2023. 2. 5. 22:46ㆍ강의 내용 정리/데이터베이스
트랜잭션
1. 트랜잭션 개요
1) 개념
(1) 동시성 제어와 회복

대규모 데이터베이스를 수많은 사람들이 액세스하기에 동시에 동일한 부분이나 다른 부분을 액세스할 수 있다. 하지만 동일한 부분을 액세스하는 경우에는 문제가 야기될 수 있다.(race condition)
따라서 문제가 발생하는 것을 방지하기 위해 동시성 제어를 해야한다. 제대로 수행되는 것은 여러 개가 순차적으로 사용되는 결과와 동시에 수행된 결과는 동일해야한다.
회복은 데이터베이스를 사용하면서 여러 fail이 있을 수 있다. 예를 들면 전원이 나가는 경우가 이에 해당할 수 있다. 제대로 끝나지 않는 경우에는 이를 일관된 상태로 되돌려줘야한다. 즉, 수행되다가 멈추면 수행되기 전 상태로 되돌려줘야한다. 또한 끝났다고 선언한 것은 제대로 끝난 상태를 보장해야한다.
(2) 트랜잭션

논리적인 단위는 all or nothing이다. 모두 수행하거나 하나도 수행되지 않는 것을 의미한다.
(3) 응용 예시


- 320명까지만 업데이트를 하고, 중단되면 일관성이 없어지게 된다. 나중에 일관된 상태로 만들기 위해서는 업데이트된 사원들의 급여를 원래대로 돌려주고 처음부터 질의를 수행해야한다. 그러니 누가 업데이트되고 안됐는지 파악하기 위해 갱신 연산을 수행할 때 로그를 유지한다. 그 로그 내에는 로그 레코드들이 있다.


첫번째 업데이트문을 수행하고, 두번째 업데이트문을 수행하기 전에 다운되면 일관된 상태를 유지할 수 없다. 따라서 두 개의 연산은 논리적으로 함께 수행되어야하기에 이 두 개를 모두 합쳐서 하나의 트랜잭션으로 구성한다.
BEGIN TRANSACTION
...
COMMIT WORK
END가 아니다.



DBMS는 커밋이 되지 않으면 성공적으로 문장을 수행하지 않은 것으로 간주한다. 즉, 3번 이후에 에러가 발생해도 이를 처리하지 않는다. 커밋을 하지 않으면 메인 메모리에만 반영되고, 디스크에는 반영이 안되기 때문이다.
2) 트랜잭션의 특징
(1) 원자성

모든 연산을 수행하거나 전혀 수행하지 않는다.
(2) 일관성

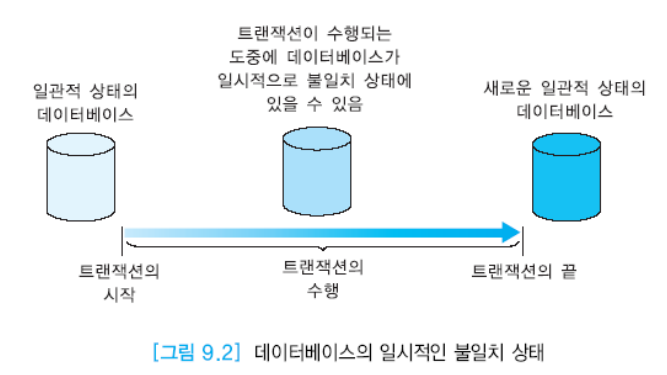
트랜잭션은 일관된 상태의 데이터베이스에서만 수행가능하고, 일관된 상태의 데이터베이스를 만들어내야한다. 즉, 일관성이 유지되어야한다.
트랜잭션이 수행되는 도중에 데이터베이스의 일관성은 깨질 수 있다. 하지만 트랜잭션이 끝나면서 일관성이 유지된다.
(3) 고립성

트랜잭션을 통해 데이터를 갱신하는 동안 하나의 트랜잭션이 독립적으로 수행된 것과 같이 수행되어야한다. 즉, 동시에 여러 트랜잭션을 수행하더라도 하나의 트랜잭션만 수행하는 것처럼 수행해야한다.
완전히 혼자 수행되면 완전한 고립성을 보장하지만 동시성이 매우 떨어진다. 따라서 동시성을 높이기 위해 고립수준을 trade off하게 된다. 응용프로그램이 감내할 수 있는 정도를 고려해 고립수준을 설정한다.
cf) 동시성: 동시에 수행될 수 있는 트랜잭션 개수
(4) 지속성

위의서의 완료: 커밋을 의미한다.

무결성 제약조건을 만족하는 상태가 일관성이 있는 상태가 된다.
3) 트랜잭션의 완료와 철회



중간에 문제가 발생하면 롤백한다. 사용자의 트랜잭션 프로그램 관점에서는 논리적인 오류가 있거나 할 때 롤백이라 하는 상태에 대해 직접 명령을 내린다. DBMS 내부 관점에서는 롤백을 하지 않았지만 일부 수행되고 다운되었다면 내부적으로 지금까지 수행한 일을 롤백하기도 한다.
트랜잭션이 성공하지 못하는 원인

2. 동시성 제어
1) 동시성 제어란

컴퓨터의 발전은 배치 시스템 -> 멀티 프로그램으로 바뀌었다. 이에 따라 프로그램을 동시에 수행하게 된다. response time을 빠르게 하고, i/o bound 시스템을 기다리지 않아도 되기에 시스템의 성능을 높일 수 있다.
하지만 race condition과 같은 상황을 방지하기 위해 동시성 제어를 해야한다.

다양한 명령어를 사용하는 사용자가 동시에 접근할 수 있다.
2) 스케줄

(1) 직렬 스케줄
트랜잭션을 하나씩 수행하는 것은 직렬 스케줄이다. 이는 n개의 트랜잭션에 대해 n!만큼의 직렬 스케줄이 가능하게 된다.
(2) 비직렬 스케줄
서로 다른 트랜잭션에 해당하는 것들이 섞여서 수행된다.
ex) Oij는 Ti의 j번째 연산일 때, O21 O11 O31 O22 O23 O12 O32 .... 과 같이 연산이 섞여서 수행될 수 있다.
비직렬 스케줄의 경우의 수는 각 트랜잭션 내의 연산 순서를 지켜야하기에 다음과 같다.
(n은 한 트랜잭션의 연산 횟수)
n1 + n2 + n3 => (n1+n2+n3)! / n1!n2!n3!
(3) 직렬가능
ex) T2, T1, T3가 각각 O11, O12, O13, O21 O22 O31 O32라고 할 때, 이 결과가 어떤 직렬 스케줄의 결과와 동일하면 직렬가능이다.
하지만 수행하는 순서 상에는 옳지 않음에도 불구하고, 우연히 현재 데이터 베이스 인스턴스에 대해서만 올바른 결과가 되었을 때 이를 직렬가능으로 판단하면 안된다. 이는 result equivalence라고 한다. 따라서 동등성에 대해 고려했을 떄 conflict equivalence라고 한다. 다른 트랜잭션에 속한 연산들 가운데 동일한 데이터에 대해 write하거나 읽는 연산이 여러 개 있을 때 conflict operation이 있다고 한다. 따라서 두 개의 스케줄 상에서 conflict operation의 순서가 동일하면 conflict equivalence라고 한다.
예를 들어 O21 O11이 동일한 데이터를 읽는다고 했을 때 O21이 O11보다 먼저 수행되어야한다. 이에 따라 이 순서를 보장하는 것을 conflict equivalence라고 한다. 즉, conflict operation의 순서를 유지해야한다.
또한 View 동등성도 있다. 두 트랜잭션이 값을 읽고 최종적으로 같은 것을 써야한다는 의미이다.
3) 데이터베이스 연산

주기억 장치 버퍼가 메모리가 된다. 직접 디스크에서 데이터를 읽고 쓸 수 없기에 메모리를 거쳐서 이를 처리한다. 데이터 item을 포함하고 있는 블록을 주기억장치로 가져오는 연산이 input이다.
output은 메모리에서 디스크로 저장하는 것을 의미한다.
read_x는 응용 프로그램으로 복사하는 것을 의미한다.
write_x는 응용 프로그램에서 메모리에 작성하는 것을 의밈한다.

4) 동시성 제어를 하지 않을 때 발생할 수 있는 문제

(1) 갱신 손실
현재 수행 중인 트랜잭션이 갱신한 내용이 다른 트랜잭션이 덮어서 갱신이 없어지는 것을 의미한다.
(2) 오손 데이터 읽기
완료되지 않은 트랜잭션이 갱신한 데이터를 읽는 것이다. 트랜잭션 중간은 일관되지 않은 상태일 수 있기에 완료되지 않은 트랜잭션이 쓴 내용은 다른 트랜잭션이 읽으면 안된다.
(3) 반복할 수 없는 읽기
한 트랜잭션이 동일한 데이터를 두 번 이상 읽을 때 같은 값이 아닌 다른 값이 읽히는 것을 의미한다.
고립성은 한 트랜잭션이 수행될 때에는 그 트랜잭션만 수행되는 것처럼 보여야한다는 것을 의미한다. 하지만 한 트랜잭션 내에서 다른 값이 나온다면 이는 고립성을 보장하지 못한 것이다.


write_item을 했을 때 데이터 베이스의 값이 바뀐다. 트랜잭션 1에서 write해서 20만을 썼던 x 값이 사라지게 된다.


롤백되기 이전 데이터를 읽어서 T2는 잘못된 값을 커밋하게 된다.


T2은 두번 읽는 연산을 했지만 동일한 값이 검색되지 않는 문제가 발생한다.
(4) 여행사 예시


한 좌석을 두 고객에게 배정을 하게 된다. 따라서 적절한 동시성 제어를 해야한다.
5) 로킹(locking)

동시성 제어 테크닉이다. 가장 널리 사용하는 방법이다. 따라서 트랜잭션에서 데이터 항목에 접근할 때 로크를 요청해서 로크를 획득한 뒤, 이를 진행한다. 만약 다른 트랜잭션이 로크를 가지고 있으면 기다려야한다.
(1) 독점 로크(X-lock, exclusive lock)
어느 순간에 하나의 트랜잭션만이 그 lock을 가질 수 있다. -> 갱신 목적일 경우에 사용한다.
(2) 공유 로크(S-lock, Shared lock)
읽기 연산을 수행할 때에는 여러 트랜잭션의 접근을 허용한다. 공유 로크를 사용하는 경우에는 쓰기 연산을 못하게 한다.
(3) 로크 양립성 행렬

공유 로크를 할 때에는 쓰기 연산을 하는 트랜잭션들은 읽을 수 있다.
(4) 예제: 로크를 일찍 해제

트랜잭션은 고립성을 보장해야한다. 하지만 T1이 수행되다가 중간에 T2가 수행된다. 이에 따라 T1이 B의 값을 갱신할 때 T2가 먼저 갱신하기에 값이 달라지게 된다. 따라서 갱신 손실이 발생한다. 또한 중간에 처리한 값을 읽어오기 때문에 오손데이터 읽기가 발생한다.
직렬 스케줄인 경우에는 T1 - > T2나 T2 -> T1이 수행되어야한다. 하지만 위의 예시는 최종 결과가 같지 않게 된다.
즉, 데이터를 읽고 쓰는 것에 대해서만 lock을 거는 것은 크게 의미가 없다는 것을 의미한다. 이를 해결하기 위해 2단계 로킹 프로토콜이 등장한다.
(5) 2단계 로킹 프로토콜(2-phase locking protocol)

lock을 요청하는 단계에서는 요청만하고 해제하는 단계에서는 해제만 해야한다.

로크 확장 단계(1단계)
로크를 요청하는 단계이다. 데드락은 해당 단계에서 발생한다.
로크 수축 단계(2단계)
로크를 해제하는 단계
cf) 로크 포인트: 로크가 최대로 걸려있는 시점

로크를 조금씩 해제하는 것과 로크를 한꺼번에 해제하는 방법이 있다. BEGIN과 END는 트랜잭션 수행 시점과 커밋을 의미한다. 로크를 한꺼번에 해제하는 방법에서는 로크 포인트 이후에 조금 시간이 지난 뒤에 해제한다.
로크를 조금씩 해제하는 것은 동시성을 높일 수 있어서 유리하다. 하지만 오손 데이터 읽기가 발생할 수 있다. 일반적인 경우에는 괜찮지만 수축 단계의 중간에서 abort가 발생하면 오손 데이터 읽기 문제가 발생할 수 있다. 이에 따라 일반적으로는 오른쪽에 있는 것처럼 로크를 한꺼번에 해제한다.
(6) 데드락

두 개 이상의 트랜잭션이 서로 상대방의 로크를 요청하면서 기다리는 상태를 의미한다.

데드락의 예는 로크 요청 그래프라고 한다. 트랜잭션을 의미하는 노드와 데이터를 의미하는 노드로 나눠진다.
데드락이 발생했는지 여부를 파악해야한다. 만약 그래프에서 사이클이 존재하면 데드락이 존재하는 것을 의미한다. 이러한 사이클이 존재하는지 파악하기 위해 DBMS는 주기적으로 검사한다.
데드락을 해제하기 위해서 기본적으로 수행한 연산이 적은 트랜잭션을 골라서 abort시키면 된다.
(7) 다중 로크 단위(multiple granularity)

로크를 할 수 있는 데이터 항목의 단위를 의미하며 이는 데이터베이스, 릴레이션, 디스크 블록, 튜플 등이 되겠다.

multiple granularity가 크면 동시성이 떨어지고, 작으면 동시성이 커진다. 단위가 커지면 로크의 개수를 줄일 수 있기에 리소스를 적게 사용할 수 있게 된다. 만약 릴레이션 5개를 사용한다면 5개를 로크로 걸어야하지만 데이터베이스만 걸면 하나의 로크만 걸 수 있게 된다. 또한 시간적인 오버헤드를 줄일 수 있게된다.
(8) 다중 단위 로크 예시

블록 단위 로크를 걸면 동시에 수행될 수 없지만 튜플 단위 로크를 걸면 동시에 수행될 수 있다.

두번째 예제는 서로 다른 단위의 로크를 사용하는 경우를 가정하는 것이다. T1은 블록에 대한 로크이고, T2는 튜플에 대한 로크이다. 따라서 위계를 잘 고려해서 다중 단위 로크를 허용해야한다.
이를 처리해주기 위해서 Intension lock을 도입해서 자식에 X lock을 걸면 조상에게 intension lock을 걸어준다. 이에 따라 자손에 락이 있는지 여부를 판단할 수 있다. 자식 노드에서 lock을 걸기 전에는 조상 노드에 lock이 걸려있는지 확인한다.
(9) 팬텀 문제

동시성 제어를 하지 못함에 따른 또 다른 문제


두번 읽을 때 읽는 값에 대한 차이가 있다. 이는 반복할 수 없는 읽기와 유사하다. 챕터 마지막쯤에 나오는 얘기이다.
3. 회복
1) 회복의 필요성

2) 회복 개요

버퍼에 write를 하고 메모리에 바로 저장하지 않고, 버퍼 정책이 바뀌었을 때 이를 모아서 저장한다. 모아서 한번에 write하는 경우에 성능을 더 높일 수 있기 때문이다. 트랜잭션이 버퍼에는 갱신 사항을 반영했지만 디스크에 기록되기 전에 고장날 수 있게 된다.

REDO와 UNDO를 통해 회복을 구현한다.
3) 저장 장치의 유형

안전 저장 장치는 스토리지는 고장이 안난다는 것을 가정한 가상의 스토리지이다. 스토리지는 고장이 날 수 있지만 안나는 것처럼 시물레이션을 할 수 있다. 만약 한 스토리지의 고장 확률이 0.1%라면 두 개의 스토리지를 똑같이 카피해서 유지한다면 고장이 안난다고 가정할 수 있다.
4) 고장의 유형

(1) 재해적 고장
데이터베이스 백업을 통해 회복할 수 있다.
(2) 비재해적 고장
대부분의 회복 알고리즘은 이를 어떻게 해결할 것인가에 초점을 둔다.
5) 로그
(1) 로그를 사용한 즉시 갱신

로그도 로그 버퍼를 사용한다. 로그 레코드 하나 쓸 때마다 이를 기록하는 것이 아니라 버퍼가 꽉차면 로그를 기록한다. 이 또한 회복에 필수적이기에 안전 저장 장치에 저장된다.


연결 리스트로 유지된다는 의미는 실제로 물리적으로 연결되었다기 보단 하나를 찾으면 연쇄적으로 찾을 수 있다는 점에서 논리적으로 연결 리스트로 연결되었다는 것을 의미한다.
(2) 로그 레코드의 유형

두번째 로그에서 이전 값도 가지고 있는 이유는 redo를 해야할 수도 있기 때문이다.
old value: undo시 사용
new value: redo할 때 사용
위의 예시는 물리적 로그 레코드이다. 하지만 논리적 로그 레코드도 있을 수 있다.
ex) [Trans-ID, Add, x, value]: 이는 논리적 로그 레코드이다. 값을 더하고 뺀다는 의미이다.
예시


write를 할 때 로그 레코드로 남게 된다. 이에 따라 2번째에 [T1, B, 300, 400]이 기록된다.
시작할 때에는 start, 끝났을 때에는 commit을 기록하여 저장한다.
(3) 트랜잭션의 완료점(commit point)

한 트랜잭션의 데이터베이스 갱신 연산이 모두 끝나고 데이터베이스 갱신 사항이 로그에 기록되었을 때 회복을 한다면 영구히 DB에 반영할지, undo를 할지는 commit 로그 레코드가 결정하게 된다. 즉, 트랜잭션이 커밋했는지 안했는지를 나타내는 포인트는 commit 레코드를 기록한 시점이 된다. 따라서 커밋 메세지가 뜨지 않더라도 commit 레코드가 기록된다면 성공적으로 커밋이 된 것이다.


(4) 재수행할 트랜잭션과 취소할 트랜잭션

i = 0은 로그가 아무것도 없기 때문에 작업을 할 필요가 없다.
i = 1는 [T1, start]를 한 메세지를 의미한다.
(5) 로그 먼저 쓰기[WAL: Write-Ahead Logging]

데이터 베이스 버퍼보다 로그 버퍼를 먼저 디스크에 기록해야한다.

이 규약을 지켜주는 것이 매우 중요하다. 로그는 무한대 크기의 파일로 가정할 수 있다. 로그에 write을 할 때엔 메인 메모리에서 로그 버퍼를 사용한다. 하지만 메인 메모리는 무한대의 크기가 아니다. 따라서 로그 버퍼를 유지하기 위해서 링(circular queue)형태의 버퍼를 사용한다. 이를 통해 무한대인 것처럼의 효과를 가지게 된다. 링 형태의 로그 버퍼가 꽉차게되면 disk(logfile)에 flush해서 공간을 확보한다.
LSN(로그 시퀀스 넘버)로 로그 파일을 식별할 수 있다. 로그 버퍼에 flushLSN이 있다. 이는 마지막으로 flush된 로그의 LSN을 의미한다.
메인 메모리에는 로그 버퍼와 DB 버퍼가 존재하게 된다. 디스크에도 로그 파일이 있고, DB가 존재하게 된다. DB에 로그 파일이 포함되어있다.
77이 88로 바뀐 로그가 LSN800이다. 이때 P2가 새로 액세스 된 상황이면 버퍼에 있는 내용을 flush한다. 이때 마지막으로 flush된 로그의 LSN은 750이 된다면 실질적으로 77이 88로 바뀐 로그가 DB에 반영되지 않았다. 따라서 로그 버퍼에는 77이 88에 저장이 되지만 디스크에 저장이 되지 않았다. 이 상황에서 고장이 난다면 이는 디스크에 반영되지 않는 문제가 발생한다. 이를 해결하기 위해 WAL을 사용한다. 즉, DB 버퍼를 write 하기 전에 DB 버퍼의 갱신 연산을 포함하는 로그들을 먼저 로그 파일에 기록해서 위의 문제를 해결한다.
pageLSN: DB 페이지에서 가장 마지막을 갱신된 연산의 LSN을 의미한다. 이를 통해 갱신된 연산과 갱신되지 않은 연산을 구분한다. 만약 flush LSN이 page LSN보다 작은 경우에는 갱신 연산에 대한 로그 레코드 중 디스크에 flush되지 않은 것이 있다는 것을 의미한다. 따라서 로그버퍼가 꽉 찼을 때 page LSN은 최소 flush LSN만큼은 flush해야한다.
위의 상황은 로그 버퍼가 꽉 찬 상황을 가정한 것이다. 또한 트랜잭션을 커밋할 때에도 로그 버퍼에 있는 내용을 디스크에 반영해야한다.
6) 체크 포인트 필요성

시스템이 고장난 상황이라면 철회할 트랜잭션과 재수행할 트랜잭션을 구분해야한다. 고장이 날 때마다 모든 로그를 다 보는 것은 비효율적이기에 체크포인트를 체크하여 그 시점이후부터 로그를 보며 회복을 진행하는 것이 효율적이다. 체크포인트는 시스템이 정상적으로 동작하는 중간중간에 체크한다.
(1) 체크포인트를 할 때 수행되는 작업

수행중인 트랜잭션을 일시적으로 중지시킨다. 이후 로그 버퍼를 출력한 뒤에 데이터베이스 버퍼를 디스크에 강제로 출력하면서 WAL 규칙을 지킨다.
체크 포인트 시점에 수행중이던 트랜잭션은 active transaction이라 얘기한다. 이를 체크포인트 로그 레코드에 함께 기록한다. 하지만 이를 수행한다면 중간에 트랜잭션이 중지하기에 은행같은 곳에서는 사용하기 어렵다. 이를 해결하기 위해 fuzzy checkpoint를 도입하기도 했다. 이는 시스템을 중단하지 않고 체크포인트를 만드는 기술을 의미한다.
예제


체크포인트가 있다면 active transaction인 T2, T4가 체크포인트 로그 레코드에 함께 기록되고, 이를 포함해서 재수행 혹은 취소를 하게 된다.
7) 데이터베이스 백업과 재해적 고장으로부터의 회복

재해적 고장으로부터는 회복이 아닌 백업을 하는 경우가 더 많다. 이때에는 incremental backup을 하게 된다. 전체를 백업하는 것이 아니라 지난 백업 이후로 갱신된 내용만 백업을 하는 것을 의미한다. 이는 복잡하기 때문에 매일 점진적으로, 가끔 한번에 백업을 하는 식으로 진행된다.
4. PL/SQL의 트랜잭션
1) 트랜잭션의 시작과 끝

오라클에서 트랜잭션은 커밋을 보내는 것처럼 명시적으로 끝날 수 있고, 묵시적으로 끝날수도 있다. 하나의 쿼리문을 하나의 트랜잭션으로 간주할 수도 있다. 이는 묵시적으로 트랜잭션을 끝내는 것이다.

SAVEPOINT문은 트랜잭션의 중간 지점으로 되돌릴 수 있도록 마크하는 것을 의미한다.

ROLLBACK을 하면 하나의 트랜잭션을 취소하게 된다.

2) 트랜잭션의 속성

트랜잭션이 읽기만 사용한다면 이를 읽기 전용임을 명시해 동시성을 높일 수 있다.
만약 읽기 전용에 대한 트랜잭션에서 update 연산을 사용한다면 이는 허용되지 않는다.

3) 고립 수준

하나의 트랜잭션이 다른 트랜잭션과 고립되어야하는 정도를 의미한다. 고립수준이 높으면 정확성은 높아지지만 동시성이 저하된다. 고립수준이 낮으면 다른 트랜잭션의 영향을 받겠다는 의미이기에 정확성이 떨어질 수 있다. 하지만 동시성을 올려줄 수 있게 된다. 이에 따라 시스템 성능이 증가하게 된다. 만약 정확하지 않고 러프하게 값을 구해야할 때에는 고립성을 떨어트릴 수 있다. 트랜잭션의 고립 수준은 트랜잭션마다 설정하기에 본인 트랜잭션에만 영향을 미치고 다른 트랜잭션에는 영향을 미치지 않기 때문에 위처럼 러프하게 사용하더라도 상관없다.
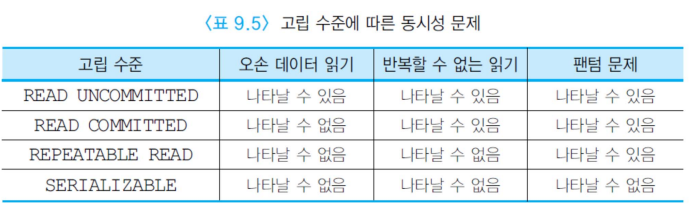
(1) READ_UNCOMMITED
가장 낮은 고립 수준

오손 데이터 읽기가 발생할 수 있다. 이를 사용한다면 공유 로크를 걸지 않고 데이터를 읽어들인다. 따라서 다른 트랜잭션이 락을 걸든말든 데이터를 읽을 수 있다. 그러나 갱신 트랜잭션의 경우에는 락을 걸어야한다. 이는 읽기 연산에 대해서만 처리한다.
(2) READ_COMMITED

질의들이 읽으려는 데이터에 대해 공유 로크를 걸고, 읽기가 끝나자마자 로크를 해제한다. 따라서 이는 반복할 수 없는 읽기의 문제가 발생할 수 있다.
(3) REPEATABLE READ

서치하는 데이터에 대한 공유 로크를 걸고, 트랜잭션이 끝날 때까지 보유한다. 하지만 만약 다른 트랜잭션이 서치레인지에 포함되는 데이터를 삽입하는 경우에는 새로운 튜플이 갑자기 보이기 때문에 Repeatable read에서는 Phantom problem이 발생한다.

이를 해결하기 위해 서치 레인지에 대한 로크를 걸면 된다. 하지만 서치 레인지에 대해 로크를 걸기가 어렵기 떄문에 인덱스에 로크를 걸어서 사용한다. 인덱스에서 next-key value 로킹을 사용한다. 이를 반영한 것이 SERIALIZABLE이다.
(4) SERIALIZABLE
가장 높은 고립 수준

질의에서 검색되는 튜플뿐만 아니라 인덱스에 대해서도 공유 로크를 걸고 트랜잭션이 끝날 떄까지 보유한다.
한 트랜잭션 내에서 동일한 질의를 두 번 이상 수행할 때 매번 같은 결과가 나오는 것을 보장한다는 점에서 REPEATABLE READ와는 차이가 있다.
'강의 내용 정리 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스(14), 데이터베이스 보안과 권한 관리 (0) | 2023.02.08 |
|---|---|
| 데이터베이스(12), 뷰와 시스템 카탈로그 (0) | 2023.01.31 |
| 데이터베이스(11), 함수적 종속성과 정규화 (0) | 2022.12.25 |
| 데이터베이스(10), 릴레이션 정규화 (0) | 2022.12.20 |
| 데이터베이스(9), 물리적 데이터베이스 설계 (1) | 2022.12.14 |