2022. 12. 20. 22:56ㆍ강의 내용 정리/데이터베이스
릴레이션 정규화
1. 정규화 개요

원래의 릴레이션에는 중복이 있기에 이를 작은 릴레이션으로 분할한다. 이때 함수적 종속성을 사용한다.
좋은 관계 데이터베이스 스키마를 설계하는 목적
정보가 중복되면 갱신이상이라는 주요한 문제가 발생한다.
어떤 시스템을 개발할 때에는 정확하게 구현하는 것부터 시작해서 퍼포먼스를 고려해야한다. 데이터 베이스 설계에서도 기능을 요구사항대로 구현할 수 있는지 따지고, 그 뒤 성능에 대해 고려한다.
갱신 이상(update anomaly)
(1) 수정 이상(modification anomaly)
(2) 삽입 이상(insertion anomaly)
(3) 삭제 이상(deletion anomaly)
회사의 방침이 바뀌어서 부서가 3개나 1개만 속할 수 있다고 하면 스키마를 바꿔야한다. 또한 저장공간의 소모는 더 커지게 된다.
정보의 중복으로 인해 갱신 이상이 발생하게 된다. 저장 공간의 낭비가 무척이나 많게 된다.
삽입 이상이 발생하는 이유: 부서는 사원 정보와 독립적이지만 이를 독립적으로 고려하지 않고 처리했기에 부서 정보를 입력할 수 없다. -> 부서 정보를 가지기 위해 불필요한 사원 정보를 삽입해야한다.
릴레이션 분해
나눠진 릴레이션으로 하나의 릴레이션으로 복원할 수 있다는 것을 기반한다. 복원을 할 수 있는 경우에는 분해를 해야한다.
실세계에서 독립적으로 존재하는 엔티티는 독립적으로 릴레이션을 만들어야한다.
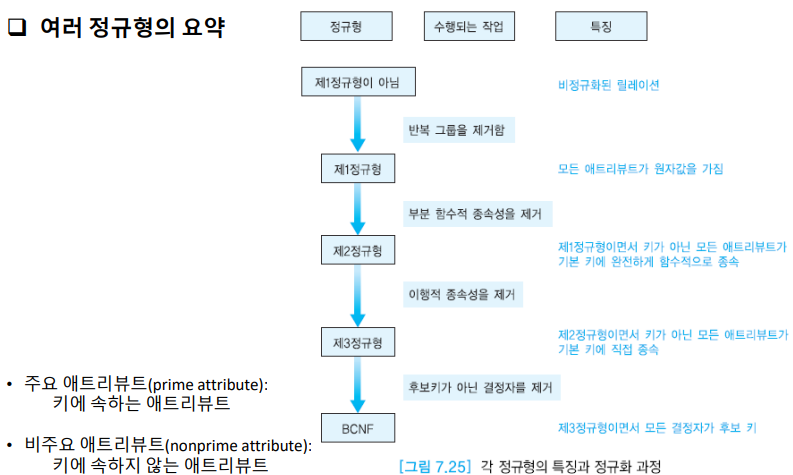
정규형의 종류

위로 갈수록 중복을 많이 제거한다.
제2정규형은 제1정규형을 포함한다. 즉, 하위의 정규형은 만족하게 된다.

지침 2: 1대1관계에서 어떻게 매핑하냐에 따라 널값이 달라진다.
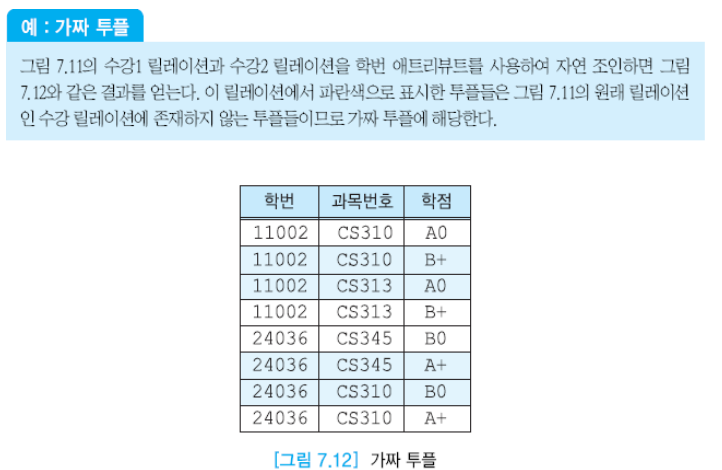
가짜 튜플: 분해를 했다가 조인하면 원 릴레이션과 동일하지 않고 새롭게 생기게 되는 튜플
2. 함수적 종속성
1) 함수적 종속성의 개요

앞으로 발생할 수 있는 모든 인스턴스에 적용된다.
결정자

키 값이 정해지면 다른 어트리뷰트의 값을 고유하게 결정할 수 있다.
결정자는 주어진 릴레이션에서 다른 어트리뷰트를 고유하게 결정할 수 있는 하나 이상의 어트리뷰트를 의미한다.
즉, 모든 릴레이션에 대해 정하는 것은 아니다.
위에서는 A가 결정자가 된다.
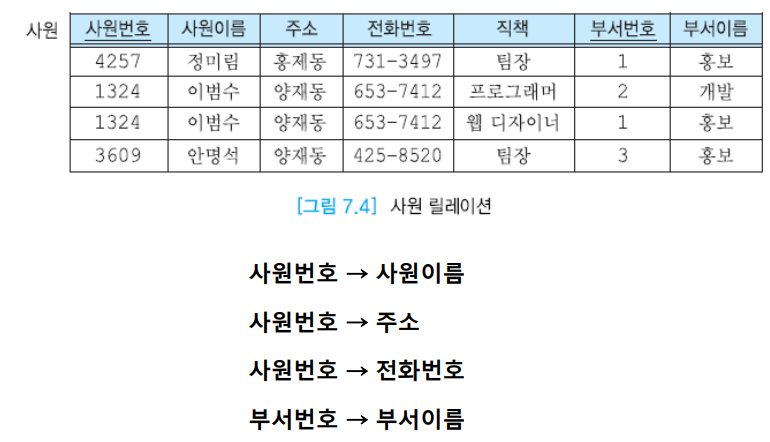
cf) 기본키는 주어진 모든 어트리뷰트를 결정할 수 있다. 결정자는 일부 어트리뷰트의 값을 고유하게 결정할 수 있는 것이다.
위에서는 기본키는 사원번호와 부서번호가 기본키이다.
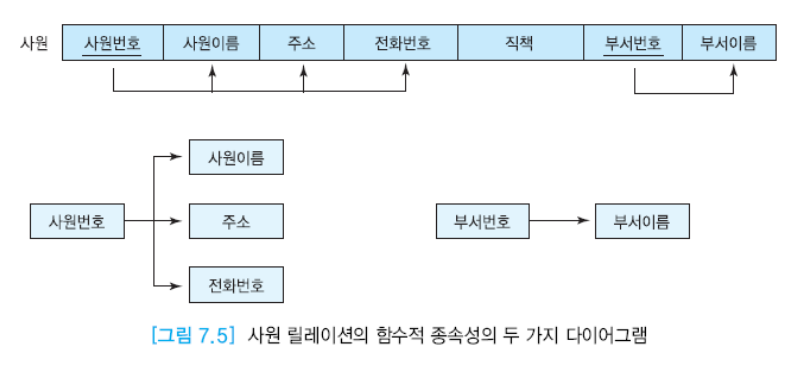
2) 함수적 종속성

A가 결정자 -> B는 함수적으로 종속한다고 얘기한다.
두 개 이상이 결정자인 경우에는 하나의 어트리뷰트에 대해 종속하지는 않는다.
3) 함수적 종속성의 종류
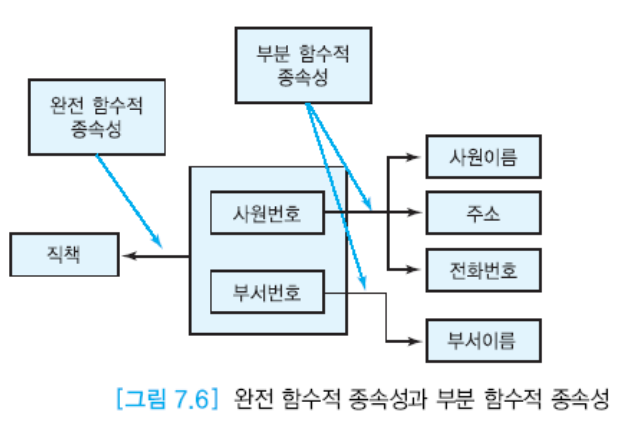
(1) 완전 함수적 종속성(FFD)

A의 진부분집합에 대해 함수적으로 종속하지 않으면 완전 함수적 종속성이라 한다.
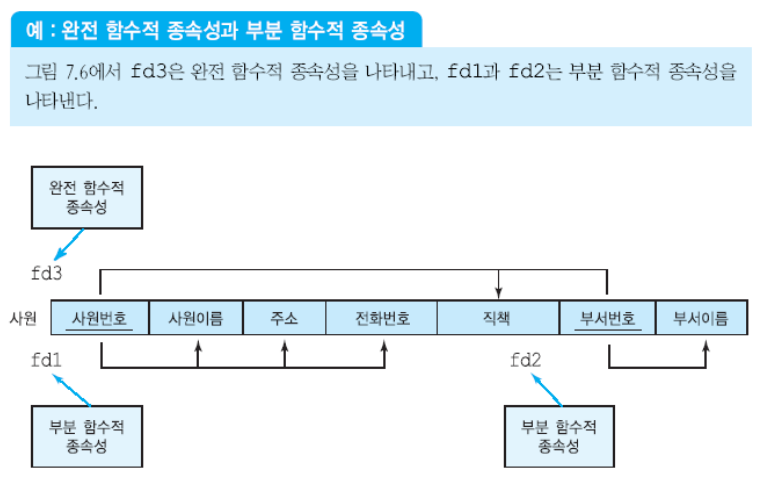
fd1: 사원번호 -> 사원이름, 주소, 전화번호
fd2: 부서번호 -> 부서이름
fd3: 사원번호, 부서번호 -> 직책
사원번호나 부서번호만으로 직책을 결정할 수 없다. 따라서 이는 완전 함수적 종속성을 의미한다.
사원번호, 부서번호 -> 사원이름, 주소, 전화번호, 직책, 부서번호, 부서이름이 가능 // 이때 사원 번호가 사원 이름을 결정할 수 있기에 이러한 경우에는 완전 함수적 종속성이 아니게 되고, 이는 부분 함수적 종속성이 된다.
(2) 이행 함수적 종속성

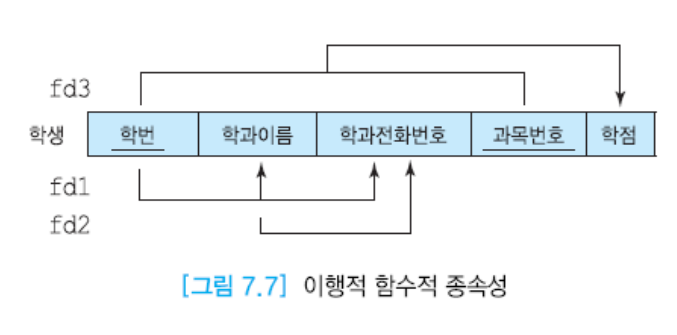
A->B이고 B->C이기에 A->C가 된다. 이러한 경우는 이행적 함수적 종속성이 된다.
3. 릴레이션의 분해

앞서 언급한 종속성 중에 바람직하지 않은 종속성이 있기에 이를 없애고자함
완전 함수적 종속성과 이행적 함수적 종속성이 이 예시가 된다. 완전 함수적 종속성의 경우에는 기본키에 대한 경우에만 이를 처리해야하지만 후보키에 대해서는 이러한 일이 나타나면 안된다.
조인은 오버헤드가 크기에 이러한 부분을 고려해야한다.
무손실 분해

정보에서의 손실은 가짜 정보가 들어가는 것도 포함한다. 가짜 튜플이 생기는 경우는 손실이다.
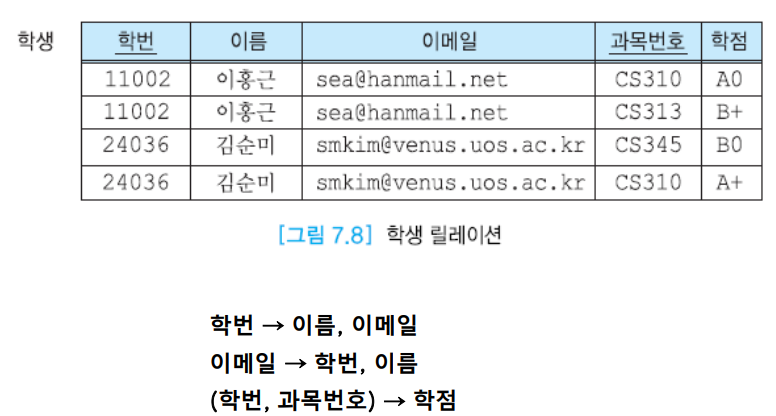
이름과 이메일이 중복적으로 나타난다.
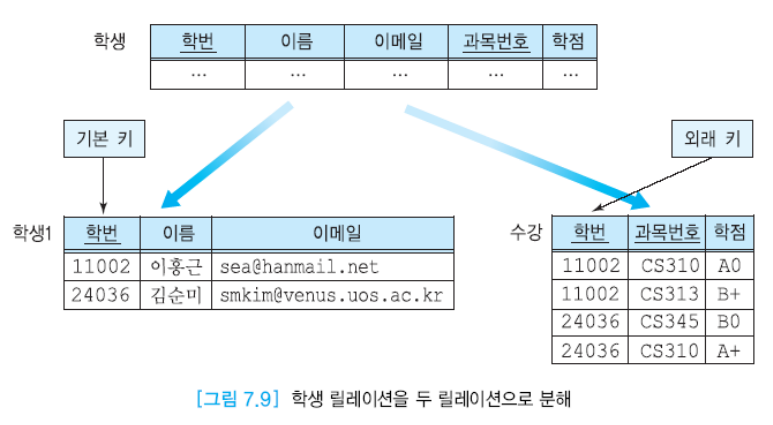
빠진 것도 없고, 가짜 튜플도 없기에 이는 무손실 분해가 된다.
외래키를 잘 사용해서 분해하면 원래 릴레이션을 만들어낼 수 있다.
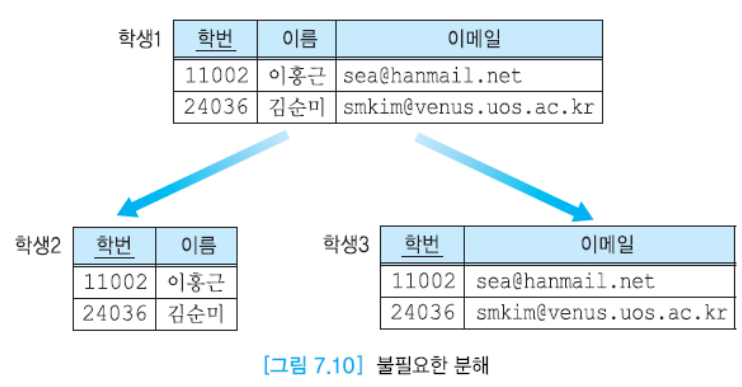
원래 릴레이션에 중복이 없기에 이를 나누는 것은 불필요하다. 조인을 처리해야하기에 불필요하게 조인이 많이 일어나기 때문이다.
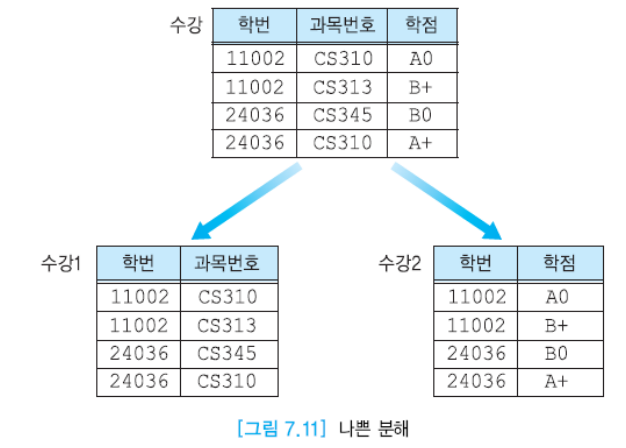
조인 연산을 한다면 각 학번마다 4개의 튜플이 만들어지기에 원래 없던 가짜 튜플이 등장하게 된다. 논리적으로 의미가 없는 학번, 학점을 연계해서 릴레이션을 만들고자 했기에 문제가 발생한다.
4. 제1정규형, 제2정규형, 제3정규형, BCNF
1) 제1정규형
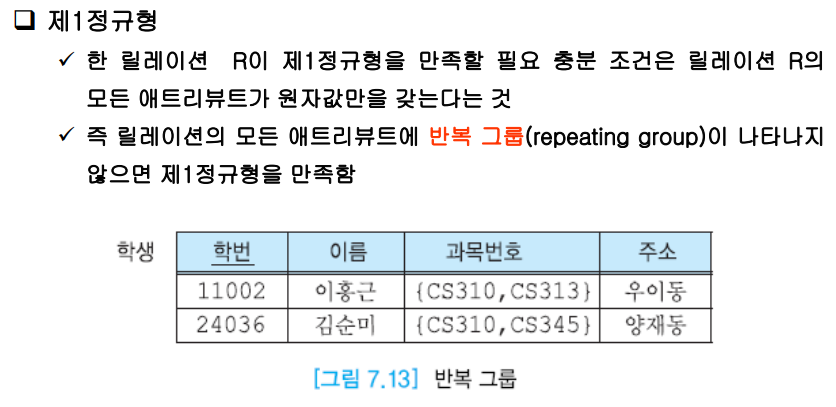
모든 어트리뷰트가 원자값을 가진다. 위의 릴레이션은 과목번호가 여러 개있기에 이는 반복그룹이라한다.
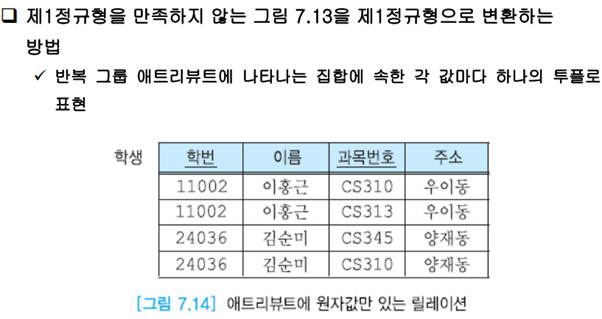
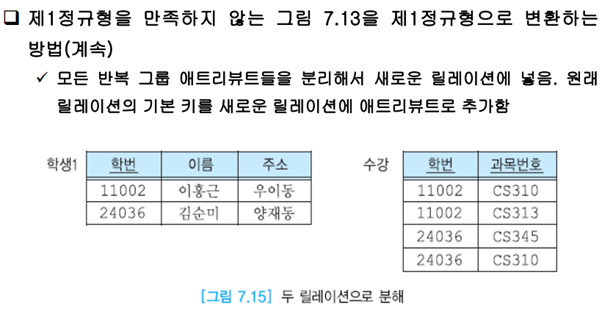
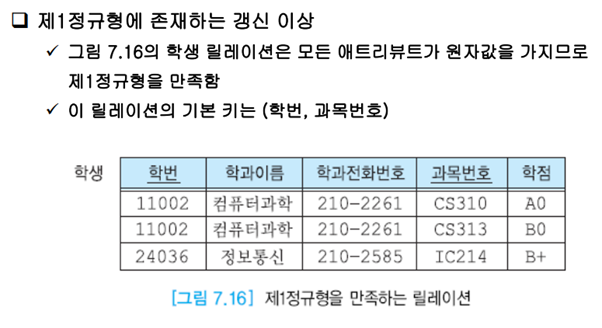
갱신이상이 아직 발생한다.
수정 이상: 학과의 전화번호가 바뀌었을 때 이를 반영할 수 없다.
삽입 이상: 학과가 신설되면 이를 삽입할 수 없다.
삭제 이상: 24036의 학번이 삭제되면 정보통신학과가 릴레이션에서 사라진다.

갱신 이상이 생기는 이유
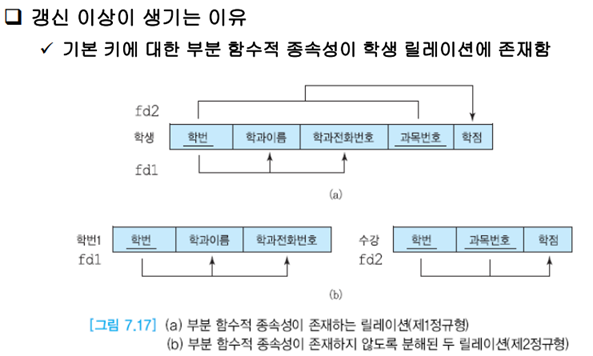
한 릴레이션에서 부분 함수적 종속성이 존재하기 때문에 갱신 이상이 생긴다.
2) 제2정규형

기본키에 완전하게 함수적으로 종속하도록 릴레이션을 분할한다. 즉, 부분 함수적 종속성이 있는 것만 떼어서 따로 릴레이션을 만든다.
후보키의 어트리뷰트는 완전 함수적 종속적이지 않아도 된다.
제2정규형에 존재하는 갱신 이상
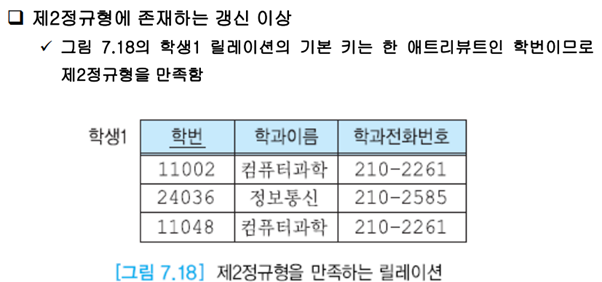

여전히 위에서 봤던 문제가 발생하게 된다. 이는 이행 함수적 종속성이 있기 때문이다.
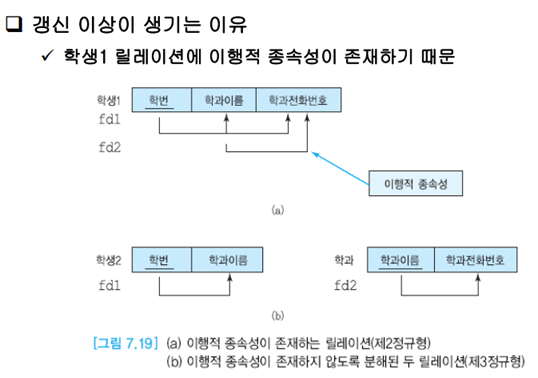
학번 -> 학과이름, 학과 전화번호
학과 이름 -> 학과 전화번호
이행적 종속성이 나타난다. 이에 따라 이행적 종속성이 나타나는 것을 분해한다.
이행적 종속성이 여러 번 나타나면 이를 계속적으로 분해해야한다.
3) 제3정규형

이행적 종속성을 없앤 것이다.
제3정규형에서 존재하는 갱신이상

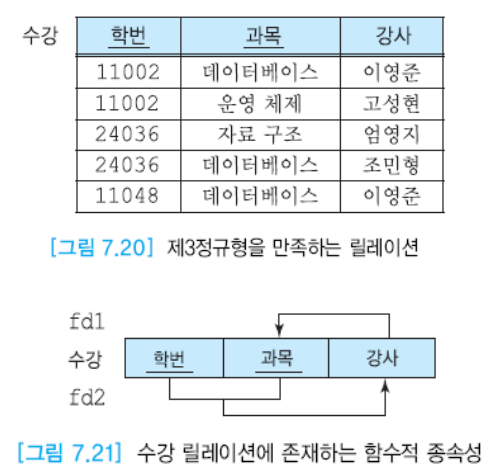
완전 함수적 종속성을 만족하고, 이행적 종속성은 없다.
강사는 과목 키의 일부분을 결정한다. 이러한 경우에 갱신이상이 발생할 수 있다. 따라서 강사와 과목의 중복이 있다.

데이터베이스 강사의 이름을 변경했을 때 불일치 문제가 발생할 수 있다.

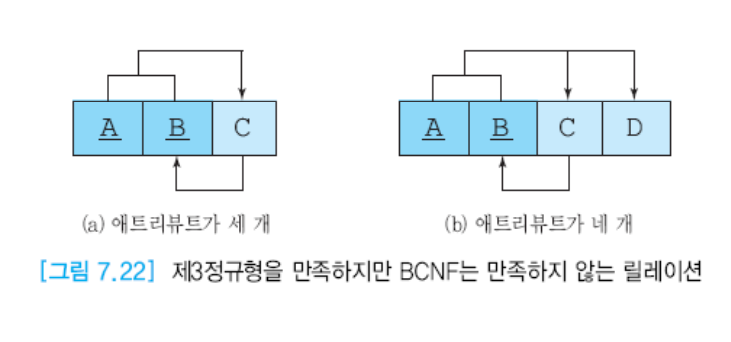
4) BCNF

모든 결정자가 후보키여야한다.
BCNF로 분해
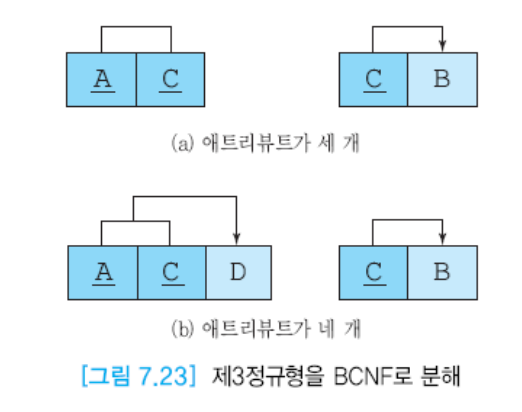
(a) C를 분해한다.
(b) C를 분해한다.
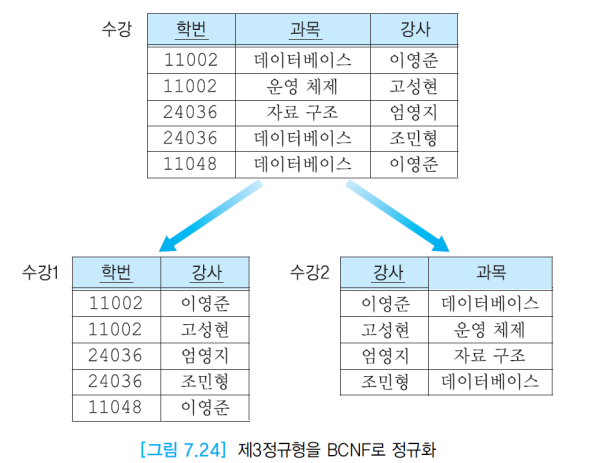
중복을 해결한다.
여러 정규형의 요약
5. 역정규화
1) 정규화의 장점과 단점

(1) 정규화의 장점
중복이 감소하여 갱신 이상이 감소된다.
무결성 제약조건을 시행하기 위한 코드 양이 줄어든다.
(2) 정규화의 단점
원래의 릴레이션을 만들기 위해 비용이 많이 들어가는 조인 연산을 수행해야한다. 따라서 질의 처리 속도가 느려진다.

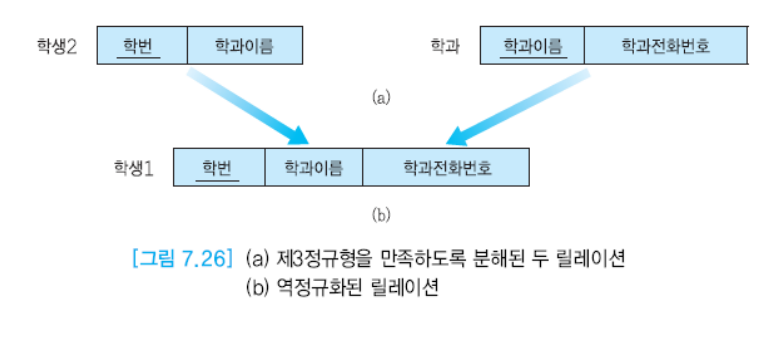
2) 역정규화
조인이 많은 경우에는 주어진 요구사항을 준수하지 못할 수 있다. 이러한 경우에는 빠르게 처리하기 위해 역정규화를 수행한다. 분해한 것을 돌려서 분해하기 이전의 릴레이션으로 만드는 것을 의미한다.

갱신이상이 발생할 수 있다.
'강의 내용 정리 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스(12), 뷰와 시스템 카탈로그 (0) | 2023.01.31 |
|---|---|
| 데이터베이스(11), 함수적 종속성과 정규화 (0) | 2022.12.25 |
| 데이터베이스(9), 물리적 데이터베이스 설계 (1) | 2022.12.14 |
| 데이터베이스(8), 데이터베이스 설계와 ER 모델 (1) | 2022.12.13 |
| 데이터베이스(7), 내포된 SQL (0) | 2022.10.25 |