 운영체제에서는 실제로 사용되지 않는다.
Hardware atomic instructions
(1) Test-And-Set
CPU 명령어를 이용해 lock을 구현한다.

해당 역할을 하는 것은 하나의 CPU 명령어로 실행시키는 것이다. while문에서 이를 사용하는데 하나의 명령어이기에 atomic하고, interrupt에 의해 쪼개질 수 없다.

남자친구 쓰레드가 lock을 걸려고 들어오면 held의 현재값을 리턴하니 0이 리턴된다. 이후 held가 1이 된다. 이는 동시에 이뤄지기에 중간에 interrupt가 될 수 없다. Held는 1이니 이후에 다른 쓰레드가 수행되지는 못한다. 따라서 위의 예시와는 다르게 이를 하나의 CPU 명령어로 뒀기에 쪼개질 수 없게 된다.
위와 동일하게 Compare and Swap으로도 구현할 수 있다.
(2) Compare-and-Swap


b라는 변수를 true로 두고 이를 바꾸면 위와 거의 동일하게 동작한다. 인텔 cpu에서는 cmpxchg라는 명령어가 있어서 이를 사용한다. 이때 held의 값을 리턴하고, held의 값을 key 값으로 바꾼다. Key는 true이기에 while문을 빠져나오면서 동시에 held의 값이 1이 된다. 해당 방법이 현재 사용하는 방법이다.
Spinlock의 단점
그러나 spinlock은 wasteful하다는 단점이 있다. 그렇기 때문에 spinlock은 어플리케이션이 사용하는 방법이 아니라 critical section이 짧은 운영체제가 아주 짧은 시간 동안 해야하는 방법이다. 어플리케이션은 운영체제가 별도로 제공하는 다른 메커니즘을 이용해야한다. 이 때에는 프로세스나 쓰레드가 wait하도록하는 메커니즘을 사용해야한다. 그 메커니즘을 구현할 때에는 spinlock을 이용해서 운영체제가 구현해야한다. 결국 higher-level synchronization을 구현할 때에는 짧은 구간의 critical section에 대해 운영체제가 primitive하게 사용하는 방법이다.
결국 어플리케이션의 경우 spinlock을 사용해 구현하는 것이 아니라 운영체제가 해당 어플리케이션을 wait하도록 구현해야한다.
Disable/re-enable interrupts
여기서의 interrupt는 hardware interrupt이다. 즉, 키보드, 마우스, 디스크, 네트워크 등등 I/O 디바이스에 의해 발생하는 interrupt이다.
RTOS에서 많이 사용하는 방법이다. Interrupt가 걸려야지 운영체제가 수행되며 다른 쓰레드로 context switching이 발생하면 race condition이 되기에 이를 막아놓는 방법이다. 하지만 어플리케이션 프로세스나 쓰레드는 interrupt를 막을 수 없기에 운영체제가 higher-level synchronization(mechanism)을 구현할 때 짧은 구간만 사용하는 방법이다.
동작 과정

운영체제가 disable을 cpu에게 요청 -> cpu는 interrupt가 수행되지 못하게 함(interrupt를 지연시킴) -> 해당 기간동안에는 운영체제가 수행되지 못한다.
또한 운영체제만 하더라도 interrupt가 발생하면 안되는 구간이 길면 사용하기 어렵다. Interrupt enable, disable하는 것은 cpu이다. 그러나 cpu가 두 개 이상이라면 모든 cpu를 disable하지 않으면 의미가 없기에 이는 cpu가 하나만 있을 때 사용하는 방법이다. Cpu가 두 개 이상이면 compare and swap을 사용해야한다.
반면 짧은 구간이고, CPU가 하나인 경우에는 이 방법의 구현이 더 쉽다. 또한 RTOS와 같이 멀티플 프로세스를 사용하지않는 환경에서는 cpu가 cmpxchg와 같은 명령어를 제공하지 않는다. 따라서 이때는 무조건 disable 방법을 사용해야한다.
문제점
운영체제가 짧은 구간의 critical section에 대해 사용하지만 멀티플 프로세서에서는 사용할 수 없다.
이는 운영체제에서 사용하는 방법이다.
High-level Synchronization
Motivation
운영체제가 system call 서비스로 제공해야한다. 하지만 이를 운영체제에서 구현할 때 운영체제 내부에서 critical section이 또 발생할 수 있으니 이 또한 spinlock이나 disable하는 방법을 사용해야한다.
1) Semaphores
기찻길에서 단선에서 복선이 되는 부분에 기차가 동시에 접근하지 못하도록 와도 되는지, 오면 안되는지 표시하는 깃발이 Semaphores이다.
Semaphores는 Integer 변수인 counter이다. 이는 shared data의 개수를 나타낸다. 여기에 행해지는 오퍼레이션은 각각 P, V이다. P는 wait로 -1을 한다. V는 signal로 +1을 한다.
Shared data를 사용하려는 프로세스가 Semaphores의 값을 확인한다. 이 값이 1이면 사용하고, P 오퍼레이션을 동작한다. 다른 프로세스는 이때 Semaphores의 값이 0이기에 이를 기다린다. Lock과 비슷한 개념이다.
Critical section의 shared data의 개수는 한 개고, semaphores의 개수가 양수면 이를 사용할 수 있고, 0이면 사용할 수 없다. 0이면 -1을 할 수 없으니 wait으로 표기한다. 다 쓰고 반납하면 쓰라고 신호를 보내는 의미로 signal로 표현한다. 위와 같은 Semaphores는 binary semaphores이다. 그 외의 값을 가지고 사용하는 Semaphores는 counting Semaphores라고 한다. Semaphores의 값이 0과 1 사이는 binary Semaphores, 그 외엔 counting Semaphores이다.
Critical section에서 Semaphores를 사용하면 초기 값은 1로 하면 된다. 들어가기 전에 wait을 하기에 값이 0이 되고, 다 끝난 뒤에는 1로 증가한다.
서버에서 이를 사용할 때는 resource가 매우 많아지기에 Semaphores의 값을 늘릴 수 있다. 만약 5대의 프린터를 여러 프로세스가 사용하고자 한다면 Semaphores의 수를 5만큼 설정하여 이를 사용할 수 있다. 이를 Counting Semaphores라고 한다.
Semaphores의 사용

Critical section을 보호하는 상태에서는 lock과 unlock의 위치에 wait, signal을 보낸다. Mutex는 mutual exclusion인데 Semaphores인 변수의 이름일 뿐이다. 이때는 1의 값을 가지고 사용한다.

혹은 Semaphores의 값이 0부터 시작할 수 있다. 위의 예시에서는 A가 먼저 실행되고 B가 실행되는 환경에서 Pi는 바로 A를 실행하고 signal을 보낸 뒤, Pj는 wait을 한 뒤에 B를 실행시키는 식으로 진행한다. Pj가 먼저 스케줄링되더라도 A가 먼저 실행될 수 있도록 한 코드이다. 위와 같이 동기화를 할 때에는 응용할 수 있다. Critical section에 대해서는 wait, signal을 그대로 적어준다.
Synchronization
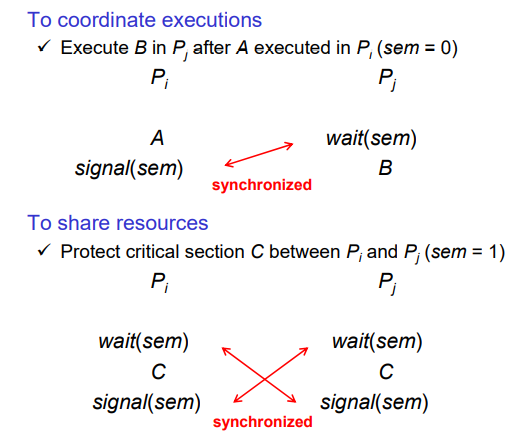
Signal과 wait의 동기화가 이뤄진다. 또한 critical section 보호도 가능하다.
Mutex Locks

어플리케이션 프로세스나 쓰레드가 사용할 수 있고 블락킹되는 lock이다. Critical section 앞에 lock, 빠져나올 때 unlock을 한다. Binary Semaphores와 동일하다.
Cf) spin lock은 운영체제가 사용한다. 따라서 Mutex locks와는 다르다.

Mutex lock을 사용해서 구현할 때에는 위와 같이 구현할 수 있다.
Semaphores의 구현
Integer 변수이기에 해당 값이 필요하다. 또한 해당 값이 0일 때 기다리는 프로세스가 있을 수 있기에 이를 저장할 프로세스 리스트를 만들어놓는다. 해당 리스트에 들어가면 프로세스가 wait 상태가 되어야한다.
운영체제 내부 코드
No busy waiting

wait에서는 lock을 한 뒤 값을 하나 줄여주고, unlock을 한다. 이때 0이하이면 linked list에 들어가도록 설정해서 block되도록 한다.
Signal인 경우에는 lock을 건 뒤 value를 증가시키고, unlock을 한다. 이때 value의 값이 0보다 작다면 list에 있는 프로세스를 wakeup한다. Value의 값을 증가시키거나 감소시킬 때도 critical section이 되기에 이 사이에 운영체제에서 사용하는 lock, unlock을 한다. 따라서 여기서의 lock은 spinlock이나 disable하는 식으로 구현해야한다.
Busy waiting을 하면 안된다. 어플리케이션 프로세스와 쓰레드는 busy wait을 하면 cpu를 낭비하지 않도록 쓰레드는 wait 상태로 가서 semaphore가 사용 가능할 때까지 기다려야한다. 따라서 해당 오퍼레이션 라이브러리 함수가 wait이 되고, 다 쓰고 반납하는 상황에서는 반납을 기다리는 프로세스에게 신호를 보내는 의미로 signal이라 한다.
변수를 빼는 작업은 사실상 어셈블리어에서는 3개의 명령어로 구성이 된다. 따라서 명령어를 수행하다가 context switching이 발생할 수 있다는 문제가 있다. 이를 보호하기 위해 운영체제의 lock, unlock을 해준다. 따라서 해당 코드에서는 spinlock이나 disable interrupt 등으로 구현할 수 있어야한다.
사실상 semaphore와 mutex lock과 동일하다.
Deadlock
Lock이 죽어서 영원히 풀리지 않는 상황이다.

초기에는 세마포를 1로 초기화했다. 처음에는 P0가 S를 wait하기에 S의 세마포를 1을 감소시킨다. 이후 interrupt가 걸려서 P1이 실행되고, Q의 세마포를 1 감소시킨다. P1도 interrupt가 걸려서 기다리고 있을 때 P0이 실행되면 Q의 값이 없기에 wait을 해야한다. 이후에 ready에 있는 P0이 실행되는데 이때 Q가 0이기에 wait된다. 따라서 P1이 실행되는데 이 또한 wait이 된다. 이는 영영 깨어날 수 없는 상태가 된다. 이는 크리티컬 섹션을 보호하고자 mutex lock이나 세마포를 잘못 쓰면 발생할 수 있다.
Starvation(indefinite blocking)
큐에서 스케줄링을 받고자 기다리지만 우선순위가 높은 프로세스가 계속 들어와서 영원히 어떤 프로세스나 쓰레드가 실행되지 않는 현상
세마포는 전역변수이거나 쉐어드 데이터가 된다. 이를 접근하는 오퍼레이션이 wait과 signal이다. 이는 전역변수로 지정하기에 문제가 발생할 여지가 있다. 하지만 어쩔 수 없이 전역변수로서 이를 사용해야한다. 어플리케이션 프로그래머가 데드락을 만들 수 있으니 프로그래밍 랭귀지가 이를 방지하도록 만들었다. Critical region과 monitor가 그 예시이다. 둘은 유사하다.
Monitors

모니터는 프로그래밍 랭귀지에서 critical section을 보호하도록 한다. Shared data를 선언하고 이에 대한 함수를 따로 정의하면 프로그램에서 함수가 동시에 들어가지 못하도록 mutual exclusion을 지원하는 방안이다.

Shared 변수를 선언하고, 그에 대한 함수를 정의한다. 어떤 함수가 이를 사용하면 다른 함수는 이를 사용하지 못하도록 보호한다. 컴파일러가 각 함수 마다 규칙대로 wait, signal을 넣어준다. 이는 자바에서만 지원하고 다른 프로그래밍 랭귀지에서는 지원하지 않는다. 다른 언어의 경우에는 Semaphore나 Mutex lock을 사용해야한다.
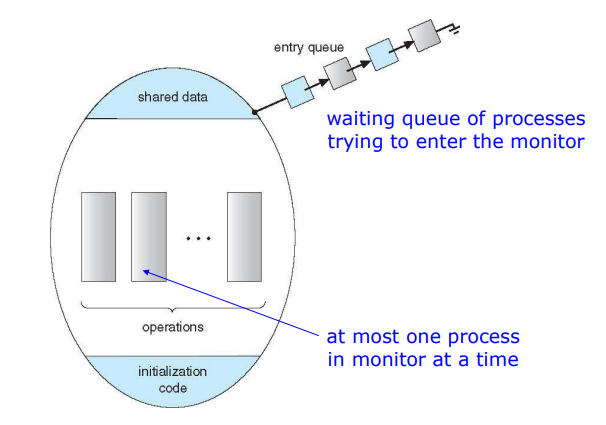
하나의 모니터에서 shared data를 선언하고, 이를 접근하는 함수를 선언했다. 이 중 하나의 쓰레드만 이를 처리하도록 하고, 다른 함수가 접근하면 큐에 넣어서 이를 사용하도록 해야한다. 이때 함수 내에서 무언가 기다리는 동작이 있을 수 있는데 이때에는 condition variable을 사용한다.
Condition variables

X라는 컨디션 변수에 wait을 하거나 signal을 보낸다.
Monitor with condition variables
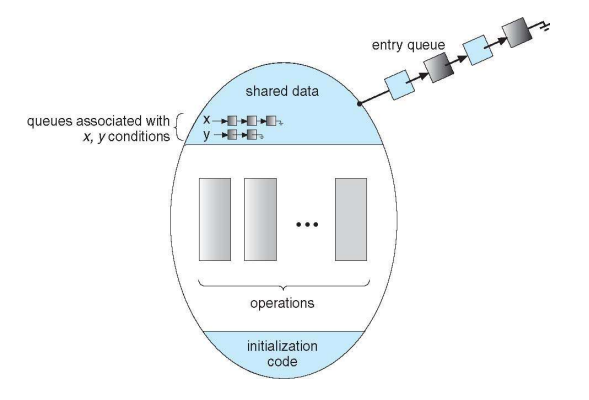
이벤트가 발생하기를 기다리다가 condition variable x를 만들고, 이를 기다리도록 만든다. 내부에 오퍼레이션을 수행하는 함수가 없다면 큐에 있는 내용이 들어와서 오퍼레이션을 수행한다. 만약 x라는 컨디션 베리어블이 signal을 보내주면 x에 매달려있는 메서드가 수행된다.
Monitor 구간을 만들고, 모니터링 해야할 shared data를 만들고, 모니터 내에는 한번에 하나의 프로세스만 수행될 수 있다. 이때 어떤 이벤트를 기다리는지 condition variable을 두고 처리한다. 이때 해당 변수에 대해 이벤트가 발생하면 signal을 보내는 식으로 동작해서 이를 처리한다.
세마포는 양수, 음수의 개념이 있지만 condition variable에서의 wait, signal은 양수, 음수의 개념이 없다. 단순히 기다리는 프로세스를 처리한다.
랑데부
동기화 포인트로서 해당 시점에서 이벤트가 발생하면 동기화가 이뤄지는 부분을 의미한다.
모니터와 세마포
모니터와 세마포 둘 다 동기화 툴이다. 어플리케이션 프로세스나 쓰레드가 사용한다. 세마포는 integer 변수이고, wait, signal의 오퍼레이션이 atomic이다. 하지만 데드락의 문제가 있을 수 있기에 monitor를 사용한다. monitor에서는 condition variable을 사용해 거기에서 wait, signal을 한다.
세마포에서의 아무것도 기다리지 않아도 signal을 보내면 값이 증가한다. Ex) -1 -> 0, 이에 따라 다른 프로세스가 처리될 수 있도록 한다. 반면 condition variable에서 아무것도 기다리지 않을 때 signal을 하면 아무것도 동작하지 않는다.

2 ~ 5번은 high level mechanism으로 어플리케이션이 사용하는 방법이고, 1번은 low level mechanism이기에 커널이 사용하는 방법이다. 이는 OS에서 2 ~ 5번을 만들기 위한 방법이다.
퀴즈 리뷰 및 질의 응답
딥러닝을 돌리는 것은 CPU를 매우 많이 사용하기에 CPU bounded process이다. 실행 중인 쓰레드를 중단시키고 다른 쓰레드를 실행시킬 수 있도록 하는 스케줄링이 Preemptive 스케줄링이다. non-preemptive 스케줄링은 실행 중인 쓰레드가 waiting일 때 동작한다.
모든 스케줄링에 대해 처음으로 고려하는 것은 FCFS이다. 이 알고리즘이 가장 공정하기 때문이다. 모든 시스템에서 고려해야하는 goal은 fairness이다.
round robin에서 time quantum이 커지는 경우에는 FCFS가 된다.
multiple process에서 특정 프로세스에서 사용 가능하도록 하는 것은 process affinity이다. 이렇게 사용하면 캐쉬 때문에 성능이 좋게 된다.
static priority
한번 주어진 우선순위를 가지고 실행하는 것, 대부분 이를 실행한다. task의 우선순위를 어떻게 할당하는 가가 중요하다. rate monotonic algorithm을 사용한다. 이는 주기를 가지고 동작한다. rate이 높은 순서대로 실행한다. RTOS에서 이를 사용한다.
dynamic priority
우선순위가 계속 바뀐다.
simulation 프로그래밍에서의 input을 지칭하는 말은 trace tape이다.
CFS의 약자는 Completely Fair Scheduling이다.
'강의 내용 정리 > 운영체제' 카테고리의 다른 글
| 운영체제(8), Deadlocks (1) | 2022.12.18 |
|---|---|
| 운영체제(7), Synchronization Examples (1) | 2022.12.18 |
| 운영체제(5), CPU Scheduling (0) | 2022.12.18 |
| 운영체제(4), Threads & Concurrency (1) | 2022.12.18 |
| 운영체제(3), Processes (1) | 2022.12.18 |