2022. 12. 14. 20:36ㆍ강의 내용 정리/데이터베이스
물리적 데이터베이스 설계
물리적 데이터 베이스 설계란?

1. 보조 기억 장치

블록은 저장 장치와 메인 메모리 사이에서 데이터를 주고받는 단위를 의미한다.
전형적인 블록 크기는 시대에 따라 달라진다. 최근에는 4kb, 16kb, 32kb를 사용하기도 한다.
cf) 캐릭터 장치(문자 장치): 이는 한문자마다 데이터를 전송하는 장치를 의미한다. 대표적으로 키보드가 있다.
저장 장치의 계층 구조

cpu는 디스크에 있는 데이터를 직접 쓰거나 읽을 수 없다. 디스크에 있는 블럭 단위의 데이터를 주기억 장치와 주고받는 식으로 진행한다. 따라서 read, update, write하는 순서로 데이터를 작성한다.
백업을 위해선 싼 가격의 저장 장치인 자기테이프를 사용해 이를 저장한다.
자기디스크

자기 물질: 마그네틱 물질
트랙은 여러개의 섹터로 나눠져있다.

원판을 platter라고 부른다. 자기 물질의 N극과 S극을 바꿈으로서 비트를 표현한다.
spindle은 회전축을 의미한다.
실린더는 서로 다른 면에 있는 같은 지름의 트랙들을 모은 것을 의미한다.
arm assembly가 안쪽, 바깥쪽으로 이동하며 섹터를 읽는다. 이때 모든 헤드는 함께 이동하게 된다.
이때 arm assembly가 이동하는 것을 seek라고 한다. 윈이 회전해서 head 밑으로 올 때까지 이동할 때 rotational delay라고 한다. 이후 읽은 데이터를 전송하는 시간인 전송 시간이 발생하게 된다.
실질적으로 데이터를 저장하는 영역은 트랙이라하는 동심원이 된다.
seek 타임이 가장 오래걸리기 때문에 실린더는 중요하다. 만약 arm assembly의 이동이 없더라도 읽을 수 있는 섹터들인 경우 굉장히 많은 시간을 단축할 수 있다. 이에 따라 저장장치를 효율적으로 저장하기 위해서는 가능하면 함께 엑세스되는 데이터는 같은 섹터 > 트랙 > 실린더 순으로 저장하는 것이 중요해진다.
ex) 7200RPM이면 1분에 7200번 회전한다는 의미이다. 따라서 회전속도, 전송속도는 매우 빠르기에 seek time이 가장 오래걸린다.
로테이션 딜레이는 평균적으로 1/2 회전 속도만큼 소요된다.
2. 버퍼 관리와 운영체제

버퍼는 디스크에 한번 읽어온 데이터가 다음에 다시 읽을 가능성이 높기에 이를 주기억 장치 상의 버퍼라는 공간에 두게 된다. 이 때문에 디스크의 엑세스 없이 다시 데이터를 불러올 수 있다는 장점이 있다.
버퍼가 꽉 차게되면 버퍼 교체가 필요하게 된다. 따라서 버퍼 교체 정책이 등장하게 된다. LRU 알고리즘이 가장 많이 사용된다. Least Recently Used의 약자로 가장 오래전에 엑세스된 것을 쫒아낸다.
버퍼 관리의 예시
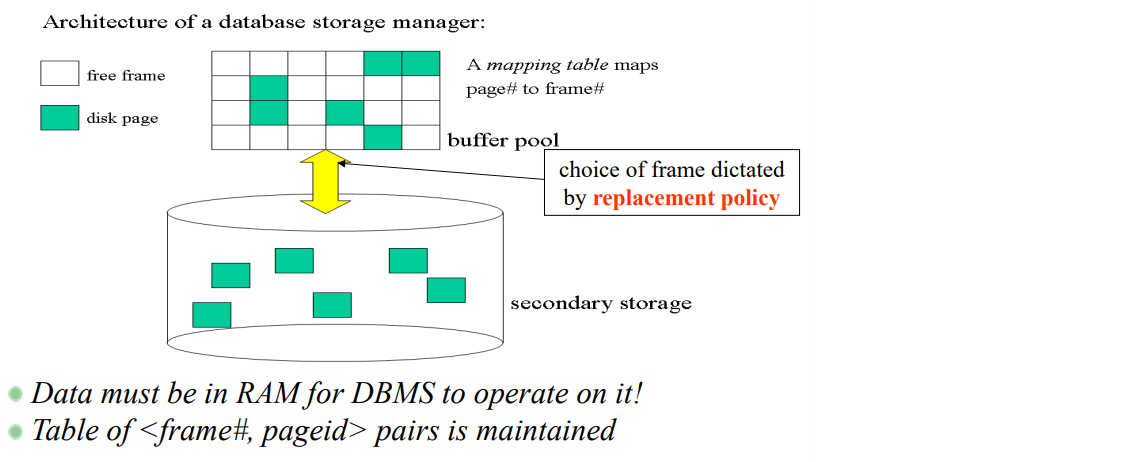
block = page로 고려하면 된다.
cf) 엄밀히 얘기하면 메인메모리 상에서 블록을 담는 공간을 페이지라 부른다.
프레임 넘버와 페이지 아이디를 저장하는 버퍼 테이블이 있어서 이를 매핑하는 역할을 한다.
3. 디스크 상에서 화일 레코드 배치

고정길이: float, int 등이 될 수 있다.
가변길이: varchar와 같은 문자열이 될 수 있다.

파일 헤더: 파일에 대한 메터정보를 가지고 있는 것
각 블럭에는 블럭 관리를 위한 블럭 헤더를 가질 수 있다.
각 블럭에는 레코드들이 포함되어있다. 레코드는 연관된 필드의 모임으로 이뤄져있다.
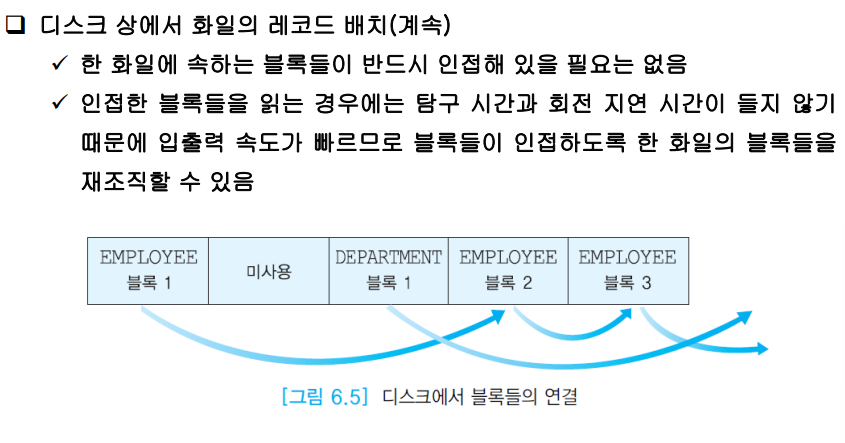
한 화일에 속하는 블록을 인접하도록 만드는 것이 속도 향상에 중요하다.
블럭 내의 링크드리스트를 통해 연결하여 이를 표현할 수도 있고, page map을 통해 블럭의 아이디를 배열 형태로 이를 가지고 있을 수도 있다.

작은 크기의 레코드는 수월하게 저장할 수 있다. 그러나 이미지, 동영상 등의 대규모 크기의 특수한 형태의 필드는 BLOB을 사용한다.
채우기 인수((fill factor), block(page) fill factor)는 레코드를 저장하는 영역이 몇 퍼센트인지 지정하는 것이다. 초기에 파일을 만들려고 할 때 블럭을 얼만큼 비워두고 만들건지 정하는 역할을 한다. 나중에 동적으로 데이터를 삽입할 때를 대비해 채우기 인수를 설정한다.
고정 길이 레코드

주기억장치에서 배열에 클래스 객체를 저장하는 것과 비슷하다.
첫번째 래코드의 위치는 0, 두번째 레코드는 n, 세번째 레코드는 2n이 된다.

레코드를 삭제하는 경우에는 뒤쪽에 있는 레코드를 앞쪽으로 하나씩 당기는 방법이 있다. 하지만 이 경우에는 움직여야하는 레코드의 개수가 많기에 가장 마지막의 레코드를 앞으로 옮겨서 사용할 수 있다.
첫번째 방법은 레코드의 순서를 그대로 유지되지만 두번째 방법은 순서를 유지할 수 없다.
DBMS에서는 실질적으로 위의 두 가지 방법을 사용하지 않고, 지연 관리 방법을 사용한다. free list를 통해 삭제된 공간을 관리한다.
파일 내의 클러스터링

가장 마지막 어트리뷰트가 부서 번호인 경우에는 부서 번호가 동일한 경우에 하나의 블록에 모아놓으면 처리가 빠르다. 이렇게 관련 있는 것을 모아두는 것을 클러스터링이라 한다.

inter-file clustering
여러 릴레이션이 관여되었을 때의 클러스터링을 의미한다.
사원과 부서 레코드들이 함께 엑세스되는 것은 어떤 것이 있는지 확인하여 서로 다른 릴레이션의 레코드들을 같은 블럭에 두는 것을 화일 간의 클러스터링이라 한다.
4. 화일 조직
data(record)들을 어떻게 저장할 것인가에 대한 data file structure
1) 화일 조직의 유형
(1) 히프 화일(heap file)
(2) 순차 화일(sequential file)
(3) 인덱스된 순차 화일(indexed sequetial file)
(4) 직접 화일(hash file)
2) 히프 화일

비순서 화일로 가장 단순한 화일이다.
찾고자 하는 레코드가 있다면 순차검색을 해야한다.
삭제된 레코드가 차지하던 공간을 재사용하지 않는다는 것은 영원히 사용하지 않을 수도 있고, free list를 통해 사용할수도 있다. 따라서 만약 삽입/삭제가 많은 경우에는 주기적으로 사용하지 않는 공간을 처리(주기적 재조직)해줄 수 있다.

(2) 히프 화일의 성능

모든 레코드를 검색하는 질의인 경우에는 SQL에선 어차피 순서가 중요하지 않기 때문에 읽은 순서대로 화면에 출력해줄 수 있다. 따라서 모든 레코드를 검색하는 경우에는 무난한 성능을 보인다.
특정 레코드를 검색하는 경우에는 순차적으로 검색을 해야하기에 평균적으로 n/2개를 확인해야한다. 따라서 성능이 나쁘다는 것을 알 수 있다.
예시

블록킹 인수: blocking factor = 블록크기 / 레코드 크기 = 블록 내 레코드 수

몇 개의 레코드들을 검색하는 경우에도 비효율적이다. 화일에 있는 블럭을 모두 읽어야지 조건문에 해당하는 값들의 처리가 가능할 것이기에 매우 비효율적이다.
cf) DNO = 2 -> 점 질의, SALARY >= 30 AND SALARY <= 40 -> 범위 질의

삽입은 빠르지만 나머지 연산에는 매우 오랜 시간이 걸리는 파일 구조이다.
3) 순차 파일

순서를 결정 짓는 키가 탐색 키이다.
삽입을 할 때에는 현재 저장되어있는 레코드를 보고, 삽입될 위치를 찾은 뒤 그 위치 중간에 끼워넣는다. 따라서 공간 확보를 추가적으로 해야할 수 있다.
삭제를 할 때에는 사용하던 공간을 빈 공간으로 남겨서 히프 화일과 마찬가지로 주기적 재조직이 필요하다.
일반적으로 데이터베이스에서는 사용되지 않지만 기본 인덱스와 데이터 파일이 세트로 이뤄진 경우에는 사용될 수 있다.
ex) 사원번호를 인덱스로 만들면 사원 번호에 대한 순차 파일을 유지하는 것은 자주 사용된다.

정렬되어서 저장된다.

사원번호로 정렬했기에 그 번호에 대해서는 이진 탐색이 가능하다. 하지만 그 외의 키를 검색하는 경우에는 모두 탐색해야한다.

데이터 삽입에 시간이 매우 많이 소요된다. 따라서 순차 화일은 자주 사용되지 않는다.

관심의 대상이 블록이기에 블록의 개수를 가지고 탐색한다.
5. 단일 단계 인덱스
특정 파일을 빠르게 찾기 위해 도입된 구조가 인덱스이다.

탐색 키와 레코드에 대한 포인터 쌍을 별도로 저장하여 이를 정렬하고, 이 위치에서 이진탐색을 한다.

인덱스 화일, 데이터 화일로 구분할 수 있다.
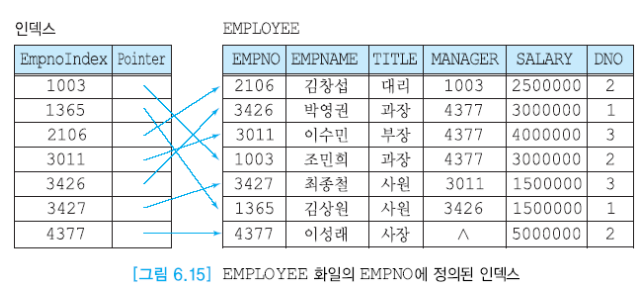
인덱스 화일의 크기가 더 작다.

탐색키는 관계 데이터 모델의 키를 의미하는 것이 아니기에 중복된 값이 있을 수 있다.
2) 기본 인덱스

탐색 키가 primary key인 경우에는 기본 인덱스라 한다. 기본 키 값에 따라 데이터 화일은 정렬된다.

인덱스 블록은 각 데이터 블록의 첫번째 인덱스만 가지고 있다. 이러한 경우에는 희소 인덱스라고 한다. 데이터 화일이 순차 화일인 경우에 해당한다. 데이터를 삽입하면 데이터 블록이 분할되어서 인덱스가 연결된다.
ex) 55의 값을 찾기 위해선 50인덱스의 블록으로 가서 55 사원번호를 찾는다.
cf) 밀집 인덱스: 모든 어트리뷰트에 대한 탐색키가 있다. 이는 레코드 포인터를 사용한다. 희소 인덱스에서는 블록을 가리키기에 블록 포인터를 사용한다.

레코드 포인터는 블록 포인터 + 레코드 번호로 표현될 수도 있다. 따라서 더 많은 데이터가 소모된다. + 1을 하는 것은 데이터 블록의 access를 의미한다.
3) 클러스터링 인덱스


디스크 엑세스 시간을 줄일 수 있다. 물리적으로 저장하는 공간도 유사하게 만드는 것처럼

비 클러스터링 인덱스의 경우에는 박씨부터 이씨까지 탐색할 때 여러 블럭을 탐색해야하기에 seek time이 매우 많이 소요된다. 따라서 비효율적이게 된다.

어떤 범위를 탐색할 때 하나의 블록에 다 데이터가 있다고 가정했을 때 위의 탐색시간이 나온다. 다른 블록도 찾게되면 추가적인 시간이 소요된다. 즉, 범위 질의를 할 때 탐색 시간을 줄여준다.
4) 보조 인덱스

블럭의 개수가 많아지기에 인덱스에 대해 이진 탐색을 할 때 접근 횟수가 증가하게 된다.

기본키는 ordered이거나 unordered일 수 있다.
레코드 하나당 인덱스 엔트리 하나가 나온다.
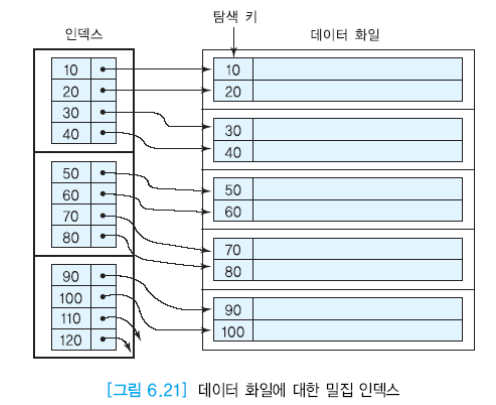
정렬이 되어있는 경우에도 밀집 인덱스를 가지고 이를 처리할 수 있다. 하지만 불필요하게 레코드가 필요하게 된다.

밀집 인덱스를 사용하면 엑세스를 할 때 시간이 더 오래걸릴 수 있다.
희소 인덱스와 밀집 인덱스의 비교

아래의 부분은 다단계 인덱스에 해당하는 내용이다.

희소 인덱스가 일반적으로는 좋지만 데이터 엑세스가 아니라 인덱스를 통해 값을 처리하는 경우에는 밀집 인덱스가 더 좋을 수 있다.
ex) SELECT COUNT(DISTINCT Ename) FROM EMPLOYEES;

cf) Keyed Access?
6. 다단계 인덱스

인덱스의 크기가 너무 커지는 경우에는 이진 탐색을 하더라도 접근 횟수가 늘어나기에 인덱스에 대한 인덱스를 만들어서 사용한다. 인덱스의 블록이 하나만 될 때까지 이를 만든다. 이때 마지막 블록이 마스터 인덱스가 된다.

인덱스에서 블록은 각 레벨에서 하나씩 엑세스한다.
1단계 인덱스 엔트리의 개수가 N이라 할 때, 다단계 인덱스의 개수는 logN이 된다. 이때 밑은 인덱스 블록킹의 인수가 된다. 이에 따라 log 밑의 개수가 2보다 크기 때문에 이는 더 빠르게 처리할 수 있다.

전체 인덱스 블록의 개수는 2942 + 18 + 1이 된다.
(3+1) x 10ms인데 마스터 인덱스(블록)은 자주 엑세스가 되기에 버퍼에 항상 존재한다고 가정하면 마스터 인덱스 블록은 디스크 엑세스를 할 필요가 없어서 이는 (2+1) x 10ms로 줄일 수 있다.
하지만 시험 문제에서 나올 경우에는 그냥 인덱스의 개수 + 디스크 접근 횟수(1)를 더해서 계산하자.
인덱스 정의문

인덱스를 사용하지 않아도 자동으로 인덱스를 만드는 경우가 있다. create table에서 primary key나 unique constrant를 주면 자동으로 인덱스를 만들게 된다.
Primary key를 사용하여 기본인덱스를 생성하면 레코드들의 순서도 변경된다. primary key를 사용하면 자주 사용되기 때문에 인덱스가 있다면 쉽게 엑세스를 할 수 있게 된다.
unique를 사용하면 보조인덱스가 만들어진다. 인덱스가 없다면 unique를 판단하기 위해 모든 데이터를 하나씩 체크해야하지만 보조 인덱스가 있다면 더 빠르게 데이터가 있는지 판단할 수 있다.
cf) B+ tree: 시간이 흐름에 따라 튜플을 삽입/삭제할 때 효율적으로 동작할 수 있도록 된 tree 구조
cf) index: tree structured index, hash index가 있다.

CREATE INDEX "인덱스이름" ON "릴레이션이름" (인덱스 구축에 사용되는 어트리뷰트 리스트)
위와 같이 어트리뷰트 리스트를 인덱스 구축에 사용할 경우에는 두 어트리뷰트의 순서가 중요하다.
DNO부터 먼저 index의 우선순위를 가진다.
위의 질의는 점 질의(point query)가 된다.

위의 질의는 범위 질의(range query)이다. 이 경우에는 lower key value부터 먼저 탐색한다. 이에 따라 (2, 3000000)을 먼저 찾게 된다. (DNO=2, SALARY=3000000), 범위에 속한 키 값을 액세스할 때까지 계속 진행한다. upper key value까지 이를 찾는다. (3, 4000000)
- DNO의 경우에는 점질의나 범위 질의에 대해 탐색할 수 있지만 SALARY는 점질의나 범위 질의에 대해 탐색할 수 없다. 왜냐하면 DNO, SALARY 순으로 정렬이 되어있기 때문에 DNO의 값에 대해서만 조건을 처리할 수 있다.
즉, 인덱스 구축에 사용되는 어트리뷰트 리스트의 순서대로 where 절에서 조건을 준다면 이를 처리할 수 있게 된다.
ex) a1, a2, a3, a4를 인덱스 구축에 사용 -> a1 ~, a2 ~를 통한 질의는 가능 // a1 ~ , a3 ~ 는 불가능하다.
인덱스의 장점과 단점

튜플을 삽입하면 각 인덱스에 key와 id를 삽입하게 된다. 따라서 인덱스를 늘리게 되면 삽입, 삭제, 수정에 대한 속도도 저하된다. 최근에는 저장소에 대한 가격이 많이 적어졌기에 속도가 줄어드는 것이 더 큰 문제이다.
성별을 기준으로 인덱스를 나누는 것은 의미가 없기에 튜플 중 일부를 검색하는 것을 인덱스로 선택하는 것이 중요하다.
7. 인덱스의 선정 지침과 데이터베이스 튜닝

중요한 질의: 직급이 높은 사원이 검색하는 질의나 매출에 영향을 미치는 질의 등
수행 빈도: 얼마나 수행되는지 등등
위의 특징은 read에서 중요하다. 또한 위의 질의 등등에 대한 requirement가 어떤지를 고려해야한다.
워크로드: 사용되는 질의와 빈도를 모아 놓은 것
선별력: 선택된 튜플 수 / 전체 튜플 수 -> 수치는 작을수록 선별력은 높다고 표현한다.
ex) 부서가 10개인데, 1개를 선택하면 1/10

중요 질의를 차례로 고려하고, 어떤 어트리뷰트에 어떤 인덱스를 사용할 것인지 고려하고, 질의 성능을 올릴 수 있는 인덱스가 어떤 것이 있는지 등을 찾아본다.
즉, 한 인덱스를 추가할 때 기존 인덱스와의 중복이 높다면 질의 성능이 그리 올라가지 않기에, 이러한 부분도 고려해야한다.
ex) 부서번호 / 부서번호와 직급 / 이름 순으로 질의가 중요하다. 이때 부서 번호를 인덱스로 만들고, 이름을 인덱스로 만드는 것이 더 유리할 수 있다. 부서번호 인덱스가 이미 있기에 부서번호와 직급의 인덱스 생성 기회비용이 더 높을 수 있기 때문이다.
효용성 추정이 잘못되거나 워크로드가 변경되는 경우에는 이에 맞춰 물리적 데이터베이스 설계를 다시 해야한다.
인덱스를 결정하는데 도움이 되는 몇가지 지침

기본키에 대한 클러스터링 인덱스와 기본키가 아닌 것에 대한 클러스터링 인덱스가 있는데, 대부분 기본키에 대한 클러스터링 인덱스를 사용한다.
지침 3: 이름이 이의 예시가 된다.
지침 4: 선별력이 어느정도 있어야 인덱스를 만드는 것이 유의미하다.
지침 5: 튜플이 계속 삽입/삭제/수정된 경우에 인덱스가 바뀌어야하기에 오버헤드가 커진다.
cf) 인덱스는 보통 update를 지원하지 않기에 delete -> insert를 해야한다.

지침 8: 선별력이 떨어지는 것은 인덱스로 만드는 것이 의미없다.
지침 9: 문자열 비교는 정수 비교에 비해 더 많은 오버헤드가 들어 이는 사용하지 않는 것이 좋다.
지침 11: 블럭 개수가 몇개 안될 때에는 인덱스를 통한 탐색이 더 많아질 수 있다.
지침 12: bulk update -> 백만개 튜플에다가 십만개 튜플을 추가하는 것보다는 백십만개의 데이터 파일을 따로 만들고 이에 대한 인덱스를 새롭게 구축하는 것이 더 빠를 수 있다.

위의 정도의 산술 연산자는 DBMS에 따라 가능하게 해주는데, 때때로 못쓸수도 있다.

질의 튜닝을 위한 추가 지침

- distinct를 하기 위해 전체 릴레이션에 있는 튜플 하나에 대해 중복값을 체크해야한다. 이에 따라 2중 루프를 돌아야한다. 혹은 정렬을 해서 이를 구할 수 있다.
- 그룹으로 나누는 것 또한 비용이 높다.
- 복잡한 질의를 처리하기 위해 임시 릴레이션을 사용하는 경우들이 있는데, 이는 바람직하지 않다. 임시 릴레이션을 만드는데 시간이 소요된다. 또한 DBMS가 제공하는 질의 최적화를 제대로 처리하지 못하기에 속도가 더 느려지게 된다. global optimal한 것을 찾지 못하게 되고, local optimal만 찾게 된다.
- 꼭 필요한 어트리뷰트를 지정하는 것이 좋고, 추후에 유지보수를 할 때 어떤 질의를 처리하고자 했는지 알기 어려워지기에 이를 나열하는 것이 좋다.
inverted index(역 색인): 중복된 인덱스를 표현하기 위해 사용되는 인덱스
'강의 내용 정리 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스(11), 함수적 종속성과 정규화 (0) | 2022.12.25 |
|---|---|
| 데이터베이스(10), 릴레이션 정규화 (0) | 2022.12.20 |
| 데이터베이스(8), 데이터베이스 설계와 ER 모델 (1) | 2022.12.13 |
| 데이터베이스(7), 내포된 SQL (0) | 2022.10.25 |
| 데이터 베이스(6), DML, 트리거와 주장 (0) | 2022.10.21 |