2020. 12. 31. 19:56ㆍEnglish/Machine learning algorithm
The optimization target for SVMs is to maximize margins.
Margin: The distance between the superplane (decision boundary) that separates the class and the training sample closest to this superplane.
* Decision Boundary: Boundary that separates classes
The decision boundaries of large margins tend to reduce generalization error. On the other hand, the decision boundaries of small margins are likely to be overfitting. Therefore, the objective of optimization is to ensure that the distance between the boundaries that differentiate the class and the training samples that are closest to this boundary is remote. In other words, it is the SVM's role to find boundaries that can distinguish classes well.
Superelevation plane placed alongside decision boundaries
(1) Decision Boundary \(W^t X = 0\)
(2) Superelevation on the positive sample side \(W^T X_{pos} = 1\)
(3) Superelevation on the negative sample side \(W^T X_{neg} = -1\)
Subtract (2) from (1) gives the following results:
$$ W^T(X_{pos} - X_{neg}) = 2 $$
The above expression can be normalized by the distance of Eucladians of W.
$$ ||w|| = \sqrt{\sum_{j=1}^{m} {w_{j}}^2} $$
$$ \frac{W^T(X_{pos} - X_{neg})}{||w||} = \frac{2}{||w||}$$
**Considering the distance formula between a straight line and a point, the left side of the equation can be interpreted as the distance between the positive and negative hyperplane. This is the margin that is trying to maximize. Thus, the objective function of SVMs is to maximize the margin by maximizing\(\frac{2}{||w||}\)
* Distance between straight lines and points:: \( d = \frac{ax_0 + by_0 + c}{\sqrt{a^2 + b^2}} \)
** Assuming a = b, c = 0 in the expression above, the distance between the hyperplanes will be easily understood.
Constraint
(1) \( W^tX^{(i)} \ge 1 \) When \( y^{(i)} = 1 \)
(2) \( W^tX^{(i)} \le -1 \) When \( y^{(i)} = -1 \)
i = Number of samples from 1 to N
The constraint of (1) is required to be classified as a positive sample because it must be greater than \( W^tX^{(i)} = 1 \)
The constraint of (2) is required to be classified as a negative sample because it must be less than \( W^tX^{(i)} = -1 \)
Therefore, the objective function of the SVM is to maximize the margin under the above constraints. The above classification is also referred to as hard margin classification.
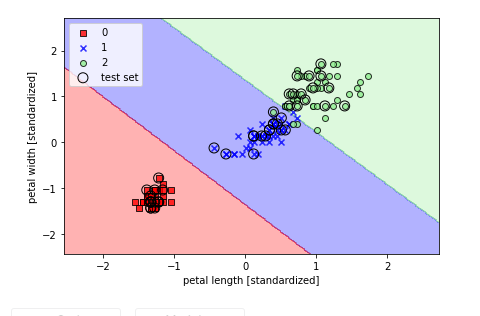
Soft margin classification
- Classifying linearly non-separable data at the expense of appropriate costs
- To this end, we add the slack variable \( xi\) to the constraints above.
(1) \( W^tX^{(i)} \ge 1 - \xi \) When \( y^{(i)} = 1 \)
(2) \( W^tX^{(i)} \le -1 + \xi \) When \( y^{(i)} = -1 \)
i = Number of samples from 1 to N
Under the above constraints, the objective function to be minimized can be defined as follows:
$$ \frac{1}{2}||w||^2 + C \sum_i \xi^{(i)} $$
Variable C allows the cost to be adjusted for the classification error. Increasing the C value increases the cost of error.
'English > Machine learning algorithm' 카테고리의 다른 글
| [6] Information gain and impurity of decision tree (0) | 2021.01.06 |
|---|---|
| [5] Non-linear Troubleshooting with Kernel SVM (0) | 2021.01.04 |
| [3] Logistic Regression Principles (0) | 2020.12.31 |
| [2] Implement Adaline (adaptive linear neuron) (0) | 2020.12.31 |
| [1] Try implementing Perceptron (0) | 2020.12.31 |