2022. 12. 18. 01:13ㆍ강의 내용 정리/운영체제
Threads & Concurrency
3장 내용 복습
Process: 프로그램을 실행하는 주체(단위)
프로그램은 하나지만 프로세스는 여러개일 수 있다. 예를 들어 HWP 프로그램은 하나지만 파일을 여러개 열고 있으면 프로세스가 여러개 사용될 수 있다. 구글의 크롬 브라우저는 Renderer, Plug in, Browser process가 존재해 브라우저를 열어준다. 운영체제가 이 프로세스를 관리하기 위해 PCB를 사용한다.
프로세스는 ready, running, waiting의 상태를 번갈아가며 실행된다. 레디 큐에 있는 프로세스를 선택하는 것을 스케줄링, 이를 cpu에 올리는 작업을 디스패치라 한다. 스케줄링과 디스패치를 하나의 큰 틀에서 스케줄링이라고 한다. 디스패치를 한다는 것은 cpu의 레지스터에 프로세스가 실행되던 상태의 값으로 복원하는 것을 의미한다. 프로세스가 번갈아가며 상태가 바뀌는 것을 Context Switching이라 한다.
지금 운영체제는 short term 스케줄링만 남아있다.
fork: 프로세스를 생성하는 시스템 콜로 이는 부모 자식관계가 된다.
exec: 파일을 파라미터로 받아서 파일을 실행하는 시스템 콜.
리눅스, 유닉스에서는 exec를 하기 위해 fork를 해야한다. 윈도우즈는 둘 다 CreateProcesses라는 시스템 콜을 통해 작업한다.
exit: 프로그램을 종료하는 시스템 콜
wait: 자식 프로세스가 종료하기를 기다리는 시스템 콜
IPC
IPC를 위한 Message passing / Shared memory의 특징과 장단점
Concurrency
cpu가 하나인 경우에 수행되어야하는 작업이 있다면 이를 돌아가면서 실행시켜주면 우리 눈에는 동시에 실행되는 것처럼 보인다. 이를 Concurrecy라고 한다.
cpu가 두개 이상인 경우에는 cpu의 개수만큼 작업을 수행한다. 이는 Parallel이라 한다.
Process
Heavy-weight

운영체제의 성능을 개선시키는 작업을 계속했다. 프로세스가 무겁기 때문에 이를 개선시키는 것이 운영체제의 성능 개선에서 주요한 요지였다.
예를 들어 웹서버가 TCP 커넥션을 하는 경우에는 각 프로세스마다 하나씩 연결을 해줘야했다. 차일드 프로세스가 만들어지는 경우에는 메모리도 할당하고, PCB도 채우는 등등의 동작을 해야했다. 하지만 수행되는 시간은 매우 짧은 경우도 많았다. 운영체제의 입장에선 매우 오버헤드가 많이 발생되는 작업이었다. 따라서 이를 효율적으로 만드는 것이 중요했다.
또한 interconnection 비용이 매우 비쌌다. 메세지 패싱과 같은 것은 운영체제로 데이터가 갔다가 다시 올라와야하기 때문이다.
따라서 위의 문제점들을 개선하기 위한 방법으로 쓰레드가 등장했다.
웹서버는 커넥션을 기다리다가 새로운 커넥션을 맺고, 프로세스를 만드는 작업을 진행했다. 하지만 사실 excution path(state)를 만들기 위해 프로세스를 만들었는데, 이는 오버헤드가 크기 때문에 이를 줄이기 위해 쓰레드가 등장했다.
SunOS에서 이를 먼저 제안했다. 그 당시의 이름은 Lightweight process였다가 그 이후에 thread of control이나 thread라는 용어를 사용했다.

각 쓰레드는 실행패스가 되어서 각각 반복해서 커넥션을 맺어주는 실행 path를 만들고, 요청을 처리해주는 실행 path를 만들어주는 식으로 동작했다. 하지만 이는 덩치가 매우 커지고 복잡해진다. 따라서 하나의 프로세스에 이런 실행 path를 여러개 만들어서 처리하는 쓰레드를 만들었다.

멀티쓰레드에서는 main, func1, func2 함수를 실행하는 쓰레드를 각각 만들어서 총 3개의 쓰레드가 사용된다. cpu가 하나라면 이는 concurrency가 된다. 따라서 thread를 만들기 위한 시스템 콜은 pthread_create이다.

싱글 쓰레드 프로세스는 코드, 데이터, file(ex) tcp connection), registers, stack(함수 호출에 대한 stack) 등등에 대해 모두 하나를 공유한다. 반면 멀티 쓰레드 환경에서는 실행 PATH별로 register나 stack은 각각 가지고 있고, 나머지는 모두 공유한다. 따라서 stack pointer나 중간 상태를 저장하는 레지스터도 따로 저장해야한다.
웹서버 예시

멀티 프로세스로 Concurrent Server를 구현한 코드 예시이다.
웹서버는 tcp connection이 맺어지길 기다리다가 연결이 되면 자식 프로세스를 만들어서 처리해준다.
동작 과정은 다음과 같다.

멀티프로세스

request를 하면 새로운 프로세스를 만들어서 클라이언트의 요청을 처리하도록 하고, 서버는 이를 다시 기다린다. 이를 프로세스를 통해 할 수 있고, 쓰레드를 사용해서도 할 수 있다.

처음 유닉스/리눅스 운영체제에서는 쓰레드가 없어서 프로세스로 할수밖에 없어졌다. 이후 윈도우가 등장했는데, 그 이후에는 프로세스로 하는 모델을 없애고(위의 모델) 아래의 모델처럼 사용하도록 했다. 따라서 윈도우즈는 위의 모델이 불가능하게 된다.
Using Threads

쓰레드를 만들 때 실행되는 함수는 handle_request이다.
이후 자기 자신은 루프를 돌아서 새롭게 기다린다.
멀티 프로세스인 경우에는 자식 프로세스일 때 DoCmd를 실행한다.
else는 부모 프로세스이기에 자식 프로세스가 끝나기를 기다린다.
싱글 프로세스와 멀티 프로세스는 모두 똑같게 보이지만 싱글 프로세스는 iteration으로 만든 것이다.
백그라운드를 할 경우에는 #if 1을 #if 0으로 바꿔주면 된다. 그러면 해당 코드를 생성하지 않기에 백그라운드로 루프가 반복된다.
#if, #endif는 컨디셔널 컴파일레이션이다.
멀티 쓰레드 버전
fork했던 부분을 pthread_create를 사용해주면된다. 이는 유닉스/리눅스가 사용하는 표준 시스템콜이다.
pthread_join은 쓰레드가 끝나기를 기다리는 함수이다.
Makefile
파일을 가져다가 make를 치면 실행파일이 나온다.
Multicore Programming

최근 등장한 멀티 코어에 대해 프로그래밍을 하는 방법이다.
single core는 concurrent하게 수행되는 것을 볼 수 있다.
core가 여러 개이기에 각각 Parallel하게 돌아간다. 이는 Task Parallel이다.
Data Parallel

각 코어별로 task는 동일하다. 하지만 동일한 연산에 대한 데이터가 달라진다.
data Parallel은 응용 프로그램에 디팬던트하다. 우리가 여태까지 작업한 것은 task 기반이다. 만약 처리해야하는 데이터가 많을 때는 data Parallel을 활용했다. 이전에는 일기예보, 운하의 움직임 등등 데이터가 많을 때의 계산에서나 이를 사용했다. 요즘에는 딥러닝을 data Parallel을 통해 처리한다. 행렬 곱셈 연산을 GPU를 이용해 매우 빠르게 동작하는데 이를 Parallel하게 동작한다.
우리가 여태 한 것은 flow 기반이기에 task parallel이다. 매우 빠르게 데이터를 처리해야하는 경우에는 Data parallel이다.
Parallel Programming

Pthreads
쓰레드를 여러개 만드는 task parallel이다.
그 이후에 있는 내용은 data parallel이다. 따라서 이는 어플리케이션 디펜던트하기 때문에 러프하게만 다루고 넘어간다. 최근에는 CUDA와 OpenCL가 많이 쓰인다. GPU는 그래픽 프로듀서였는데 이를 제너릭하게 사용하는 것이 CUDA, OpenCL이다.
Multithreading models

앞에는 응용프로그램, 뒤에는 커널 쓰레드를 의미한다.
many-to-one은 하나의 커널 쓰레드에 여러개의 쓰레드를 구현한다. 요즘 운영체제에서는 지원하지 않는다.
Many-to-Many는 SunOS나 솔라리스 등 유닉스 운영체제에서 이를 지원한다. 이는 M:N 식으로 사용한다. 이전에 쓰레드가 없던 상황에서 만든 것이다.
One-to-one은 윈도우즈 모델이 이에 해당한다. 각 응용프로그램마다 쓰레드를 연결한다. 윈도우즈는 쓰레드 하나 당 커널을 하나씩 매핑한다.
user thread와 kernel thread
user thread
지금은 user thread는 없고 모두 kernel thread만 사용한다. thread를 구현할 때 운영체제에 구현하는 것보단 어플리케이션에서 이를 구현하는 것이 더 간단하다. 어플리케이션에서 thread를 구현하는 라이브러리를 만들어서 구현할 수 있도록 하는 쓰레드이다.
kernel thread
현재는 커널 Thread만 사용한다.
POSIX의 쓰레드관련 시스템 콜
POSIX(Potable Operating System Interface)로 유닉스의 표준을 의미한다. 솔라리스나 Mach와 같이 다양한 유닉스가 존재한다. 즉, 회사마다 유닉스가 있다. 하지만 한 유닉스에서 만든 프로그램을 다른 유닉스에서 컴파일을 할 수 없다. 각 유닉스에서 서로 지원하는 시스템콜이 다르기 때문이다. 이에 따라 시스템콜 표준을 만들어서 사용한다. 이는 IEEE 단체에서 만든 표준이다. 쓰레드는 이후에 만들어진 개념이기에 POSIX가 이를 정할 수 있었다.
유닉스/리눅스도 모두 POSIX 표준에 맞춰 이를 구현했다.

pthread_create: 쓰레드를 생성하는 시스템콜
pthread_exit: 쓰레드를 종료시키는 시스템콜
pthread_join: 쓰레드를 기다리는 시스템콜
mutex나 conditional은 싱크로나이제이션과 관련이 있다. 쓰레드를 만들 때에는 이 시스템콜들도 같이 사용해야한다.


윈도우즈 쓰레드

윈도우즈는 쓰레드가 있는 상황에서 만들었다.
자바에서 쓰레드 생성하기

자바에서는 프로세스가 하나밖에 없기에 쓰레드를 여러개 생성해서 사용해야한다.
Thread 클래스를 상속받아서 run 함수를 오버라이드한다.
runnable 인터페이스를 구현한다.
Thread Design Space
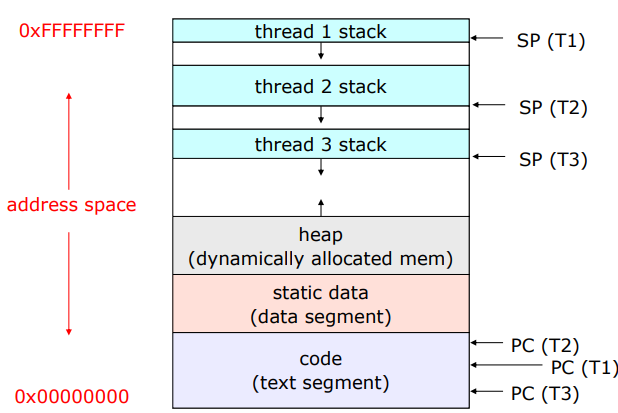
address space: memory address space
꼬불이는 실행 path를 의미한다.

도스에서는 쓰레드/프로세스가 하나밖에 없었다.
과거 유닉스에서는 멀티프로세스이지만 쓰레드가 하나였다.
지금은 멀티 쓰레드, 멀티 프로세스이다. 윈도우즈 NT 이후에 멀티 쓰레드가 등장했다.
자바에서는 자바 가상머신이 쓰레드를 실행시키는 것이기에 프로세스가 하나이다.
퀴즈 리뷰
프로세스가 스스로 실행될 수 없는 상태인 경우에는 waiting 상태가 된다. 이는 스케줄링 대상이 아니게 된다. ready 상태에서 대기중인 프로그램만 스케줄링을 기다리게 된다. running을 하다가 interrupt가 발생하면 interrupt 핸들러가 수행되고나서 운영체제가 수행된다. 이에 따라 프로그램은 중단되기에 ready로 간다. 운영체제가 다 동작한 뒤, 레디 큐에 있는 프로그램 중 하나를 가져온다. 레디큐에 프로그램이 없는 경우에는 idle 프로세스가 돌아간다.
가장 밑에 코드 세그먼트(cpu 명령어가 들어가있다.) 데이터 세그먼트(전역변수, static 변수가 포함되어있다.), 힙(동적으로 생성되는 변수가 들어가있다.), 스택(지역 변수가 들어가있다.)
context switching: cpu의 context를 switch한다. 운영체제가 수행하는 cpu 관리이다.
유닉스/리눅스에서 프로세스를 생성하는 시스템콜: fork
유닉스/리눅스에서 프로세스를 실행하는 시스템콜: exec
윈도우즈에서 프로세스를 생성하고 실행하는 시스템콜: CreateProcesses
cf) 유닉스/리눅스의 시스템콜이 동일한 이유는 POSIX 표준을 따랐기 때문이다.
IPC의 약자: Inter Process Communication
장단점! 중요
Message Passing: 커널이 중재해준다. -> 두 프로세스의 동기화 작업이 필요없다.
Shared Memory: 두 개의 프로세스가 참조할 수 있는 메모리를 만드는 것은 커널이 만들지만 그 이후의 IPC는 두 프로세스가 알아서 한다. 이는 동기화 작업이 필요하다.
RPC의 약자: Remote Proc Call
자바의 RPC의 약자
'강의 내용 정리 > 운영체제' 카테고리의 다른 글
| 운영체제(6), Synchronization Tools (0) | 2022.12.18 |
|---|---|
| 운영체제(5), CPU Scheduling (0) | 2022.12.18 |
| 운영체제(3), Processes (1) | 2022.12.18 |
| 운영체제(2), Operating System Structures (0) | 2022.12.18 |
| 운영체제(1), Introduction (0) | 2022.09.20 |